Lucene .NET היא ספרייה המשמשת ליצירת מנועי חיפוש חזקים ויעילים בתוך התוכנה שלכם.
הקודים דלהלן נכתבו מתוך נסיון ולכן גם במקום שנראה לכם שלא צריך לעשות כמו שאמרתי תשקלו זאת פעמיים או יותר טוב תשאלו למה עשיתי ככה.
כדי להשתמש בספרייה זו תצטרכו להתקין דרך ממשק ה-nuget ב-Visual Studio כמה ספריות. הספרייה הנוכחית של Lucene עדיין בשלבי בטא ולכן תצטרכו לסמן בחלונית ה-nuget את האפשרות "Include prerelease".
להלן הספריות שתצטרכו:
Lucene.Net
Lucene.Net.QueryParser
שלב א' - יצירת analyzer
כל מנוע חיפוש בנוי על אינדקס, כלומר הוא מפרק את הטקסט לחלקים ובונה לעצמו אינדקס בו רשום היכן כל מילה נמצאת. Lucene משתמש במחלקה שנקראת Analyzer בכדי לפרק את הטקסט.
לכן, שלב ראשון עלינו לייצר Analyzer:
Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48);
בגרסה 4.8 הפירוק גם בעברית נעשה בצורה טובה. אם אתם רוצים משהו יותר מתקדם תוכלו לנסות את HebMorph, אבל הוא לא מעודכן לגרסה הנוכחית של Lucene ולכן במדריך זה לא נתמקד בו.
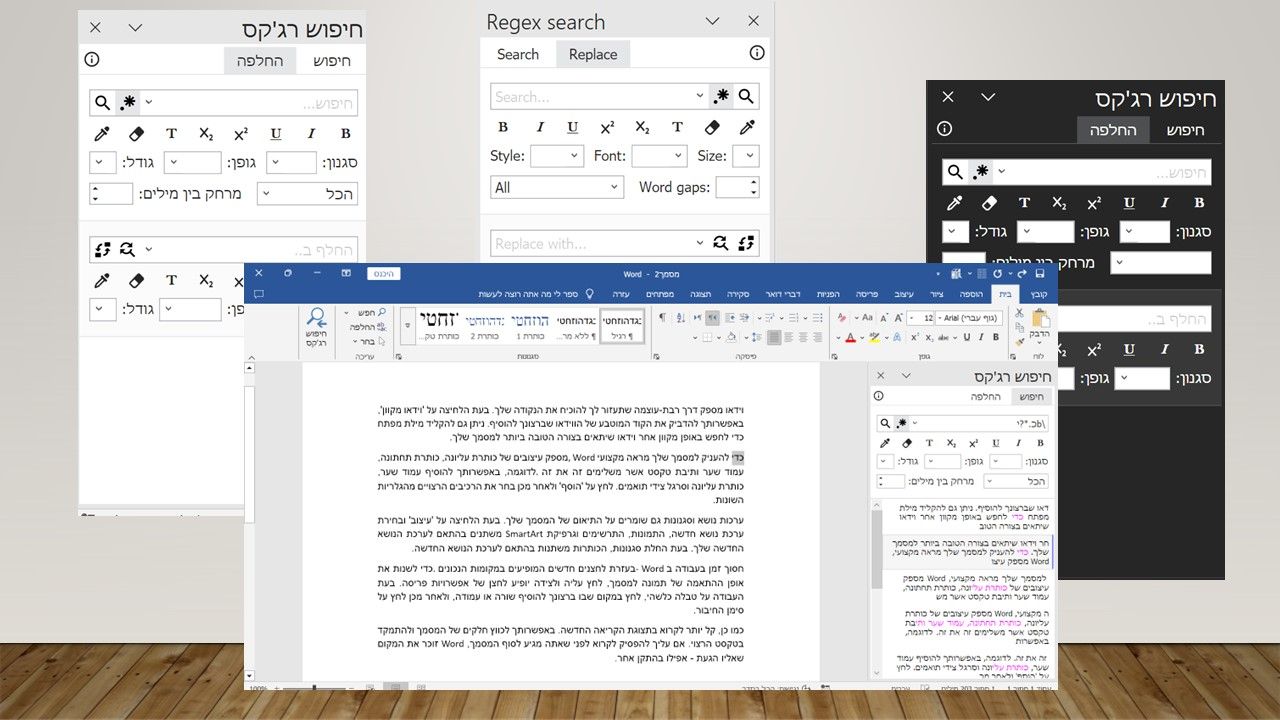
אם ברצונכם לתמוך בחיפוש גם בטקסט מנוקד תצטרכו לייצר analyzer משלכם שמסיר את הניקוד כדלהלן:
public class DiacriticsAnalyzer : Analyzer
{
LuceneVersion version;
public DiacriticsAnalyzer(LuceneVersion luceneVersion)
{
version = luceneVersion;
}
protected override TokenStreamComponents CreateComponents(string fieldName, TextReader reader)
{
var tokenizer = new StandardTokenizer(version, reader);
TokenStream filter = new HebrewTokenFilter(tokenizer);
filter = new LowerCaseFilter(version, filter);
filter = new StopFilter(version, filter, StopAnalyzer.ENGLISH_STOP_WORDS_SET);
return new TokenStreamComponents(tokenizer, filter);
}
sealed class HebrewTokenFilter : TokenFilter
{
private readonly ICharTermAttribute termAttr;
public HebrewTokenFilter(TokenStream input) : base(input)
{
this.termAttr = AddAttribute<ICharTermAttribute>();
}
public sealed override bool IncrementToken()
{
if (m_input.IncrementToken())
{
string token = termAttr.ToString();
string cleanedToken = Regex.Replace(token, @"\p{M}", "");
if (!string.Equals(token, cleanedToken))
{
termAttr.SetEmpty().Append(cleanedToken);
}
return true;
}
return false;
}
}
}
אפשר להוסיף עוד פונצינליות ל-analyzer כמו פתיחת ראשי תיבות או מילים נרדפות. כאן תוכלו למצוא דוגמא מיושמת כמו"כ הכותב שם יצר תוכנה קטנה שמציגה איך analyzer עובד.
שלב ב' - יצירת האינדקס
להלן קוד דוגמא ליצירת אינדקס מתוך מערך של קבצי טקסט
public void IndexFiles(List<string> files)
{
using (var directory = FSDirectory.Open(new DirectoryInfo(indexPath)))
{
var indexConfig = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer);
using (var writer = new IndexWriter(directory, indexConfig))
{
foreach (string file in files)
{
string content = File.ReadAllText(file);
var doc = new Document
{
new StringField("Path", file, Field.Store.YES),
new TextField("Content", content, Field.Store.YES)
};
var term = new Term("Path", file); // Create a term to search for the existing document by its path
writer.UpdateDocument(term, doc); // Update the document if it exists, otherwise add it
}
writer.Flush(triggerMerge: true, applyAllDeletes: true);
}
}
}
מאוד חשוב להקפיד על ה-using כדי למנוע מצב בו האינדקס נשאר נעול במצב כתיבה.
כדי למחוק קבצים מהאינדקס תוכלו להתמש עם הקוד דלהלן:
public void RemoveFiles(List<string> files)
{
using (var directory = FSDirectory.Open(new DirectoryInfo(indexPath)))
{
var indexConfig = new IndexWriterConfig(Lucene.Net.Util.LuceneVersion.LUCENE_48, analyzer);
using (var writer = new IndexWriter(directory, indexConfig))
{
var parser = new QueryParser(Lucene.Net.Util.LuceneVersion.LUCENE_48, "Path", analyzer);
foreach (string file in files)
{
Query query = parser.Parse(file);
writer.DeleteDocuments(query);
}
writer.Flush(triggerMerge: false, applyAllDeletes: false);
}
}
}
שלב ג' חיפוש באינדקס
כדי לחפש באינדקס קודם כל תצטרכו ליישם QueryParser אשר תפקידו לעשות parsing למחרוזת הטקסט של החיפוש.
ישנם כמה וכמה סוגים של QueryParsers תלוי מאוד מה הצורך שלכם תוכלו לקרוא על כך בהרחבה בלינק שהבאתי בתחלילת הפוסט, עבור חיפוש עם אפשרויות מגוונות אני ממליץ לכם להתשמש עם ComplexPhraseQueryParser מה שיאפשר למשתמש אפשרויות חיפוש מגווונות כגון חיפוש טבלאי וחיפוש עם wildcards חיפוש מטושטש ועוד ועוד. תוכלו לקרוא על הסינטקס של חיפוש lucene בקישור שבתחילת הפוסט.
Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48);
ComplexPhraseQueryParser queryParser = new ComplexPhraseQueryParser(LuceneVersion.LUCENE_48, "Content", analyzer);
שימו לב! חיפוש מילה עם ראשי תיבות יחזיר שגיאה יש להזין את הראשי תיבות בתוספת slash ככה
אא\"כ
כעת תוכלו לערוך חיפוש עם ה-QueryParser. בדוגמא דלהלן החיפוש מחזיר את שדה השמות של הקבצים שנמצאו תואמים מתוך האינדקס.
public List<string> Search(string queryText, List<string> checkedTreeNodes)
{
using (var directory = FSDirectory.Open(new DirectoryInfo(indexPath)))
{
var searcher = new IndexSearcher(DirectoryReader.Open(directory));
var parser = new CostumeQueryParser(Lucene.Net.Util.LuceneVersion.LUCENE_48, "Content", analyzer);
var query = parser.Parse(queryText);
var topDocs = searcher.Search(query, int.MaxValue);
List<string> results = new List<string>();
foreach (var scoreDoc in topDocs.ScoreDocs)
{
var path = searcher.Doc(scoreDoc.Doc).Get("Path");
results.Add(path);
}
return results;
}
}
שלב ג' -2 איך לייצר גזירים
כדי לייצר גזירים תצטרכו להתקין את חבילת ה-nuget
Lucene.Net.Highlighter
לאחמ"כ תוכלו להשתמש עם הקוד הזה
string[] GetFragments(int docId, IndexSearcher searcher, Query query)
{
//create fragmenter
var reader = searcher.IndexReader;
var scorer = new QueryScorer(query);
var fragmenter = new SimpleSpanFragmenter(scorer, 250); // 250 is the fragment size
// create highlighter
var formatter = new SimpleHTMLFormatter("<", ">"); //define how to mark found keywords if left empty <b> tags is the default
var highlighter = new Highlighter(formatter, scorer);
highlighter.TextFragmenter = fragmenter;
//extract snippets
var content = searcher.Doc(docId).Get("Content");
var tokenStream = TokenSources.GetAnyTokenStream(reader, docId, "Content", analyzer);
var fragments = highlighter.GetBestTextFragments(tokenStream, content, false, 10); // 10 is the number of snippets
// return filters the list and converts to string filtering is needed only if number of fragments is set to more then 1
return fragments.Where(fragment => fragment.Score > 0).Select(fragment => fragment.ToString()).ToList().ToArray();
}
הקוד הזה מקבל שלוש משתנים מפונציית החיפוש שהבאנו למעלה. פונקציית החיפוש בעצם מזהה אלו מסמכים מכילים את טקסט החיפוש ומחזירה רשימה של מספר הזיהוי של כל מסמך שיש בו תוצאה תואמת
הקוד של הגזירים מקבל את מספר הזיהוי של המסמך שקבילנו בתוצאות + השאילתא שהתשמשנו בה + הגדרות השאילתא