
שיפור בINFIX וייצוא לוורד
-
@one1010 קיבלתי את המייל
נראה שמדובר בקובץ מתוכנת תג
יש שם רק גופן אחד שמקודד בצורה לא נכונה (וילנא,בולד)
ראיתי שתיקון ב-infix לא שומר את התיקון בגוף ה-PDF אלא בקובץ תצורה של התוכנה , לפי מה שזכור לי, פעם זה כן היה מתקן בגוף ה-PDF
, לפי מה שזכור לי, פעם זה כן היה מתקן בגוף ה-PDF
חוץ מקידוד לא נכון יש עוד אתגרים בהמרה לוורד. בהמרה המובנה של infix יצא לי הכל הפוך, זה מוזר כי בהמרה ל-html זה יצא טוב יחסית. אבל צריך לשלם להם כדי לקבל המרה בלי איקסים
הייבוא המובנה של וורד יוצא לא רע (אבל גם לא טוב...)@yossiz כתב בשיפור בINFIX וייצוא לוורד:
@one1010 קיבלתי את המייל
נראה שמדובר בקובץ מתוכנת תגואוו, גם את זה אפשר לראות?! האם ניתן להמיר בחזרה לתג?
יש שם רק גופן אחד שמקודד בצורה לא נכונה (וילנא,בולד)
אז מדוע בINFIX היו לי עשרות אם לא מאות תיקונים?!
ראיתי שתיקון ב-infix לא שומר את התיקון בגוף ה-PDF אלא בקובץ תצורה של התוכנה
, לפי מה שזכור לי, פעם זה כן היה מתקן בגוף ה-PDFשזה אומר מבחינתי? מה אני צריך/יכול לעשות?
חוץ מקידוד לא נכון יש עוד אתגרים בהמרה לוורד. בהמרה המובנה של infix יצא לי הכל הפוך, זה מוזר כי בהמרה ל-html זה יצא טוב יחסית. אבל צריך לשלם להם כדי לקבל המרה בלי איקסים
- יש המרה מובנה לINFIX?
בהעתקה זה לא יוצא הפוך אבל הבעיות עדיין קיימות
הייבוא המובנה של וורד יוצא לא רע (אבל גם לא טוב...)
פחות קריטי לי המבנה. העיקר שהטקסט יהיה מושלם.
תודה רבה!!
- יש המרה מובנה לINFIX?
-
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
החלפת אותיות במקום ג נ במקום ב כ במקום ו ן וכן כיוצא בזה
שיבושים של החלפת אותיות דומות קורה רק ב-OCR, עדיין לא ברור לי אם עשית OCR או לא, מדובר בקובץ עם תוכן טקסטואלי, אתה לא אמור לעשות עליו OCR
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
החלפת אותיות במקום ג נ במקום ב כ במקום ו ן וכן כיוצא בזה
שיבושים של החלפת אותיות דומות קורה רק ב-OCR, עדיין לא ברור לי אם עשית OCR או לא, מדובר בקובץ עם תוכן טקסטואלי,
עשיתי פתיחה של הקובץ בוורד. זה נחשב OCR?
אתה לא אמור לעשות עליו OCR
גם לא יעזור?!
-
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
@one1010 קיבלתי את המייל
נראה שמדובר בקובץ מתוכנת תגואוו, גם את זה אפשר לראות?! האם ניתן להמיר בחזרה לתג?
יש שם רק גופן אחד שמקודד בצורה לא נכונה (וילנא,בולד)
אז מדוע בINFIX היו לי עשרות אם לא מאות תיקונים?!
ראיתי שתיקון ב-infix לא שומר את התיקון בגוף ה-PDF אלא בקובץ תצורה של התוכנה
, לפי מה שזכור לי, פעם זה כן היה מתקן בגוף ה-PDFשזה אומר מבחינתי? מה אני צריך/יכול לעשות?
חוץ מקידוד לא נכון יש עוד אתגרים בהמרה לוורד. בהמרה המובנה של infix יצא לי הכל הפוך, זה מוזר כי בהמרה ל-html זה יצא טוב יחסית. אבל צריך לשלם להם כדי לקבל המרה בלי איקסים
- יש המרה מובנה לINFIX?
בהעתקה זה לא יוצא הפוך אבל הבעיות עדיין קיימות
הייבוא המובנה של וורד יוצא לא רע (אבל גם לא טוב...)
פחות קריטי לי המבנה. העיקר שהטקסט יהיה מושלם.
תודה רבה!!
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
ואוו, גם את זה אפשר לראות?!
לא, זה היה ניחוש מושכל...
האם ניתן להמיר בחזרה לתג?
לא
אז מדוע בINFIX היו לי עשרות אם לא מאות תיקונים?!
לפעמים זה קורה שגופן אחד מוכפל עשרות פעמים בקובץ, נראה לי שזה קורה אם מדבקים ביחד כמה PDF-ים
(אפשר לתקן את זה בתוכנה שעושה מיטוב PDF)שזה אומר מבחינתי?
שלא יעזור לשמור את הקובץ גם עם סימן מים, צריך לשלם להם כדי לייצא את התוצאה
יש המרה מובנה לINFIX?
כן. file->export
עשיתי פתיחה של הקובץ בוורד. זה נחשב OCR?
לא (אאל"ט, לפעמים וורד כן עושה OCR אם הוא מזהה צורך, אבל במקרה הזה פתחתי את הדף ששלחת לי בוורד וזה נפתח בלי OCR)
אתה לא אמור לעשות עליו OCR
גם לא יעזור?!
אולי זה יכול לעזור קצת, אבל זה גם יזיק כי זה פחות מדוייק מייצוא הטקסט המקורי
- יש המרה מובנה לINFIX?
-
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
ואוו, גם את זה אפשר לראות?!
לא, זה היה ניחוש מושכל...
האם ניתן להמיר בחזרה לתג?
לא
אז מדוע בINFIX היו לי עשרות אם לא מאות תיקונים?!
לפעמים זה קורה שגופן אחד מוכפל עשרות פעמים בקובץ, נראה לי שזה קורה אם מדבקים ביחד כמה PDF-ים
(אפשר לתקן את זה בתוכנה שעושה מיטוב PDF)שזה אומר מבחינתי?
שלא יעזור לשמור את הקובץ גם עם סימן מים, צריך לשלם להם כדי לייצא את התוצאה
יש המרה מובנה לINFIX?
כן. file->export
עשיתי פתיחה של הקובץ בוורד. זה נחשב OCR?
לא (אאל"ט, לפעמים וורד כן עושה OCR אם הוא מזהה צורך, אבל במקרה הזה פתחתי את הדף ששלחת לי בוורד וזה נפתח בלי OCR)
אתה לא אמור לעשות עליו OCR
גם לא יעזור?!
אולי זה יכול לעזור קצת, אבל זה גם יזיק כי זה פחות מדוייק מייצוא הטקסט המקורי
-
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
ואוו, גם את זה אפשר לראות?!
לא, זה היה ניחוש מושכל...
האם ניתן להמיר בחזרה לתג?
לא
אז מדוע בINFIX היו לי עשרות אם לא מאות תיקונים?!
לפעמים זה קורה שגופן אחד מוכפל עשרות פעמים בקובץ, נראה לי שזה קורה אם מדבקים ביחד כמה PDF-ים
(אפשר לתקן את זה בתוכנה שעושה מיטוב PDF)שזה אומר מבחינתי?
שלא יעזור לשמור את הקובץ גם עם סימן מים, צריך לשלם להם כדי לייצא את התוצאה
יש המרה מובנה לINFIX?
כן. file->export
עשיתי פתיחה של הקובץ בוורד. זה נחשב OCR?
לא (אאל"ט, לפעמים וורד כן עושה OCR אם הוא מזהה צורך, אבל במקרה הזה פתחתי את הדף ששלחת לי בוורד וזה נפתח בלי OCR)
אתה לא אמור לעשות עליו OCR
גם לא יעזור?!
אולי זה יכול לעזור קצת, אבל זה גם יזיק כי זה פחות מדוייק מייצוא הטקסט המקורי
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
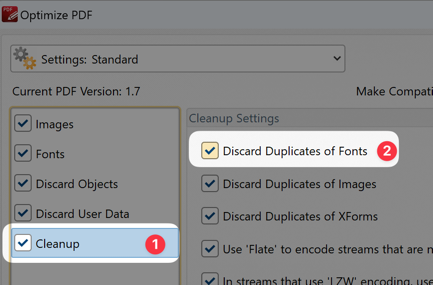
לפעמים זה קורה שגופן אחד מוכפל עשרות פעמים בקובץ, נראה לי שזה קורה אם מדבקים ביחד כמה PDF-ים
(אפשר לתקן את זה בתוכנה שעושה מיטוב PDF)השגתי INFIX 'חופשי' תוכל ללמד אותי בבקשה איך עושים את המיטוב PDF כדי לחסוך זמן?
-
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
לפעמים זה קורה שגופן אחד מוכפל עשרות פעמים בקובץ, נראה לי שזה קורה אם מדבקים ביחד כמה PDF-ים
(אפשר לתקן את זה בתוכנה שעושה מיטוב PDF)השגתי INFIX 'חופשי' תוכל ללמד אותי בבקשה איך עושים את המיטוב PDF כדי לחסוך זמן?
-
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
תוכל ללמד אותי בבקשה איך עושים את המיטוב PDF כדי לחסוך זמן?
אני מאמין שיש כמה תוכנות שעושים את זה. אני משתמש ב-pdfxchange, זו תוכנה בתשלום, אם תשיג גם אותו "חופשי" מדובר בתפריט זה
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
pdfxchange
ביצעתי את האמור.
למעט צימצום הגופנים הקיימים מ92 ל70 לא ראיתי שום התקדמות...במה יכול להיות שאני טועה?
עשיתי את השלבים הבאים:- פתיחת תוכנת INFIX
- ייבוא קובץ PDF
- מיפוי הגופנים ע"י בחירה בתפריט: טקסט-REMAP FONTS
- אני עובר גופן גופן ומתקן לפי הצורך.
- בסוף ההליך לוחץ OK
- שומר ע"י SAVE AS
- פותח את הקובץ PDF מעתיק הכל ומדביק בקובץ וורד [מדביק רק טקסט ללא עיצוב]
ועדיין מקבל שגיאות רבות...
משהו במה שעשיתי לא תקין?!אגב, כשאני מיצא לHTML חוץ מעשרות קבצים שנשמרים לי במחשב אני מקבל שגיאה בשלב מסויים. מה בזה אני לא עושה נכון?
כן מעניין אותי HTML כי זה נראה דווקא יחסית טוב. אבל יש XXXX למרות שהגירסה שלי מאוקטבת וכן הכל הפוך...אשמח ואודה מאד לעזרה!!
-
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
pdfxchange
ביצעתי את האמור.
למעט צימצום הגופנים הקיימים מ92 ל70 לא ראיתי שום התקדמות...במה יכול להיות שאני טועה?
עשיתי את השלבים הבאים:- פתיחת תוכנת INFIX
- ייבוא קובץ PDF
- מיפוי הגופנים ע"י בחירה בתפריט: טקסט-REMAP FONTS
- אני עובר גופן גופן ומתקן לפי הצורך.
- בסוף ההליך לוחץ OK
- שומר ע"י SAVE AS
- פותח את הקובץ PDF מעתיק הכל ומדביק בקובץ וורד [מדביק רק טקסט ללא עיצוב]
ועדיין מקבל שגיאות רבות...
משהו במה שעשיתי לא תקין?!אגב, כשאני מיצא לHTML חוץ מעשרות קבצים שנשמרים לי במחשב אני מקבל שגיאה בשלב מסויים. מה בזה אני לא עושה נכון?
כן מעניין אותי HTML כי זה נראה דווקא יחסית טוב. אבל יש XXXX למרות שהגירסה שלי מאוקטבת וכן הכל הפוך...אשמח ואודה מאד לעזרה!!
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
שומר ע"י SAVE AS
זה לא יעזור כפי שכתבתי למעלה:
ראיתי שתיקון ב-infix לא שומר את התיקון בגוף ה-PDF אלא בקובץ תצורה של התוכנה
, לפי מה שזכור לי, פעם זה כן היה מתקן בגוף ה-PDFשזה אומר מבחינתי? מה אני צריך/יכול לעשות?
שלא יעזור לשמור את הקובץ גם עם סימן מים, צריך לשלם להם כדי לייצא את התוצאה
האפשרות היחידה עם תוכנה זו הוא לייצא מתוך התוכנה
יש המרה מובנה לINFIX?
כן. file->export
-
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
שומר ע"י SAVE AS
זה לא יעזור כפי שכתבתי למעלה:
ראיתי שתיקון ב-infix לא שומר את התיקון בגוף ה-PDF אלא בקובץ תצורה של התוכנה
, לפי מה שזכור לי, פעם זה כן היה מתקן בגוף ה-PDFשזה אומר מבחינתי? מה אני צריך/יכול לעשות?
שלא יעזור לשמור את הקובץ גם עם סימן מים, צריך לשלם להם כדי לייצא את התוצאה
האפשרות היחידה עם תוכנה זו הוא לייצא מתוך התוכנה
יש המרה מובנה לINFIX?
כן. file->export
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
זה לא יעזור כפי שכתבתי למעלה:
הא, חשבתי שאתה מתכוון רק בחינמי זה ככה.
משום מה הייצוא מאוקסס.
בכל אופן השתמשתי לבסוף בAXESPDF
נתן תוצאות יחסית מרשימות.
עדיין נראה שהוא נתקל באיזה גופן לא מקודד טוב כי המפתחות של הספר יצאו בעייתיות וכן עוד כמה מקומות ספציפיים.
איך אני יכול לטפל בזה? אם כל הגופנים לא מסומנים באדום זה אומר שמבחינת התוכנה הכל תקין, נכון?!תודה רבה!!
-
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
זה לא יעזור כפי שכתבתי למעלה:
הא, חשבתי שאתה מתכוון רק בחינמי זה ככה.
משום מה הייצוא מאוקסס.
בכל אופן השתמשתי לבסוף בAXESPDF
נתן תוצאות יחסית מרשימות.
עדיין נראה שהוא נתקל באיזה גופן לא מקודד טוב כי המפתחות של הספר יצאו בעייתיות וכן עוד כמה מקומות ספציפיים.
איך אני יכול לטפל בזה? אם כל הגופנים לא מסומנים באדום זה אומר שמבחינת התוכנה הכל תקין, נכון?!תודה רבה!!
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
משום מה הייצוא מאוקסס.
ה"משום מה" הוא משום שזה גירסת נסיון
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
בכל אופן השתמשתי לבסוף בAXESPDF
יפה. זו תוכנה טובה, רק מאוד יקר.
איך אני יכול לטפל בזה? אם כל הגופנים לא מסומנים באדום זה אומר שמבחינת התוכנה הכל תקין, נכון?!
אני לא יודע, תצטרך לעבוד קצת
-
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
משום מה הייצוא מאוקסס.
ה"משום מה" הוא משום שזה גירסת נסיון
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
בכל אופן השתמשתי לבסוף בAXESPDF
יפה. זו תוכנה טובה, רק מאוד יקר.
איך אני יכול לטפל בזה? אם כל הגופנים לא מסומנים באדום זה אומר שמבחינת התוכנה הכל תקין, נכון?!
אני לא יודע, תצטרך לעבוד קצת
@yossiz כתב בשיפור בINFIX וייצוא לוורד:
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
משום מה הייצוא מאוקסס.
ה"משום מה" הוא משום שזה גירסת נסיון
הגרסה שיש לי מאוקטבת..
@one1010 כתב בשיפור בINFIX וייצוא לוורד:
בכל אופן השתמשתי לבסוף בAXESPDF
יפה. זו תוכנה טובה, רק מאוד יקר.
יש כאלו 'חופשיות' ברשת...
איך אני יכול לטפל בזה? אם כל הגופנים לא מסומנים באדום זה אומר שמבחינת התוכנה הכל תקין, נכון?!
אני לא יודע, תצטרך לעבוד קצת
כלומר? גם גופנים שאין בהם התראה על שיבוש לעבור אחד אחד?
תודה רבה!