
עזרה בביטוי רגולארי
-
יש לי טקסט בפורמט מדיה ויקי, ואני צריך לשמור טקסט שנמצא בתוך תבנית בשם "הערה" במילון ולהכניס בטקסט עצמו את המפתח, הבעיה מתחילה כשיש בתוך התבנית פרמטר שהוא תבנית נוספת, לדוג':
{{הערה|{{אישי ישראל|רבי אברהם יצחק משכיל לאיתן}}.}}איך אני יכול לתפוס את התבנית כולה?
יצויין שיכולות להיות רמות קינון עמוקות יותר. -
REGEX לא טוב לביטויים רקורסיביים.
HTML המפורסמת היא בעצם תבנית רקורסיבית, אם תכתוב בגוגל regex html תקבל כמה שיעורי השקפה בנושא.
באיזה שפה אתה כותב? אתה צריך לעשות חיפוש של {{ הראשון, ומשמה להעלות מונה כל פעם באיתור ולהפחית כל פעם שיש }}. כשאתה מגיע ל0 אתה צריך לעצור, כי קיבלת את כל הביטוי.
יש עוד דרכים יפות לעשות זאת, REGEX לא מתאים (אלא"כ משלבים אותו עם לולאה).- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
אני חייב לציין שתשובתי לא כנה לגמרי,
כפי שהעירו לי בפרטי יש דרכים בREGEX להתמודד עם רקורסיביות וידעתי זאת,
אלא שא. זה לא מומלץ וזה עניתי נכון, ב. אני לא יודע להשתמש בזה - וזה כבר "נגיעה" בתשובה שלי.
אני שם כאן מ"מ לספורטיביים:
https://stackoverflow.com/questions/17003799/what-are-regular-expression-balancing-groups -
REGEX לא טוב לביטויים רקורסיביים.
HTML המפורסמת היא בעצם תבנית רקורסיבית, אם תכתוב בגוגל regex html תקבל כמה שיעורי השקפה בנושא.
באיזה שפה אתה כותב? אתה צריך לעשות חיפוש של {{ הראשון, ומשמה להעלות מונה כל פעם באיתור ולהפחית כל פעם שיש }}. כשאתה מגיע ל0 אתה צריך לעצור, כי קיבלת את כל הביטוי.
יש עוד דרכים יפות לעשות זאת, REGEX לא מתאים (אלא"כ משלבים אותו עם לולאה).@dovid כתב בעזרה בביטוי רגולארי:
REGEX לא טוב לביטויים רקורסיביים.
"לא טוב" זו הגדרה עדינה...
https://stackstatus.tumblr.com/post/147710624694/outage-postmortem-july-20-2016
https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019/
https://www.crowdstrike.com/wp-content/uploads/2024/08/Channel-File-291-Incident-Root-Cause-Analysis-08.06.2024.pdfמבחינתי Regex הוא כמו אנטיביוטיקה, אני משתמש בו בזהירות רק כשאין לי ברירה.
-
יש לי טקסט בפורמט מדיה ויקי, ואני צריך לשמור טקסט שנמצא בתוך תבנית בשם "הערה" במילון ולהכניס בטקסט עצמו את המפתח, הבעיה מתחילה כשיש בתוך התבנית פרמטר שהוא תבנית נוספת, לדוג':
{{הערה|{{אישי ישראל|רבי אברהם יצחק משכיל לאיתן}}.}}איך אני יכול לתפוס את התבנית כולה?
יצויין שיכולות להיות רמות קינון עמוקות יותר.@האדם-החושב
זה יפה שכולם פיענחו מה אתה רוצה לי זה לקח קצת זמן עד שקלטתי שאני צריך לקרוא את מה שכתבת בפנים בקונטקסט של הכותרת ולנחש שבעצם אתה שואל איך לעשות רגקס שיפתור את הבעיה.
אתה כותב הבעיה מתחילה מבלי לפרט מה עשית לפני שהבעיה התחילה.אישית לא הייתי שואל ככה אלא איך לפתור את הבעיה והאם רגקס הוא כיוון טוב.
-
לגופו של עניין:
אין לי היכרות עם מדיה-ויקי או עם הפורמט שלו, והמשמעות של הנקודה ושל ה-"|" אינן ברורות לי דיו. עם זאת, אני מניח שמדובר בפורמט מסודר עם כללים, ואם תלמד איך הוא בנוי, אני בטוח שתוכל לנתח כל טקסט בסגנון הזה די בקלות הכל שאלה של כמה זמן אתה מוכן להשקיע.אם נתעלם לרגע מהנקודה ומה-"|", נוכל להשתמש בשילוב של רג'קס וקוד רקורסיבי עם מבנה נתונים פשוט (@dovid רמז לזה כבר).
אבל חשוב לציין שזה בהנחה שהטקסט לא מכיל שגיאות או אי-עקביות – אחרת זה כאב ראש * 20.
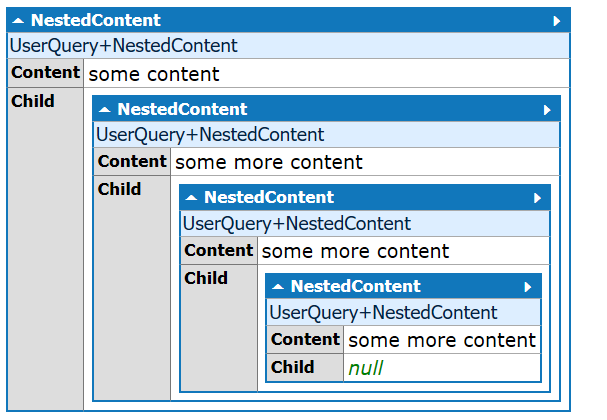
להלן דוגמא ב-C# שהזנתי ל-LinqPad, הקוד הינו סקיצה בעלמא תוכל לשפר אותו כיד ה' הטובה עליך:void Main() { string content = "{{some content{{some more content{{some more content{{some more content}}}}}}}}"; var root = new NestedContent(content, null); root.Dump(); // Dump the root object to view its structure } class NestedContent { public string Content { get; set; } public NestedContent Child { get; set; } public NestedContent(string content, NestedContent parent) { // Trim only the outermost braces (single pair at start and end) if (content.StartsWith("{{") && content.EndsWith("}}")) { content = content.Substring(2, content.Length - 4); } var match = Regex.Match(content, @"\{\{.*\}\}"); if (match.Success) { string nestedContent = match.Value; this.Content = content.Replace(nestedContent, ""); // Replace inner braces content Child = new NestedContent(nestedContent, this); // Recursive call for nested content } else { this.Content = content; // Set content when no more nested structures } } }והתוצאה:
-
תודה לכל העונים.
בפועל השתמשתי בספריית mwparserfromhellimport re import mwparserfromhell def filter_templates(string): string_2 = [] parsed = mwparserfromhell.parse(string) templates = parsed.filter_templates(parsed.RECURSE_OTHERS) if templates: for template in templates: if template.params: template_str = "".join([str(param) for param in template.params]) else: template_str = "" string_2.append([str(template),template.name, template_str]) return string_2 else: return False def clean_comment(comment): while True: replace = filter_templates(comment) if not replace: break for i in replace: rp = i[2] comment = comment.replace(i[0], rp) return comment def remove_templates(wikitext): dict_comments = {} sup = 0 while True: replace = filter_templates(wikitext) if not replace: break for i in replace: if i[1].strip() == "הערה": sup += 1 dict_comments[sup] = clean_comment(i[2]) rp = f'<sup style="color: gray;">{sup}</sup>' elif i[1].strip() == "ש": rp = "\n" else: rp = i[2] wikitext = wikitext.replace(i[0], rp) counter = 0 sorted_dict = {} for num in re.findall(r'<sup style="color: gray;">(\d+)</sup>', wikitext): counter += 1 wikitext = wikitext.replace(rf'<sup style="color: gray;">{num}</sup>', rf'<sup style="color: gray;">{counter}</sup>') sorted_dict[counter] = dict_comments[int(num)] return wikitext, sorted_dict -
@האדם-החושב זה הכי טוב.
האם אתה רוצה הערות על הקוד?- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
@האדם-החושב זה הכי טוב.
האם אתה רוצה הערות על הקוד?@dovid
אשמח. -
א. בשלושת הפונקציות, אתה בודק האם האובייקט ריק (כל הif בקוד, כולם). זה מיותר, אתה יכול ישירות לבצע את הפעולה, אם הוא ריק תהיה תוצאה ריקה ואפס סיבובים בלולאה
ב. בפונקציה filter_templates אתה משתמש בלולאת for אלגנטית. בשני הפונקציות האחרות אתה משתמש בwhile, אתה יכול להשתמש באותה לולאת for
ג. בפונקציה filter_templates אתה אוסף את התוצאות לתוך מערך (או list לא יודע איך קוראים לזה בפייתון)
אתה יכול להשתמש עם yield, זה פשוט מזין כל תוצאה בתורה ללולאת for שאתה כותב בפונקציה הקוראתדוגמה לקוד של filter_templates אחרי התיקונים הנ"ל:
def filter_templates(string): parsed = mwparserfromhell.parse(string) for template in parsed.filter_templates(parsed.RECURSE_OTHERS): template_str = "".join([str(param) for param in template.params]) yield [str(template), template.name.strip(), template_str]כמו"כ כדאי להשתמש עם אובייקטים במקום מערך בתוצאה, משהו כזה:
def filter_templates(string): parsed = mwparserfromhell.parse(string) for template in parsed.filter_templates(parsed.RECURSE_OTHERS): template_str = "".join(map(str, template.params)) yield { "template": str(template), "name": template.name.strip(), "template_str": template_str, }ובקוד המשתמש צריך לפנות לi["name"] במקום למיקום מספרי.
לגופה של לוגיקה אני אל יודע בדיוק אם הקוד עושה מה שצריך, זה אתה יכול לבדוק יותר טוב ממני.