
@יוסף-חיים-016
האינטרס לא לעשות זה לשמור על צביון ששונה מאוד ממה שאתה מכיר במקומות אחרים.
אם אתה לא מבין, לא נורא. בשביל זה יש אחרים.
dovid
@dovid
-
צ'אט בפורום -
אני צריך מישהו שיפרוץ למייל ששכחתי את הסיסמה שלו בתשלום דחוף -
Regex - ביטויים רגולרייםטקסט תמיד מורכב מאוסף של תווים, וביטוי רגולרי בא בהגדרתו למצוא רצף של כאלה תואם למה שביקשנו.
הביטוי עשוי לכלול אותיות רגילות לגמרי. למשל ביטוי כזה 'א' ימצא את כל אותיות הא' בטקסט בו מחפשים. כמו"כ הביטוי 'אני' יחפש את המילה אני או ליתר הדיוק את הרצף של האותיות א' נ' י'. עד כאן זה בעצם התנהגות של חיפוש רגיל ומוכר.
אבל, עיקר הכח של הביטוי הרגולרי בא מתווים/סימנים מיוחדים. נסקור את העיקריים שבהם, לפי סוג.
ג'וקרים
נתחיל מהפשוט: אנחנו רוצים למצוא תו כל שהוא (נקודה), תו כל שהוא אבל רק מתוך קבוצת תוים (סוגריים מרובעות [XYZ]), או תו כל שהוא למעט קבוצה מוחרגת (סוגריים מרובעות עם חץ למעלה בהתחלה [^XYZ]). נקרא לזה ג'וקרים,
שימו לב, כל הג'וקרים מייצגים תו בודד בלבד!
(כל התוים המיוחדים יוצרים בעיה, מה קורה כשרוצים לחפש תו פשוט שלרוע מזלו הינו מיוחד מבחינת הregex? צריך לבטל את ייחודיותו ע"י escaping נדבר על זה בהמשך).. נקודה - תו אחד כל שהוא
נקודה בביטוי רגולרי לא מייצגת את התו נקודה אלא היא סימן מיוחד, שמשמעותו "מתאים לי שתמצא איזה תו שתרצה". חיפוש של ביטוי רגולרי עם נקודה בלבד, יחזיר את כל התוים בטקסט (מס' התוצאות יהיה מס' התוים בטקסט הנתון), וזה לא הכי שימושי, אז נגיד דוגמה הגיונית יותר: חיפוש של 'א.' ימצא את כל אותיות הא' שבטקסט עם האות הסמוכה להם, תהיה אשר תהיה. כמו"כ חיפוש של 'א.י' יחזיר רצפים של א', תו כלשהוא, ואח"כ י',
למשל אני, אלי, אוי (ואולי אפילו סיום של מילה בא' עם הרוח שאחריה ותו היוד של תחילת המילה הבאה).[XXX] תו מקבוצה מוגדרת
תו אחד מקבוצה של תווים אפשריים. סוגריים מרובעות ובתוכם תווים, למשל [אהחער] מייצגת תו בודד ובלבד שהוא יהיה אחת מהאותיות (במקרה הזה, הגרוניות..) שבסוגריים. אם נחפש 'ב[אהחער]' זה יחפש אות ב' שאחריה ישנם אחת מהאותיות הללו, למשל בא, בה, בח.
[a-c] טווח: בסוגריים ניתן לכלול טווח תוים. טווח תוים זה אומר מתו עד תו, ללא צורך בהקלדתם בסוגריים. למשל במקום לכתוב [אבגד], ניתן לכתוב [א-ד]. מאיפה מנוע הרגקס יודע את סודות האלפא ביתא וסדרם? זה מתבסס על סדר התוים מבחינת המחשב. (וכמו השאלה בנקודה, אפשר לעשות גם טווחים וגם אותיות בודדות וגם כמה טווחים בסוגריים אחד, למשל [א-גלצ-ת] כולל את האותיות אבגלצקרשת (ומשמעותו 'מצא לי תו בודד שמופיע ברשימה זו').
[^XXX] שלילה
בעוד שראינו שהסוגריים המרובעות מייצגות תו מתוך קבוצה מוגדרת שמופיעה בסוגריים. לפעמים ההגדרה הקצרה ביותר היא הפוכה, תו מתוך כלל התוים בעולם ובלבד שלא יהיה מאלו המוגדרות בסוגריים!
בשביל זה עושים סוגריים שמייד אחרי הפתיחה שלהם מופיע חץ למעלה ^. למשל, [^א-ג] ימצא כל תו למעט א, ב, וג'.תוים מיוחדים יש תוים שאי אפשר להקליד. למשל אם אתם מחפשים קפיצת שורה, או טאב, תכתבו תו מיוחד. למשל קפיצת שורה כותבים ע"י \n ואילו טאב \t יש עוד כמה כאלה. (רווח אפשר לכתוב כפי שהוא בביטוי החיפוש כמו כל אות רגילה).
קיצורים למעשה עם הסוגריים מרובעות אפשר לבטא כל תו שרוצים או שלא, אבל יש חיפושים כ"כ נפוצים שהחליטו לעשות להם קיצור לשיפור השמישות וגם הקריאות. למשל. מספר כל שהוא, ניתן לקבל ע"י [0987654321] או בקיצור ע"י טווח [0-9]. אז קבעו לזה קיצור \d. כלומר לוכסן (הפוך, מהסוג של וינדוס לשימוש בנתיב קבצים) ואחריו אות הd באנגלית, משמשים קיצור ל[0-9] כלומר הם מייצגים תו בודד מ0 עד 9 שניתן להגדיר זאת כמספר כל שהוא. או למשל דוגמא נוספת: לפעמים מחפשים תוי רווח. תוי רווח זה שם כללי לסימנים ה"שקופים" שמפרידים בין מילים - חוץ מהרווח המוכר מהמקלדת, יש את הקפיצת שורה וטאב ועוד כמה. כולם כלולים בקיצור \s.
רשימת הקיצורים:
\d מספר כל שהוא, שקול ל[0-9]
\w תו של מילים, לאפוקי סימני פיסוק וגרוע מכך. קיצור של [a-zA-Z0-9_] (לא יודע למה כללו את הקו התחתי)
\s תו רווח כל שהוא, שקול ל[\r\n\t\f\v] (אל תשאלו אותי מה זה כל אחד...)קיצורי שלילה אם תרצו כל תו שאיננו מספר, אתם תרצו לכתוב משהו כמו [^0-9]. אבל הרי יש לנו \d שמשמעותו [0-9], אז תוכלו לכתוב [^\d]. אבל עליכם לדעת שגם לזה עשו קיצורים... קיצורי השלילה זהים לקיצורים הקודמים רק אות גדולה במקום קטנה, כלומר:
\D כל תו שאיננו מספר
\W כל תו שאיננו תו מילה - "נורמלי".
\S כל תו שאיננו רווח קפיצת שורה טאב וכל החבורה.חזרה וכמות ({}, +, *, ?)
כמה פעמים האלמנט (צריך/יכול) להופיע?
זו קבוצת סימנים, שההגדרה שלה היא "האלמנט (ברוב המקרים התו, לפעמים זה קבוצת תוים עטופה סוגריים) שאמרנו לך לחפש, תמצא אותו ? פעמים". נשמע מסובך... ככה: אם אנו מחפשים מספר כל שהוא, אנחנו כותבים \d או באריכות [0-9]. אבל זה מביא לנו ספרה בודדת. אם נרצה מספר בעל אורך מסויים למשל מס' חשבונית שאנו יודעים שתמיד מכילה 9 ספרות, נצטרך לכתוב ככה \d\d\d\d\d\d\d\d\d ובגריסה הארוכה [0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]. יאהוו.
בשביל זה יש מצייני כמות.{X} או {Y,X} או {,Y} מX עד Y. כלומר האלמנט האחרון שהתבקש, צריך להיות לפחות X פעמים והכי הרבה Y פעמים. למשל, א{2,3} (הסדר הוא קודם המינימום, פסיק מקסימום) יחזיר מקרים בהם יש שתי אותיות א רצופות או שלוש (מקבוצה של ארבע הוא ייקח\יימצא\יתאים רק את השלושה תוים ראשונים). אם אכפת לנו רק המינימום, ואין לנו הגבלה עד כמה, נשמיט את הפסיק והמספר השני. אם להיפך, אנו רוצים גם מספר אחד, אבל לא יעלה על 9, נשמיט את הראשון אך נשאיר אתהפסיק (נכתוב תו לחיפוש, סוגר מסולסל פותח ופסיק, מס' מקסימלי סגירת סוגר מסולסל. האריכות בגלל שיבושי הכיוונים בעברית
") ).
).
שימו לב, כל מצייני הכמות מתייחסים לאלמנט הצמוד שקדם להם. הסימנים הם ?+*{}כוכבית * 0 או יותר. האלמנט האחרון יכול להופיע 0 פעמים (אז הוא גם אופציונלי בעצם) אבל עד אין סוף. חיפוש .* יחזיר פשוט את כל הטקסט כתוצאה אחת - שהרי פירוש הביטוי הוא תו כל שהוא כפול מספר לא ידוע של פעמים. עוד דוגמא א\d* יחזיר כל רצף מספרי שקדם לה האות א' (בהמשך נלמד שכל החיפשוים ברגקס הם חמדניים -לוקחים כמה שיותר. ממילא ממספר של 4 ספרות לא תיהיה התאמה רק של 3 גם אם זה נכון מבחינת כללי החיפוש, כל עוד יכולה להיות התאמה גדולה יותר- של 4).
סימן הפלוס + אחד או יותר. אותו דבר כמו כוכבית, אבל בניגוד אליה, היא מחייבת שהאלמנט יופיע לכל הפחות פעם אחת. בעוד א\d* ימצא גם א שאין אחריו מספר כלל, א\d+ ימצא רק א' שאחריו יש לפחות ספרה בודדת ואילך.
סימן שאלה ? אפס או אחד. זה בעצם אומר שהאלמנט האחרון הוא אופציונלי. אם נרצה לחפש בוקר, בכתיב מלא או חסר, נחפש בו?קר שמשמעותו ב, שאחרי זה תיתכן האות ו ותיתכן שלא ואחרי זה ק'ר'. או שליט"?א ימצא גם שליטא ללא ראשי תיבות. בר ?כל ימצא גם ברכל שהרי הרווח הוא אופציונלי. אם נחשוש שיהיו תוצאות כאלה בר-כל, בר_כל, ניטיב לכתוב בר.?כל. זה ימצא כל תו, וגם בלעדיו כלומר ברכל רצוף.
הערה, יש מושג כימות עצלן: כל מצייני הכמות מנסים תמיד למצוא את המקסימום. למשל אם נחפש אלמנט HTML שזה בעצם טקסט מוקף זויות, אנו עשויים לחפש "<.+>" - משמעות: סוגריים זויתיות שביניהם 1 או יותר של תו כל שהוא. כעת אם יש כמה זוגות של כאלה בטקסט במקום למצוא כל אחד לעצמו הוא יתפוס מהראשון עד האחרון ברציפות! הנה דוגמה. זה התנהגות הברירת מחדל שנקראת חמדנית. ההיפך של זה נקרא התנהגות עצלנית והיא מושגת ע"י הוספת סימן שאלה אחרי מציין הכמות - הכוכבית או הפלוס, הנה דוגמא עובדת. המשמעות היא להעדיף את ההתאמה המינימלית.
טוב, אני כבר חרגתי, ההמשך יבוא אי"ה ויהיה על קבוצות.
-
דיון על "לכל מנעול יש מפתח"@גגד
ראשית כל תודה על השתתפותך בפורום!
שנית, אנא מפציר בך, פתח נושא משלך על כל נושא משלך. הנזק של נושא כפול פחות בהרבה מנושא ארוך ו"לעוס" ומתפצל לתתי נושאים מעניין לעניין.
נושא חדש זה בחינם, ולא חייבים למצוא כותרת הכי טובה בעולם, ואפשר לתת לינק לנושא אחר אם רוצים ממש לחסוך במלל או להביא את מה שעורר את השאלה.
שלישית לגוף שאלתך, היא מידי תיאורטית כך שקשה לענות לך איך, בנושא החדש שתפתח נסה לתת קצת יותר הגשמה לשאלה. -
"חידה מתמטית פשוטה" או "למה אין לי אינטואיציה מתמטית בריאה?"@yossiz הזוי...
למעשה האינטואיציה שלי סתרה את עצמה, כי שחישבנתי כמה מים צריך להתאדות כדי שהחומר הנשאר יקפוץ לשני אחוז, יצא לי שצריך להתאדות כמעט 50 אחוז. ביטלתי את הדעה הזו כי זה לא הגיוני והלכתי לחשבון לצד השני.. בסוף עליתי על הבעיה ובדקתי באריכות עד שקלטתי.
עריכה אני כעת קולט שהחישבנתי לא נחשב אינטואיציה ולמעשה אני כ"כ מאמין לאינטאיציה שאני מבטל בהינף יד חשבונות סותרים. אני עדיין חושב שזה דרך חיים תקינה...אני לא הולך לחנך את האינטאיציה שלי, אני מפחד לקלקל אותה (היא מאוד שימושית עבורי בחיים בחידות מסוגים אחרים).
-
עזרה - הכנסת ערך לתיבת טקסט c#נראה שהמושג "שגיאה" אצלך נתפס כהתרחשות אלקטרונית לא ברורה שקורית עמוק עמוק מתחת למכסה המנוע.
שגיאה, זה דרך להסביר תקלה. אתה מבקש מהמוכר בחנות משחקים להביא לך שקית חלב, הוא לא מתעלם ממך, אלא הוא מניב שגיאה בזה הלשון "כאן זו לא חנות של אוכל" וזה עוזר לך ללמוד שיש כזה דבר חנות של אוכל ושמה יש חלב.
השגיאה פה שראית זה: CS0029 Cannot implicitly convert type 'decimal' to 'string'תרגום גוגל:
CS0029 לא יכול להמיר באופן מרומז את סוג 'עשרוני' ל 'מחרוזת'כלומר הצד השמאלי דהיינו label1.Text זה מאפייין מסוג טקסט - מחרוזת.
אתה מנסה להציב בו את numericUpDown1.Value שזה מאפיין מסוג מספרי, double.
השפה C# לא מרשה המרה מרומזת כי היא רוצה לוודא שאתה מתכוון לזה. ואתה בכלל לא מתכוון לזה, אתה סה"כ רוצה להפיק מהמספר את ייצוגו הטקסטואלי, בשבלי זה יש לך מתודה פשוטה ששמה ToString, תכתוב ככה:label1.Text = numericUpDown1.Value.ToString(); -
מה המחיר של המרת דיבור לטקסט של גוגלואני אגיד לכם סוד נוסף.
אני משלם לכמה חברות כל חודש וביניהם גם גוגל קלאוד.
ומעולם לא עשיתי משתמש חדש בשביל ה300 דולר הללו.
ולמה זה סוד? כי החכמה היא להתרכז באיך להרויח את המליון הבא ולא באיך לחסוך את הנסיעה באוטובוס. -
ארכיון סרטי יוטיוב שנפתחו על ידי נט פריhttp://netfreevideo.azurewebsites.net/
פורסם במקור בפורום CODE613 ב03/06/2016 00:29 (+03:00)
-
Adobe Photoshop, מניעת התמונה המקדימה בשעת הפתיחהכבר דובר פה על מניעת "תמונת המבזק" (splash screen) הלא צנועה שעולה עם פתיחת הפוטושופ בגרסאות האחרונות (2015-2018).
הדרך למנוע את זה היא שתילת פרמטר nosplash בהרצת התוכנה, רק שצריך לעשות זאת הן בקיצורי דרך והן בפתיחה האוטומטית (קליק כפול על פורמטים שהתוכנה פותחת בברירת מחדל).
@רחמים בנה תוכנה לזה בעבר, אבל כנראה בגלל תצורה שונה היא לא עבדה אצלי כמה פעמים אז בניתי אחת משלי, וכעת אני משתף אותה לטובת הציבור.
התוכנה: PhotoshopRegitryNoSplash.exe
יש להריץ את התוכנה, ולסגור את החלון השחור בסיום.קוד המקור בגיטאב: https://github.com/dovid-lt/PhotoshopRegitryNoSplash
-
התקנת "מפעל הפורמטים" המעודכן!עיקר הבעיה היא שהתוכנה הזו מציעה נוחות ודברים שאין לתוכנה אחרת להציע לאותו קהל יעד.
לכן גם אם זה יהיה וירוס ממש, אנשים ישאלו מה ההשלכות של הוירוס ובמידה והנזק יישמע להם סביר (למשל לוקח חמישים אחוז מעבד לכריית קריפטו ומעלה נתונים מסחריים של המשתמש לרשתות פרסום) הם ימשיכו להשתמש בה.
אני מציע במידת האפשר לא להשתמש בתוכנה זו שיש לה שם שלילי ומוניטין שלילי, אין להם מה להפסיד כמעט ולכן יש בהם אפס אמון. מצחיק שאנשים חוששים מלינק חשוד במייל אבל נותנים בלי בעיות הרשאות ניהול על המחשב שלהם לגורם מפוקפק.
הפוטנציאל של תוכנה בהרשאות ניהול במחשב היא גישה לכל נתון ודבר שקשור לשימוש במחשב, כולל אתרים פיננסיים ותכתובות ואנשי קשר וכמובן כל הסיסמאות, וזה יכול לקרות לאורך חיי התוכנה ביום בהיר. כמו כן זה יכול לתת לתוקף גישה מרחוק, או לשלוח הוראות זומביות. זה לא קרה עד עכשיו ככל הידוע, אבל זה פוטנציאל - מה שנקרא סיכון, שאין מולו סבירות שיכולה להרגיע.מה שכבר קורה עם התוכנה זה שהם דוחפים בהתקנה התקנות של דברים לא רצויים וגם בעייתיים, שמתגמלים אותם כספית. בינתיים זה המודל העסקי שלהם והתקוה היא שהמודל לא ישתנה לרעה או ימכר לאיזה גורם זדוני, ייתכן שזה כבר קרה.
למי שרוצה תחליף אין לי משהו אישית להציע, רק ראיתי באינטרנט את התוכנה https://handbrake.fr/ שהיא קוד פתוח. זה כמובן לא טוב למי שצריך עברית.
נ.ב. החוו"ד בעד התוכנה שהובאה בקישור במתמחים היא בורות אבטחה. זו תוכנה עם פוטנציאל נזק גבוה. גם בכל תוכנה אחרת לא שייך ההרגעות שכתובות שם, כי אפשר להרגיע שככל הנראה לא יקרה כלום (כי מה שהיה הוא שיהיה) אבל אין כזה מושג תוכנה בטוחה (למעט קוד פתוח שעברת על הקוד) ושום מומחה אבטחה לא יכול לתת את דברתו על שתוכנה כל שהיא לא תעשה נזק.
יש מושג חשש לא סביר שהוא טיעון מתאים מול חברות תוכנה מוכרות. גם ציון של נקיות מכל חברות האנטיוירוס לא אומרות שהתוכנה נקיה, אלא שהיא חפה מסיכונים מוכרים. המלצת אבטחה מספר אחד זה לא להתקין מה שלא צריך במחשב. -
הגנה מפישינג והאקינג@laswater באותו יום שההודעה הזו התפרסמה בפורום אז הופיע גם במייל שלי, וגם במייל של אשתי.
אז זה לא בגלל שמישהו שיחק בהגדרות. -
מחפש מדריך ללמוד אבטחת אתרים@מנסה-להבין אוקי, אני מבין שאתה מעוניין ממש בידע, יש לך חוש טכני, מבין טיפה מהחיים במושג אינטרנט.
הכיוון שלך כעת זה להבין יותר טוב את המושג אינטרנט, לשחק קצת עם בניית אתרים באופן שיחדד ויעזור להבחין מה קורה ומי עושה מה (המטרה הסופית של שלב זה להבין לגמרי מה עובר על כל דף אינטרנט בכל שלב. אחרי זה, תוכל ללמוד ולבחון על האיומים נפוצים הקלאסיים, ואיך מתמודדים איתם, אבל אני מקדים את המאוחר).
אתה אומר שיש לך אתר, תפרט מעט מה אתה כבר יודע ומה לא באתר שיש לך. איזה סוג מערכת רצה בו, דפי HTML או מערכת מוכנה כמו וורדפרס? כמה שיותר תפרט יותר אוכל לכוון אותך (תשתדל להתמקד במה אתה יודע על בניית אתרים).
(בנוגע לHTTP/S, בא תשאיר את זה לאח"כ). -
עדכונים לחוקי הפורוםבהזדמנות זו, תודה לכל המדווחים על בעיות, זה מאוד עוזר לנו בניהול.
גם כשלא נראה שנעשה משהו בשטח, המון פעמים יש לדיווחים השפעה ועזרה באיכות הפורום.תודה!
-
מדריך כתיבת אפליקציה וובית, Full-Stack, צעד אחר צעדקדימה, ממשיכים:
שיעור 6 טפסי HTML, צד שרת.
כעת א. נקבל בצד השרת את תוכן הבקשה בPOST מהטופס ששלחנו בadd-item, ב. ננתח אותו (כי הוא כתוב בפורמט הנקרא querystring של א=1&ב=2 ובמקרה שלנו משהו כמו the-name=דוגמה), ג. נוסיף את האיבר החדש לרשימה list ו... בינתיים זהו.
איך עושים את זה? פשוט מאוד? אוי ממש לא. מסובך, אבל לא נורא. בא נעקוב.
ראשית נשנה את הקוד הראשי של המתודה handleAllRequest שמכיל תנאי if שבודק את ערך הURL,
במקום שורה בודדת בכל בלוק בתנאי ללא { }, נשנה את זה כעת לבלוק מרובה שורות לכל מקטע:function handleAllRequest (req, res) { res.setHeader('Content-Type', 'text/html'); if (req.url == '/') { res.write('Hello To List Page!'); } else if (req.url == '/add-item') { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } else { res.write('Opss... Not Found!'); } res.end(); }כאמור לא שיניתי כלום, רק עטפתי כל מקטע בבלוק {}, שמאפשר לעשות שורות מרובות לכל התניה.
כעת, נבדיל במקרה של /add-item האם זה הגיע כGET שזה ביקור הדפדפן בדף או כPOST שזה לחיצת הלחצן בטופס:else if (req.url == '/add-item') { if (req.method == "POST") { // TODO: פה בעצם צריך לקבל את גוף הבקשה, לנתח אותו ואז להוסיף לרשימה (list) את האיבר שהתקבל מהטופס. } else { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } } else { res.write('Opss... Not Found!'); }כפי שרואים בשורה 3, המאפיין method מחזיק את דרך הגישה כטקסט.
אוקי. כעת נכתוב מתודה שתטפל ב: א. קבלת כל הבקשה, ב. ניתוח הטקסט.
נוסיף מחוץ לפונקציה (למשל בסוף הדף לגמרי אחרי כל הקוד) פונקציה חדשה בשם parsePostData שתקבל שתי פרמטרים א. הבקשה, ב. callback - פונקציה להפעלה כאשר היא תסיים את קבלת הבקשה וניתוחה:function parsePostData (req, callback) { }בתוך הפונקציה נאזין לאירוע של הבקשה. יותר נכון לשתי אירועים: 1. קבלת "חתיכת" מידע בגוף הבקשה (עקרונית יכול להיות הרבה, בגלל האופן בו עובד הTCP כל פעם מגיע "גוש") 2. סיום - כל החתיכות התקבלו. למה לא מספיק לנו רק הסיום? כי הנוד גם לא שומר לנו שום דבר שלא ביקשנו, כלומר החתיכות שמגיעות לא נשמרות בשום מקום בזיכרון וממילא בסיום לא תהיה לנו דרך לשחזר מה הסתיים בכלל...
רשות: הפעם זה אירוע ממש, לא סתם callback. הרשמה לאירוע נעשית בJS ע"י המתודה on על האובייקט שמממש אירועים, כשהארגומנט הראשון זה האירוע, והשני זה המטפל - אפשר לקרוא לזה שוב הcallback.
האובייקט req של נוד מממש אובייקט בשם Stream שזה תבנית תכנות מפורסמת, שמייצגת אובייקט שמספק נתונים כזרם - הוא לא מחזיק את הנתונים אלא מספק להם גישה ממש כמו צינור: יש לו פתח קבלה ופתח שפיכה ואפשר להירשם לאירועים שלו כדי לאגור את המידע או כדי לשנות את המידע ולספק אותו הלאה כזרם משלנו וכו'. בנוד יש כמה סוגי זרמים, כתיבה - Writable קריאה -Readable ושניהם. במקרה של בקשה הזרם הוא קריאה - הרי לא ניתן לכתוב לה. האירועים המפורסמים של Stream זה data לגוש חדש שמתקבל (הגוש נקרא בעגה התכנותית buffer וגודלו של הbuffer מותאם בד"כ למיטוב המקסימלי של היכולת הטכנית של הקלט/פלט הרלוונטיים) וend לסיום הזרימה (לא שזה בהכרח חייב לקרות).הנה ככה נראית ההרשמה לשני האירועים:
function parsePostData (req, callback) { req.on('data', function (chunk) { }) req.on('end', function () { }); }יש פה בעצם שתי שורות קוד בלבד, שורה 3 ושורה 7. בשורה 3 אנחנו נרשמים לאירוע data של הבקשה, כלומר כל פעם שמגיע גוש. בשורה 7 אנחנו נרשמים לאירוע end כלומר הודעה על כך שכל החתיכות יתקבלו.
צורת ההרשמה לשני האירועים זהה: אנחנו קוראים לפונקציה בשם on, מספקים לה כטקסט את האירוע המבוקש, ובנוסף מספקים לה כארגומנט שני פונקציה (ריקה בינתיים) חסרת שם (אנונימית) שתרוץ (כל פעם ש)האירוע יקרה.
באירוע של data אנחנו צריכים לאסוף את המידע. אתם בטח תוהים מה יש לאסוף מידע בפיסת מידע כה קצרה כמו שלנו, שזה אמור להיות כמה תווים בודדים כמו the-name=פרה. אבל נוד לא אמור לדעת מה גודל הבקשה, ומבחינתו ככה "קוראים" בקשות - נרשמים לקבלת פיסות מידע.
באירוע של end נדע שהמידע הסתיים להתקבל ורק אז ננתח אותו (ביישומים שונים ניתן לנתח את המידע תוך כדי קבלתו, אבל במקרה של פורמט הנתונים שלנו והצורך שלנו בהם, זה לא שייך).
נתחיל עם איסוף המידע. נקצה משתנה לאיסוף בשם text, ונדאג להוסיף לו כל חתיכה לכשתתקבל:function parsePostData (req, callback) { var text = ""; req.on('data', function (chunk) { text += chunk; }) req.on('end', function () { }); }כעת צריך לנתח את הכל בסיום. לשם כך נשתמש במחלקה בנוד. נעלה למעלה היכן שכתוב const http = require('http'); ונוסיף מתחתיה או מעליה את השורה:
const querystring = require('querystring');כעת נחזור לפונקציה שלנו ונשתמש בספריה כדי לנתח את הtext:
function parsePostData (req, callback) { var text = ""; req.on('data', function (chunk) { text += chunk; }) req.on('end', function () { var result = querystring.parse(text ); callback(result); }); }הניתוח מתבצע ע"י המתודה querystring.parse בשורה 9. הקלט שיהא מקבלת יהיה משהו כמו the-name=פרה והפלט יהיה אובייקט JS יפה כזה { "the-name": "פרה" }.
בשורה 10 אנחנו "קוראים חזרה" להמשך ביצוע: "גמרנו, קח את התוצאה ותעשה איתה מה שאתה רוצה". מי שלוקח את התוצאה זה מי שביקש אותה. בא נבקש אותה בhandleAllRequest במקרה של POST:else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { }); else { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); }בשורה 3 אנחנו מבקשים מparsePostData לנתח את גוף הבקשה, ולכשזה יתבצע להריץ את הפונקציה האנונימית שאנו מספקים לו כארגומנט שני. כעת יש להוסיף את האלמנט לרשימה שלנו, ע"י list.push. הקוד הסופי של כל האפליקציה שלנו ייראה ככה:
const http = require('http'); const querystring = require('querystring'); var server = http.createServer(handleAllRequest); server.listen(3000); var list = []; function handleAllRequest (req, res) { res.setHeader('Content-Type', 'text/html'); if (req.url == '/') { res.write('Hello To List Page!'); } else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { list.push(result["the-name"]); }); } else { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } } else { res.write('Opss... Not Found!'); } res.end(); } function parsePostData (req, callback) { var text = ""; req.on('data', function (chunk) { text += chunk; }) req.on('end', function () { var result = querystring.parse(text ); callback(result); }); }(העליתי את שורות הserver למעלה בשביל הסדר. אפשר לשנות את זה לטעמכם).
כעת בהרצת הקוד וכניסה לדף /add-item ומילוי הטופס ושליחתו יתווסף למערך List הערך שממנו בתיבה. אך הדף יהיה ריק, זאת משום שלא שלא כתבנו שום תשובה לבקשה. נשאיר זאת למחר, תודה שהייתם איתי!בהודעה הבאה נדבר בל"נ: א. פרקטיקות בתשובות לשליחת נתונים, ב. העברות התצוגות לקבצים מסודרים, ג. הקדמה למעבר לexpress.
-
מדריך כתיבת אפליקציה וובית, Full-Stack, צעד אחר צעדניתוב, הקדמת רשות
המושג ניתוב (route) באנגלית, זה "כיוון תנועה", למשל איש בדלפק מודיעין של משרד הפנים מנתב את הנכנסים לעמדות שונות בהתאם למה שהם צריכים.
בשרת אינטרנט המושג ניתוב בא לציין מי יטפל בבקשה, בהתאם לתכונה ובד"כ בהתאם לנתיב שלה. הנתיב זה מה שכתוב בדפדפן אחרי שם הדומיין, כלומר מהלוכסן שאחרי השם.אם כבר אנו מנתחים את הכתובת בא נעשה את זה יותר. ניקח למשל את הכתובת דוגמא הזו:
http://example.com/store/item/30?val=50&result=video#desc25נמחיש בתמונה את החלקים:
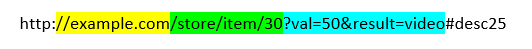
למכלול הזה אנו קוראים URL שפירוש המונח הזה זה כתובת שמצביעה על תוכן/פעולה, באופן ייחודי (אין כפל של כאלה כתובות ברחבי הגלקסיה - כי צייננו גם שם דומיין).
הURL הזה מרוכב מהפרטים הבאים:- http: סכמה - פרוטוקול גישה.
- //example.com משני הלוכסנים (עד הלוכסן הבא אם ישנו) זה הדומיין/host/שם המחשב (זה מתורגם לכתובת פיזית ויכול להיות ישירות כתובת פיזית כמו הכתובת 10.0.0.127:3000 שהיא הכתובת של המחשב הנוכחי).
- /store/item/30 - נתיב, באנגלית path. כל מה שאחרי הלוכסן הראשון (עד סימן שאלה או סולמית אם ישנם).
- ?val=50&result=video נקרא Query או Query-string. זה סט של צירופים, של שם תכונה, סימן =, וערך (מוכר בתכנות כ"מפתח וערך"). לציון תחילת הquery יש סימן שאלה, ולהפרדה בין סטים של צירופים (כמו במקרה שלנו שיש שתיים) משתמשים בתו &.
- #desc25 - נקרא fragment, זה כל מה שמהסולמית ואילך.
רוב החלוקות הללו הם מוסכמות שגורמות לדפדפן וגם לשרת האינטרנט להתנהג בהתאם.
מי שמגיע מphp או מasp או מסתם דפים סטטיים, רגיל שהנתיב דומה למערכת קבצים ממש - ב"תיקיה של האתר" (שזה באמת תיקיה של קבצים שנמצאת בשרת) יש קבצים וגם תיקיות משנה. אבל זו לא התנהגות מחוייבת בכלל, זו פשוט ההתנהגות האוטומטית של תוכנות שרתי האינטרנט הנפוצים (אפאצ'י וIIS ועוד).הנתיב הוא סה"כ עוד פרט בבקשה
כאמור בקשת אינטרנט היא מכתב טקסטואלי, שתמיד ממוען לכתובת המחשב המשוייכת להhost/דומיין, בלי קשר לנתיב.
ניתוב כזה או אחר זה סה"כ הבדל קטן בשורה הראשונה של הבקשה, שאם כבר, בא ננתח אותה.
בפניה לדף הבית (כלומר שורש האתר, שם האתר/דומיין ללא המשך), שתי השורות הראשונה של מכתב הבקשה נראית ככה:GET / HTTP/1.1 Host: example.comבשורה הראשונה יש שלושה מקטעים:
- מתודה (ניגע בהמשך, לא לפחד): GET
- נתיב / (כלומר כלום, / מציין שורש).
- HTTP/1.1 שם הפרוטוקול וגירסתו (לא ניגע בהמשך).
לעומת זאת בגישה לכתובת http://example.com/store/item/30?val=50&result=video#desc25 השורה הראשונה נראית בהתאם:
GET /store/item/30?val=50&result=video HTTP/1.1 Host: example.comנ.ב. חדי העין אולי שמו לב שהסוף, הלא הוא הפרגמנט #desc25, לא נמצא במכתב כלל, ואכן הדפדפן לא טורח להודיע לשרת על קיומו.
-
מדריך כתיבת אפליקציה וובית, Full-Stack, צעד אחר צעדהקדמה:
כעת אני קורא את השיעור הקודם
(למי שמעוניין יש בו את הקוד המלא של איפה שאנחנו אוחזים, מדובר באפליקצייה של דף בודד ותו לא),
ואני רואה שלא ממש גמרנו, צריך גם להראות את הרשימה.
לשם כך אני משנה את המקטע שלif (req.url == '/')שזה מתייחס ל"דף הבית" שלנו, ככה:if (req.url == '/') { res.write('Hello To List Page!<br>' + list.join('<br>') + '<br><a href="/add-item">Add Item To List</a>') ; }זה משרשר כמה טקסטים, בתוכם יש קריאה לפונקציה join של מערך (הליסט שלנו), כשהמפריד הוא הbr שזה אלמנט קפיצת שורה בHTML. בסוף על הדרך שמתי לינק (אלמנט a בHTML) לדף הadd-item להוספת פריט חדש.
כעת אפשר להריץ ולראות בהתחלה בדף הבית לינק להוספת פריט.
כעוברים לדף add-item וכשמזינים את הטופס ושלחים מקבלים דף ריק, אם נחזור ידנית לדף הבית נראה את הפריט שהתווסף בהצלחה.שיעור 7 - שוב על POST וגם על REDIRECT.
הסברתי בעבר שבשביל לשלוח את הטופס לשרת אני משתמש בPOST כי זה בדיוק התפקיד שלו.
למה? זה גורם לפעולה בצד השרת, זה בקשת אינטרנט שיש לה השפעה ולא רק קבלת מידע.
ומה הרווחנו שאנו פועלים לפי הכלל הזה? למשל את התנהגות הדפדפן שבעת ריענון של הדף אחרי השליחה זה יזהיר אותנו מפני פעולה כפולה. בGET זה יעשה את הפעולה שוב בלי אומר ודברים.
בצד שרת אנחנו יכולים לזהות האם הבקשה היא POST וGET בדיוק כפי שאנו יכולים לבדוק מה הURL. אם כן אנו יכולים להעמיס על URL שכבר בשימוש לGET, כמו כאן שכניסה לadd-item מביאה את הטופס, פעולה נוספת במקרה של POST.
השאלה היא מה קורה אחרי הPOST. אם נחזיר חזרה את הטופס בדיוק כפי שהיה, אז ללקוח יהיה תחושה שלא קרה כלום.
מה שמקובל (כל עוד אנו לא בAJAX - לא להיבהל, יילמד בהמשך) זה או להחזיר את הלקוח לרשימה ואז הוא מבין (וגם רואה) שבקשתו בוצעה.
בפשוטת יכולנו לעשות את זה פשוט - להחזיר בres.write את הרשימה, משהו כזה:else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { list.push(result["the-name"]); //בשלב זה אנחנו יכולים לכתוב תשובה ללקוח בדיוק כמו שעשינו בדף הבית res.write('Hello To List Page!<br>' + list.join('<br>') + '<br><a href="/add-item">Add Item To List</a>') ; }); }זה לא טוב. למה? כי למשתמש כעת יהיה בשורת הכתובת כתוב add-item והדף בעצם כעת מכיל רשימה. זה גם מאוד "לא נכון" וגם מבלבל, הוא יכול להעתיק את הלינק הזה או לשמור אותו במועדפים מאוחר יותר בלי להתייחס למה כתוב בו, ולהניח שזה לינק לרשימה, שהרי זה מה שהוא רואה.
אז אנחנו צריכים "לשנות את הכתובת בדפדפן" לדף הבית, ובכן זה בלתי אפשרי. מה שעושים זה גורמים לדפדפן לעבור לכתובת של דף הבית כאילו המשתמש לחץ על היפר קישור. עושים את זה ע"י תשובת Redirect.
יש כמה סוגי תשובות REDIRECT, הם מצויינים בקודים 3xx (כלומר 300, 301 וכו'). הסוג שנדרש לנו הוא 303 - See Other. הוא סוג פשוט שאומר, הכל בסדר, כעת תעבור לX.
המבנה של תשובת Redirect בבסיסה רק כותרת אחת ללא כל תוכן:HTTP/1.1 303 See Other Location: /אבל לא נוכל לעשות זאת מייד,
א. כי בקוד שלנו לפני התנאי בכלל כבר שמנו כותרת בשם 'Content-Type', עם HTML, מה שלא מתאים מקרה הזה.
ב. בקוד שלנו שמנו אחרי התנאי res.end שזה אומר לגמור את התשובה ולסגור את החיבור. הבעיה שבמקרה של הpost שלנו שאנו מוסיפים אלמנט לרשימה, הres.end קורה עוד לפני הוספת האלמנט שכן הוספת האלמנט נעשית כcallback למתודה האסינכרונית parsePostData (כזכור, המתודה parsePostData ניגשת לגוף הבקשה וגישה זו בנויה באופן אסינכרוני = "נודיע לך כזה יקרה", כי הטיפול בבקשה מתחיל עוד לפני שהיא סיימה להגיע).
לשם כך נשנה את הקוד בכמה דברים:function handleAllRequest(req, res) { if (req.url == '/') { var page = 'Hello To List Page!<br>' + list.join('<br>') + '<br><a href="/add-item">Add Item To List</a>'; sendHtml(res, page) ; } else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { list.push(result["the-name"]); res.writeHead(303, { Location: '/' }); res.end(); }); } else { sendHtml(res, `<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } } else { sendHtml(res, 'Opss... Not Found!'); } } function sendHtml(res, str){ res.setHeader('Content-Type', 'text/html'); res.end(str); }ראשית הסרנו את הres.setHeader והres.end שהיו לפני ואחרי התנאי, כי באחד המקרים של התנאי איננו רוצים את שניהם.
שנית בנינו פונקציה קטנה לשלוח html בתשובה, כדי לחסוך לכתוב שוב ושוב שלושה שורות: res.setHeader, ואז rew.write ולבסוף res.end. בעצם דילגנו על res.write לגמרי גם בפונקציה כי הres.end מקבלת כפרמטר תוכן בדיוק בשביל לחסוך מקרים כאלה (הwrite עושי למקרה של כתיבות רבות לאותה תשובה, במקרה של בודדת אפשר להשתמש בקיצור הזה).
שלישית, וזה הסיבה שעשינו את כל השינויים, הוספנו אחרי הוספת אלמנט (שורות 9-11) הפניה חזרה ל"דף הבית" כלומר לרשימה.תוכלו כעת לראות אפליקציה לתפארת ששומרת רשימה, אבל כל הרצה הרשימה נמחקת שהרי הכל שמור במשתנה list שבריצת האפליקציה עדיין ריק. אם נרצה לשמור בעולם האמיתי נשתמש כנראה במסד נתונים או בקבצים.
יש לציין שההעברה לרשימה אמנם מקובלת אבל היא לא "100%" מבחינת חוויית משתמש, כיון שיש משתמשים שעד שלא יאמרו להם שזה הצליח, הם לא יהיו בטוחים אם המחשב עשה את מה שהם התכוונו.
בשביל אלו אפשר לעשות העברה לדף אחר, בו כתוב "ההוספה הצליחה!", ומתחת לזה לינק "חזרה לרשימה". יש בזה אבל משהו מייגע עבור יתר המשתמשים. לכן יש כאלה שיעשו שהדף הזה יופיע לשלוש שניות - יהיה כתוב "מעביר אותך לרשימה...". זה בעצם REDIRECT שנעשה בצד הלקוח עם קוד עם השהיית זמן.
יש סיטאוציות שהכי הגיוני זה להישאר באותו הדף של הטופס, למשל אם מטבע הדברים אמורים לשלוח טופס שוב ושוב רצוף (בדוגמה שלנו לשים כמה הפריטים ברשימה). במקרה כזה מחזירים את אותו דף של add-item אבל כותבים איזה חיווי בצד לקוח (למטה או בכותרת צפה זמנית) שהנתונים נשלחו בהצלחה. -
שאלה: איך יוצרים תוכנה שלא תזוהה כוירוסכי פעם אחרונה שהגבתי פה משהו היה לפני אולי מאה שנה משהו כזה
@מכון-כתר-תורה תודה שבכל זאת באת!
אני אכן לא מכיר כלום באיך עובד הדברים בתחום הזה, ומתוך ידע זה כתבתי את הודעתי אותה אכתוב אותה שוב אם מישהו ישאל.
בהצלחה גם לך, אם תרצה להישאר עימנו למרות שאיננו שועלים שניתן להיות להם לראש, נשמח מאוד, אני בטוח שגם אתה.
עימנו פחות תצטרך לדון בדברי "מקטרגים" אלא בדיון השכלי גופו, כי אנחנו מאוד מקפידים פה על כבודו ושמו של כל אחד, והדיון פה מנסה מאוד מאוד להיות ענייני מקצועי ומעיל לכולם. כמובן שגם אני וכנראה גם אחרים יש להם בעיית אגו, אבל אנחנו לפחות מנסים פה מאוד להתגבר על חולשה זו. -
פרומיסים לוקחים זמן?@davidnead
סנכרוני = מסונכרן, דבר קורה מתי שציפו שיקרה (למשל C# היא שפה סינכרונית לחלוטין). אסינכרוני = כמו אנאלפבית כלומר לא מסונכרן. אין תזמון מסודר מה יקרה מתי. JS היא אסינכרונית, כלומר יש פעולות שאין המתנה לסיום שלהם וממילא הקוד שאחריהם יכול להיות "לא בעניינים".
כפי שאמרת, למעט בפעולות מסויימות מאוד JS נוהגת בדיוק כמו הדרך הראשונה, כלומר הקוד ממתין ומבצע לפי סדר.
await משנה את זה למראית עין בלבד. הוא מרשה לכתוב קוד יפה, בעוד שבאמת מה שקורה הוא שכל השורות שאחריו (עד סוף הפונקציה) נמחקות מהקוד, ומוכנסות בתוך הקאלבק של הפעולה אליו הוא ממתין. כלומר:var oneValueProccess = Promise.resolve(1); oneValueProccess.then(x => console.log(x));נראה יפה יותר ככה:
var x = await Promise.resolve(1); console.log(x);אבל זה בדיוק אותו קוד! מבחינת הרצת התוכנית.
כיון שזה בדיוק אותו דבר, כדאי להתמקד באמת שזה הקוד הראשון. כפי שאמרת יש "תחושה" לאיטיות, הנה המחשה:var oneValueProccess = Promise.resolve(1); oneValueProccess.then(x => console.log(x)); console.log('fast code win!!');הfast code win!! יודפס קודם, למרות שאנחנו יודעים היטב שלא לקח שום זמן לפרומייז לארגן את הערך 1 אותו הוא קיבל על מגש של כסף. הסיבה לכך היא המנגנון של הevent loop, בקוד JavaScript המחשב מבצע שורה אחרי שורה עד לסיום כלל השורות, ורק אז נפנה לעבור על קאלבקים שנפתרו.
לכן תמיד קוד בקאלבק יקרה אחרי כל שורה שהייתה זמינה ללא קלאבק לפניו. זה לא איטיות, זה פשוט תזמון.
(בפרומייז גם הקוד שמחולל את התוצאה הוא עצמו קלאבק, אז הוא גם תמיד יורץ אחרי הקוד הזמין ללא קאלבקים לפניו).
מה קורה כשאנו רוצים שקוד אחרי await לא יחכה סתם לתוצאה? פשוט משמיטים את המילה await. פירוש המילה awite היא... להמתין. אם אין await, הקוד שבפונקציה יבוצע מיידית עוד לפני השורה הבאה, אבל הפרומייזים שנמצאים בה או חוזרים ממנה ייפתרו בבוא העת = המאוחר מבין: סיום הרצתם, סיום הרצת כל הקוד הזמין ללא קלאבק. -
"חידה מתמטית פשוטה" או "למה אין לי אינטואיציה מתמטית בריאה?"@yossiz כשמתמתיקאי אומר לאדם מהשורה לא לסמוך על האינטואיציה, האדם הזה מוצא בזה עוד ראיה שחכמתו של המתמתיקאי מסתכמת במספרים.
-
חברת CLUB4U@אינטרקום צודק, אבל זה סוג עדכון שנוגע להודעה הפותחת ממש, והיא חשובה לכל מי שהיה בדיון הזה (כמובן אין לי מושג מי ה@חזקי-ב הזה ומה מטרותיו, אל תהיו תמימים בכלל בשום צעד בנושא)
אם כבר אני כותב שוב בנושא הזה, אעדכן שclub4u ניסו לגרום למחיקת הנושא הזה, ואכן לא מצאתי אזכורים שלהם בשום פורום אחר (א. כי הם עושים עבודה טובה ב. כי מנהלי הפורומים בארץ לא חסידים גדולים של אידאלים שיכולים להזיק ).