שליפת כל המשפטים בעברית מתוך קובץ PHP
-
יש לי קובץ PHP שבניתי ל API לימות המשיח
שכולל בתוכו הרבה מילים בעברית להקראה האוטומטית בטלפון
עכשיו אני רוצה לעשות רשימה מסודרת של ההודעות מערכת
האם יש איזהו תוכנה שתסדר לי רשימה של כל המשפטים בעברית? -
@yossiz
מצאתי סקריפט בPHP ששולף את כל המילים בעברית אבל
א) אני רוצה שזה יחלק למשפטים
ב) איך אני מכניס לתוכו טקסט שהוא בעצם סקריפט של PHP
זה הסקריפט שלי<?php $input = "גככדגכfgfdgfdsgכגעיכדיעכ"; preg_match_all( "/[\\x{0590}-\\x{05FF}]+/u", $input, $matches ); echo '<pre>'; print_r( $matches ); echo '</pre>'; ?>מייל: nigun@duck.com
-
@yossiz
מצאתי סקריפט בPHP ששולף את כל המילים בעברית אבל
א) אני רוצה שזה יחלק למשפטים
ב) איך אני מכניס לתוכו טקסט שהוא בעצם סקריפט של PHP
זה הסקריפט שלי<?php $input = "גככדגכfgfdgfdsgכגעיכדיעכ"; preg_match_all( "/[\\x{0590}-\\x{05FF}]+/u", $input, $matches ); echo '<pre>'; print_r( $matches ); echo '</pre>'; ?> -
למה אתה מתחיל מ 0x0590 עד 0x05FF ?
יוניקוד אלפא בית מתחיל מ 0x05D0 ועד 0x05EA -
למה אתה מתחיל מ 0x0590 עד 0x05FF ?
יוניקוד אלפא בית מתחיל מ 0x05D0 ועד 0x05EA@משחזר-מידע
כי זה הקוד שראיתי בstackoverflow -
@משחזר-מידע
כי זה הקוד שראיתי בstackoverflow@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
כי זה הקוד שראיתי בstackoverflow
אוקיי נניח (בכלל מאתיים, מנה) מ 0590 ועד 05D0 זה סימנים
https://en.wikipedia.org/wiki/Unicode_and_HTML_for_the_Hebrew_alphabet -
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
אני מנסה לכתוב בnotepad++
אולי notepad++ עובד על ascii (?!) (או HEX)
-
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
אני מנסה לכתוב בnotepad++
אולי notepad++ עובד על ascii (?!) (או HEX)
@משחזר-מידע
גם בויזואל סטודיו זה לא מוצא כלום -
לך על HEX
הכי פשוט -
@משחזר-מידע
כי זה הקוד שראיתי בstackoverflow -
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
אני מנסה לכתוב בnotepad++
/[\x{0590}-\x{05FF}]+/uוזה לא עובד
כי זה לא regex תקין. (ה-
/בהתחלה וסוף הוא לא חלק משפת regex אלא שפת PHP, הכפילות של ה-\\גם נצרך רק ב-PHP, ה-uבסוף הוא דגל שגם לא חלק מה-regex)
זה תקין, אם כי יכול להיות שזה לא יעשה בדיוק מה שאתה רוצה...
תקין, אם כי יכול להיות שזה לא יעשה בדיוק מה שאתה רוצה...[\x{0590}-\x{05FF} ]+ -
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
אני מנסה לכתוב בnotepad++
/[\x{0590}-\x{05FF}]+/uוזה לא עובד
כי זה לא regex תקין. (ה-
/בהתחלה וסוף הוא לא חלק משפת regex אלא שפת PHP, הכפילות של ה-\\גם נצרך רק ב-PHP, ה-uבסוף הוא דגל שגם לא חלק מה-regex)
זה תקין, אם כי יכול להיות שזה לא יעשה בדיוק מה שאתה רוצה...[\x{0590}-\x{05FF} ]+@yossiz אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
עושה בדיוק מה שאני רוצה
(דהיינו מוצא משפטים שלמים)
אבל אני רוצה משהו כמו סקריפט שיוציא לי באופן מסודר את הכל
ניסיתי לכתוב משהו בפייתון אבל הסתבכתי עם הקידוד
האם זה הכיוון?import re string = unicode('אבגד', 'utf-8') pattern = '[\x{0590}-\x{05FF} ]+' result = re.findall(pattern, string) print(result) -
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
עושה בדיוק מה שאני רוצה
מקווה שזה נכון למרות שלא נראה לי...
לדוגמה:
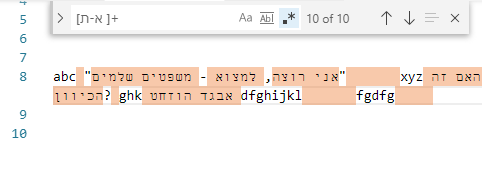
אבל אני רוצה משהו כמו סקריפט שיוציא לי באופן מסודר את הכל
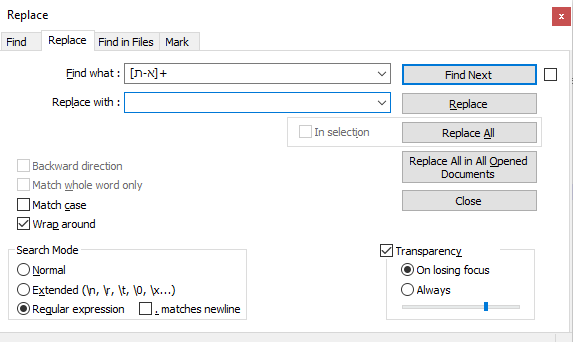
עדיין אין צורך בסקריפט, אפשר ב-vscode כך:
- ctrl+f
[א-ת ]+ - ctrl+shift+l (בוחר כל המופעים)
- ctrl+c
- ctrl+n
- ctrl+v
ניסיתי לכתוב משהו בפייתון אבל הסתבכתי עם הקידוד
import re string = u'\u05d0\u05d1\u05d2\u05d3 abc \u05d4\u05d5\u05d6\u05d7' # 'אבגד abc הוזח' pattern = u'[\u05d0-\u05ea ]+' # '[א-ת ]+' result = re.findall(pattern, string) print(result)📧 יוסי@מייל.קום | 🌎 בלוג | ☕ קפה
👈 רוצים כתובת מייל בעברית? כנסו למייל.קום 👉 - ctrl+f
-
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
עושה בדיוק מה שאני רוצה
מקווה שזה נכון למרות שלא נראה לי...
לדוגמה:
אבל אני רוצה משהו כמו סקריפט שיוציא לי באופן מסודר את הכל
עדיין אין צורך בסקריפט, אפשר ב-vscode כך:
- ctrl+f
[א-ת ]+ - ctrl+shift+l (בוחר כל המופעים)
- ctrl+c
- ctrl+n
- ctrl+v
ניסיתי לכתוב משהו בפייתון אבל הסתבכתי עם הקידוד
import re string = u'\u05d0\u05d1\u05d2\u05d3 abc \u05d4\u05d5\u05d6\u05d7' # 'אבגד abc הוזח' pattern = u'[\u05d0-\u05ea ]+' # '[א-ת ]+' result = re.findall(pattern, string) print(result) - ctrl+f
-
@yossiz
מצויין
עכשיו איך אני מסנן את כל הרווחים שהם לא בין מילים בעברית
עריכה: שמתי הכל באקסל ומיינתי מהגדול לקטן
אבל אולי יש דרך יותר חכמה -
@nigun אם אתה לא מכיר את הנושא ודאי שווה ללמוד אותו
דרך אגב, ה-regex שכתבתי למעלה לא טוב
 (כי הוא "רעבתני" מדי...)
(כי הוא "רעבתני" מדי...)
ניסיתי כך:['"].*?[א-ת].*?['"]ועדיין לא עובד. אני לא מבין למה.
ה-?אמור למגר את ה"רעבתנות". אבל הוא לא...

אולי @dovid יכול לשפוך אור על הנושא.
עריכה: הבנתי למה לא עובד. אבל עדיין לא יודע איך כן אפשר לכתוב אותו
עריכה2: זה עובד:['"][^"']*[א-ת][^"']*['"]למעשה זה עדיין נכשל במקרים מסויימים אבל נראה לי שלטפל בזה מגרד את גבולות היכולת של regex-ים.
@nigun אמר בשליפת כל השפטים בעברית מתוך קובץ PHP:
או שעדיף להתחיל עם משהו יותר פשוט
לא נראה לי, זה לא נושא כל כך ענקי.
כאן יש אתר כיפי להתאמן