
דרכים לדעת כיצד מידע מגיע לדפדפן
-
עד היום ידעתי שכשהדפדפן שולח בקשות לשרת מתבצע לוגינג אוטומטי אשר ניתן לראות אותו בעמודה Network ב-Chrome DevTools.
דוגמה מאתר תחומים:
(אני מניח שהפניות הראשונות מעבירות את המידע)
אומנם יש אתרים שראיתי שאין רישום מספיק כזה, ונראה שהם מקבלים מידע מערוצים אחרים.
דוגמא מאתר כל רגע

בדקתי את כל הפניות ולא מצאתי משהו שנראה רלוונטי לדאטא עצמו.שאלתי:
מהם הדרכים הנוספות שיש להעביר מידע לפדפן וכיצד ניתן לראות זאת.
(אציין שאני מודע למושג SPA, אבל גם שמדובר בעמוד אחד, בניווטים הפנימיים צריך למשוך חומר עם פניות לעולם החיצון) -
עד היום ידעתי שכשהדפדפן שולח בקשות לשרת מתבצע לוגינג אוטומטי אשר ניתן לראות אותו בעמודה Network ב-Chrome DevTools.
דוגמה מאתר תחומים:
(אני מניח שהפניות הראשונות מעבירות את המידע)
אומנם יש אתרים שראיתי שאין רישום מספיק כזה, ונראה שהם מקבלים מידע מערוצים אחרים.
דוגמא מאתר כל רגע
בדקתי את כל הפניות ולא מצאתי משהו שנראה רלוונטי לדאטא עצמו.שאלתי:
מהם הדרכים הנוספות שיש להעביר מידע לפדפן וכיצד ניתן לראות זאת.
(אציין שאני מודע למושג SPA, אבל גם שמדובר בעמוד אחד, בניווטים הפנימיים צריך למשוך חומר עם פניות לעולם החיצון)@yyy הצילומים שהבאת לא כל כך רלוונטים, הצילום של תחומים מכיל תקשורת ווב סוקט (שזו לא פניה רגילה), ופניות לשרתי נטפרי בלי אימות. והצילום מקול רגע מכיל פניה לגוגל אנליטיקס וכן פניה לנטפרי.
תסביר מה בדיוק אתה רוצה להבין, איך שולחים AJAX והשרת יודע לאמת את זהות השולח?
-
@yyy הצילומים שהבאת לא כל כך רלוונטים, הצילום של תחומים מכיל תקשורת ווב סוקט (שזו לא פניה רגילה), ופניות לשרתי נטפרי בלי אימות. והצילום מקול רגע מכיל פניה לגוגל אנליטיקס וכן פניה לנטפרי.
תסביר מה בדיוק אתה רוצה להבין, איך שולחים AJAX והשרת יודע לאמת את זהות השולח?
@יוסף-בן-שמעון
אני רוצה לדעת איפה רואים את המידע שעובר.
שאני שולח בקשה אני רגיל לקבל ג'ייסון עם נתונים. איפה אני רואה אותם לדוגמא באתר שציינתי? -
@יוסף-בן-שמעון
אני רוצה לדעת איפה רואים את המידע שעובר.
שאני שולח בקשה אני רגיל לקבל ג'ייסון עם נתונים. איפה אני רואה אותם לדוגמא באתר שציינתי?@yyy כוונתך לזה?
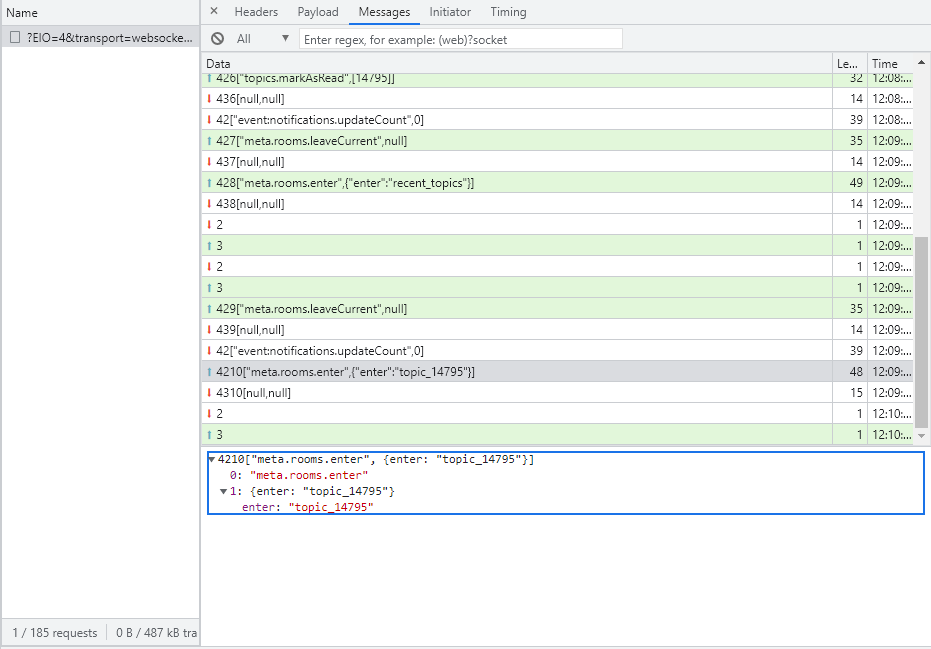
-
עד היום ידעתי שכשהדפדפן שולח בקשות לשרת מתבצע לוגינג אוטומטי אשר ניתן לראות אותו בעמודה Network ב-Chrome DevTools.
דוגמה מאתר תחומים:
(אני מניח שהפניות הראשונות מעבירות את המידע)
אומנם יש אתרים שראיתי שאין רישום מספיק כזה, ונראה שהם מקבלים מידע מערוצים אחרים.
דוגמא מאתר כל רגע
בדקתי את כל הפניות ולא מצאתי משהו שנראה רלוונטי לדאטא עצמו.שאלתי:
מהם הדרכים הנוספות שיש להעביר מידע לפדפן וכיצד ניתן לראות זאת.
(אציין שאני מודע למושג SPA, אבל גם שמדובר בעמוד אחד, בניווטים הפנימיים צריך למשוך חומר עם פניות לעולם החיצון)@yyy כתב בדרכים לדעת כיצד מידע מגיע לדפדפן:
דוגמא מאתר כל רגע
מי אמר לך שהגיע מידע חדש מהשרת לדפדפן?
בדיוק כפי שחשבת, אין דרך בעולם לדף לקבל מידע חיצוני בלי שיהיה רישום על כך בNETWORK.
במקרה של WebSocket אז יכולה להיות תקשורת ארוכה שבNetwork מסתכמת בשורה אחת (כפי שהראה @יוסף-בן-שמעון יש איפה לראות את התוכן). בכל-רגע זה לא המקרה, כך שלא ברור איזה מידע סברת שמגיע למרות שאיננו נרשם. -
@יוסף-בן-שמעון
אני רוצה לדעת איפה רואים את המידע שעובר.
שאני שולח בקשה אני רגיל לקבל ג'ייסון עם נתונים. איפה אני רואה אותם לדוגמא באתר שציינתי?@yyy כתב בדרכים לדעת כיצד מידע מגיע לדפדפן:
שאני שולח בקשה אני רגיל לקבל ג'ייסון עם נתונים.
אני כעת מבין את שאלתך.
אתה הגעת לעולם הפיתוח דרך SPA של אנגולר או משהו דומה, ולכן אתה בטוח שבכל אתר קיום הנתונים על הדף בהכרח מעיד על בקשת HTTP במהלך חיי הדף אחרי טעינתו הראשונית.
(SPA = אפליקציית דף בודד. כל הבקשות מנותבות בסוף לindex.html שעושה ניסים ונפלאות באמצעות בקשור HTTP לbackend/API).
אבל גם כיום רוב אתרי העולם הם לא SPA. והדף מגיע מהשרת עם כל הנתונים שלו. תוכל לעשות קליק ימני (בכל-רגע) ו"הצג מקור" ולראות את כל הנתונים. זה נקרא רנדור צד שרת.
(לאנגולר ולריאקט ועוד מנועי צד לקוח יש אפשרות לשלב רנדור צד שרת כדי לחסוך זמן טעינה ראשונה).