
שאלה: מה הסוד מאחורי מנוע החיפוש של בר אילן? (מבחינת תיכנות)
-
-
גם לבר אילן יש אינדקס מאחורי הקלעים
@יוסף-בן-שמעון
אוקיי שיערת לעצמי אבל ה לא פותר את הבעיה כי אינדקס לא יכול לייצר גזירים רק להצביע היכן קיממים מילים מסויימים -
-
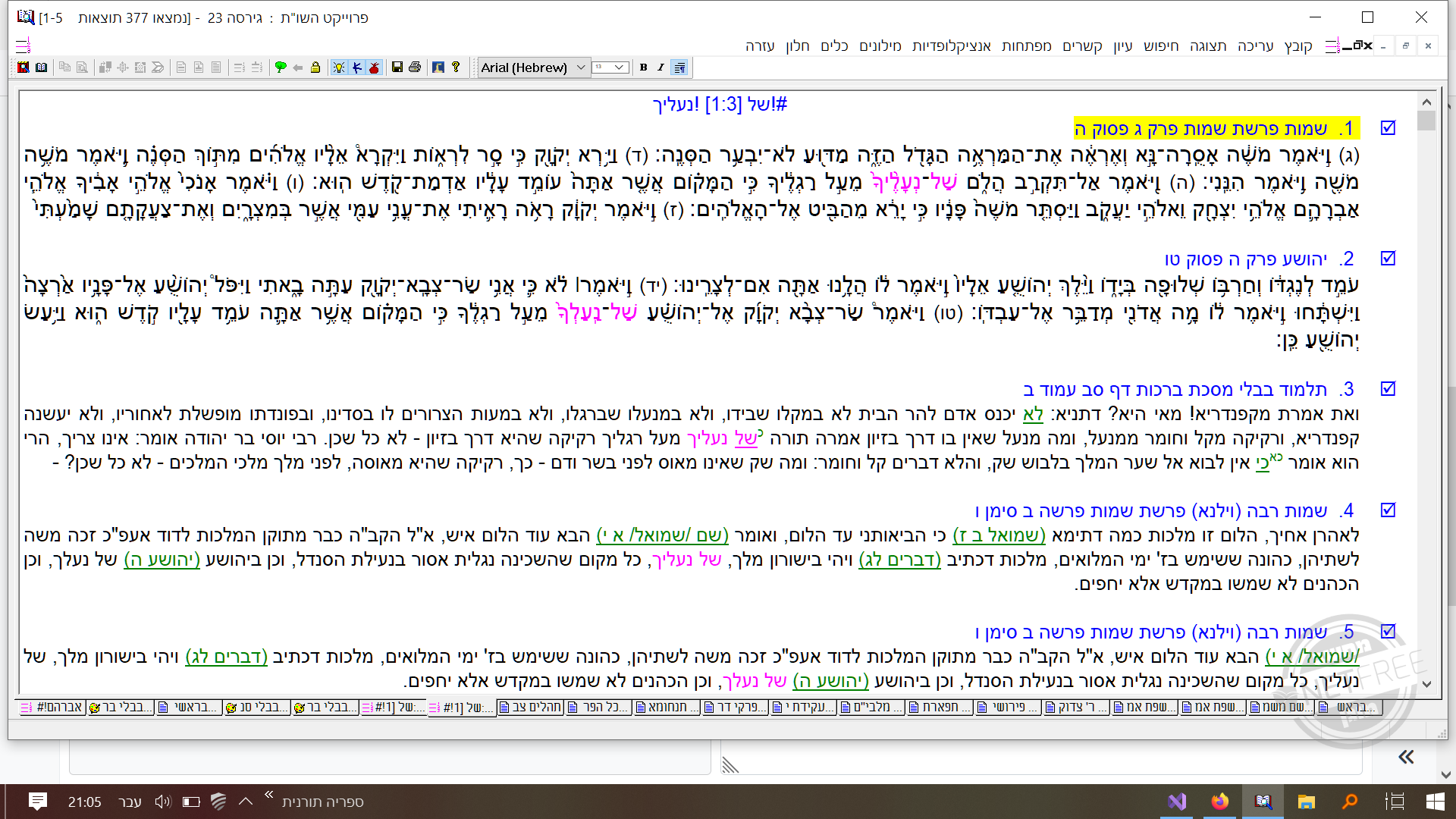
אתה מדבר על צורת הדף והכתבי עת?
@יוסף-בן-שמעון
אני מדבר על זה
-
זה טקסט נקי, אתה קודם שולף מהאינדקס את המיקום של המילים האלו, ניגש לטבלאות הרלוונטיות, שולף מהם את השורות מהמיקום שיש לך, עוטף את המילים של ביטוי החיפוש בוורוד, ומציג את הרשימה. כך בעיקרון עובד כל אינדקס.
כשעושים חיפוש בתמונות סרוקות כמו צורת הדף וכתבי עת, זה קצת שונה, כי אתה לא מחזיק טקסט אלא תמונה, האינדקס יכול רק להצביע לך איפה ממוקם קובץ התמונה, ואז אתה צריך לעשות לו OCR כדי לזהות את המילים ולצבוע אותם. אם כי מסתבר שכל תמונה מחזיקה כבר את ה OCR במטמון וזה לא נעשה בלייב.
-
קודם כל תודה על ההיענות
"ניגש לטבלאות הרלוונטיות" - תוכל לפרט קצת יותר?
ומה ההבדל בין זה לחיפוש ישיר בכל החומר? רק סינון קבצים לא רלוונטיים? אז אם יש הרבה תוצאות מה? -
נניח שיש טבלה של תנך, טבלה של גמרא טבלה של ראשונים וכו'.
האינדקס החזיר שביטוי החיפוש מופיע בתנך בשורה 8947 ובגמרא בשורה 749
האפליקציה ניגשת לטבלאות האלו, שולפת את השורות הרצויות, מסתמא גם שולפת אחת לפני ואחת אחרי בשביל התצוגה, ומוסיפה את זה למערך של תוצאות החיפוש.
אם היא היתה מחפשת את הביטוי הזה בכל הטבלאות של התנך והגמרא והראשונים, בלי להעזר באינדקס, היה לוקח המון זמן לכל חיפוש, האינדקס מקצר את התהליך -
שומע אבל אני תוהה כי אם כך אז תחת כל ערך יש כמות מטורפת של 'שורות' והאינדקסר צריך לחשב את כל זה....
כמו"כ האינדקס עצמו יהיה מאוד ארוך כך שלכאורה הטעינה שלו תהיה מאוד איטית... ( זה אולי אפשר לעשות לפצל את האיננדקס לפי אותיות ראשוות של מילים).
-
@pcinfogmach אינדקס זה צורת ארגון של מידע שמקילה על המחשב בצורה דרמטית איתור של חלקים.
המילים שלך ש"אפשר לפצל את האינדקס לפי מילים" שגויות, עצם המיון הוא פיצול מעולה, כי מאוד קל ברשימה ממויינת למצוא את האיבר המתאים, זה נקרא חיפוש בינארי או "אריה במדבר".
במקרה של מאגרי טקסט משתמשים באינקסים מתאימים, אני מציין מראה מקום https://en.wikipedia.org/wiki/Inverted_index.
לא צריך לטעון את האינדקס, זה יכול להיות כתוב בקובץ והסריקה יכולה להיות ישירות מהדיסק.
מאגרי טקסט זה לא אינדקוס רגיל, כי אתה בעצןם לא צופה מה יחפשו. במקרה של בר אילן למשל אז אפשר לחפש הן תחיליות הן סיומים וכדומה וממילא אפילו אינדקס מילים אינו יעיל, יש שיטות רבות לאינדקסים לפי השימושים. אני מתאר לעצמי שאפשר למשל לעשות אינדוקס של כל הרצפים של שני אותיות. יש סה"כ 22*22 כאלו, בכל אחד יש רשימה של ספרים ובתוך כל ספר רשימת מיקומים. כשיש בביטוי שלושה אותיות רצופות בודקים חפיפה של מיקומי שני זוגות האותיות.- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
@pcinfogmach אינדקס זה צורת ארגון של מידע שמקילה על המחשב בצורה דרמטית איתור של חלקים.
המילים שלך ש"אפשר לפצל את האינדקס לפי מילים" שגויות, עצם המיון הוא פיצול מעולה, כי מאוד קל ברשימה ממויינת למצוא את האיבר המתאים, זה נקרא חיפוש בינארי או "אריה במדבר".
במקרה של מאגרי טקסט משתמשים באינקסים מתאימים, אני מציין מראה מקום https://en.wikipedia.org/wiki/Inverted_index.
לא צריך לטעון את האינדקס, זה יכול להיות כתוב בקובץ והסריקה יכולה להיות ישירות מהדיסק.
מאגרי טקסט זה לא אינדקוס רגיל, כי אתה בעצןם לא צופה מה יחפשו. במקרה של בר אילן למשל אז אפשר לחפש הן תחיליות הן סיומים וכדומה וממילא אפילו אינדקס מילים אינו יעיל, יש שיטות רבות לאינדקסים לפי השימושים. אני מתאר לעצמי שאפשר למשל לעשות אינדוקס של כל הרצפים של שני אותיות. יש סה"כ 22*22 כאלו, בכל אחד יש רשימה של ספרים ובתוך כל ספר רשימת מיקומים. כשיש בביטוי שלושה אותיות רצופות בודקים חפיפה של מיקומי שני זוגות האותיות.inverted index זה אידקס מילים עם רשימה של מיקומים בה הוא מופיע. די פשוט. וכנ"ל.
לעת עתה חיפוש פשוט זה מספיק לי
@dovid כתב בשאלה: מה הסוד מאחורי מנוע החיפוש של בר אילן? (מבחינת תיכנות):
לא צריך לטעון את האינדקס, זה יכול להיות כתוב בקובץ והסריקה יכולה להיות ישירות מהדיסק.
באיזה קובץ מדובר שאפשר לסרוק אותו ישירות מהדיסק?
-
נניח שיש טבלה של תנך, טבלה של גמרא טבלה של ראשונים וכו'.
האינדקס החזיר שביטוי החיפוש מופיע בתנך בשורה 8947 ובגמרא בשורה 749
האפליקציה ניגשת לטבלאות האלו, שולפת את השורות הרצויות, מסתמא גם שולפת אחת לפני ואחת אחרי בשביל התצוגה, ומוסיפה את זה למערך של תוצאות החיפוש.
אם היא היתה מחפשת את הביטוי הזה בכל הטבלאות של התנך והגמרא והראשונים, בלי להעזר באינדקס, היה לוקח המון זמן לכל חיפוש, האינדקס מקצר את התהליך@יוסף-בן-שמעון כתב בשאלה: מה הסוד מאחורי מנוע החיפוש של בר אילן? (מבחינת תיכנות):
האפליקציה ניגשת לטבלאות האלו, שולפת את השורות הרצויות, מסתמא גם שולפת אחת לפני ואחת אחרי בשביל התצוגה, ומוסיפה את זה למערך של תוצאות החיפוש.
לכאורה לעבוד על בסיס שורות זה בעיה כי אם מילה א של החיפוש נמצא בשורה א ומילה ב בשורה ב אז מה נעשה? נגדיר את החיפוש שידע לעבד כזה מצב או שיש פתרון יותר פשוט?
-
@pcinfogmach יש מושג של קובץ עם גישה אקראית.
זה קובץ רגיל אבל בו חתיכות הנתונים נמצאים או במרחק קבוע או במרחק משתנה אבל עם תיעוד בקובץ אחר (כמו אינדקס).
בכזה קובץ פשוט קוראים את הקובץ בבינארית, ומתקדמים כל פעם "חתיכה" ומעבדים אותה בלי צורך בטעינת כל הקובץ.
למשל שורות במסמך טקסט הם חלוקה שמתבררת רק אחרי קריאה מהתו הראשון, אין שום אפשרות להתחיל לקרוא קובץ החל משורה 5 בלי לקרוא את את החלק שעד שם כדי לוודא כמה שורות ישנם. אבל אם יש אינדקס של שורות, אז אפשר לקרוא ישירות שורה 5245 בלי לטעון אפילו תו מיותר.- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
@pcinfogmach יש מושג של קובץ עם גישה אקראית.
זה קובץ רגיל אבל בו חתיכות הנתונים נמצאים או במרחק קבוע או במרחק משתנה אבל עם תיעוד בקובץ אחר (כמו אינדקס).
בכזה קובץ פשוט קוראים את הקובץ בבינארית, ומתקדמים כל פעם "חתיכה" ומעבדים אותה בלי צורך בטעינת כל הקובץ.
למשל שורות במסמך טקסט הם חלוקה שמתבררת רק אחרי קריאה מהתו הראשון, אין שום אפשרות להתחיל לקרוא קובץ החל משורה 5 בלי לקרוא את את החלק שעד שם כדי לוודא כמה שורות ישנם. אבל אם יש אינדקס של שורות, אז אפשר לקרוא ישירות שורה 5245 בלי לטעון אפילו תו מיותר.@dovid
תודה
קראתי על זה אבל לא הצלחתי להבין בדיוק איך יוצרים כזה קובץ
הלוואי שיה דרך ליצור קובץ טבלאי בלתי מוגבל או משהו כזה -
שוב, הבעיה זה לא היצירה (כל קובץ ניתן לקריאה בצורה אקראית), אלא שהוא יהיה כתוב באופן שלקריאה אקראית תהיה בעלת משמעות. בקובץ רגיל אין משמעות לקריאה לא סדרתית, זה יביא חרבושים כי הכל מבוסס על שרשרת שתחילתה בראש הקובץ. בקובץ אקראי מקפידים שיהיה קביעות במיקומים, לשם המשל שכל שורה תתחיל במספר עגול של כל 3000 בתים.
(אם יש לך שאלה מעשית - ולא המשך של השאלה הרעיונית שיש בנושא זה - שאל אותה בנושא קונקרטי עבורה).- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
שוב, הבעיה זה לא היצירה (כל קובץ ניתן לקריאה בצורה אקראית), אלא שהוא יהיה כתוב באופן שלקריאה אקראית תהיה בעלת משמעות. בקובץ רגיל אין משמעות לקריאה לא סדרתית, זה יביא חרבושים כי הכל מבוסס על שרשרת שתחילתה בראש הקובץ. בקובץ אקראי מקפידים שיהיה קביעות במיקומים, לשם המשל שכל שורה תתחיל במספר עגול של כל 3000 בתים.
(אם יש לך שאלה מעשית - ולא המשך של השאלה הרעיונית שיש בנושא זה - שאל אותה בנושא קונקרטי עבורה).@dovid כתב בשאלה: מה הסוד מאחורי מנוע החיפוש של בר אילן? (מבחינת תיכנות):
(אם יש לך שאלה מעשית - ולא המשך של השאלה הרעיונית שיש בנושא זה - שאל אותה בנושא קונקרטי עבורה).
זה שאלה מאוד מעשית אני בקשר עם קבוצה של אנשים שמנסים ליצור תוכנה תורנית חדשה שתכלול את כל הספרים הכשרים מספריא ושתתן ממשק קצת יותר נוח מ"תורת אמת".
הבעיה היא שאין לאף מושג איך ליצור את הפונקציה של החיפוש. הרבה דברים נוסו ולבינתיים ללא הועיל. אם תוכל להדריך אותנו בנושא זה מאוד יעזור.התוכנה כעת בפיתוח בשפת c#
מצו"ב תמונה (למרות שזה ממש באמצע העבודה - לשם האמינות)
יש לנו עוד פרוייקט בשלב יותר מתקדם - תוסף תורת אמת בוורד
שם לבינתיים אילתרנו משהו אבל אם כבר שם נוכל לעשות מנוע חיפוש זה יהיה כמעט מושלם.
-
@dovid כתב בשאלה: מה הסוד מאחורי מנוע החיפוש של בר אילן? (מבחינת תיכנות):
(אם יש לך שאלה מעשית - ולא המשך של השאלה הרעיונית שיש בנושא זה - שאל אותה בנושא קונקרטי עבורה).
זה שאלה מאוד מעשית אני בקשר עם קבוצה של אנשים שמנסים ליצור תוכנה תורנית חדשה שתכלול את כל הספרים הכשרים מספריא ושתתן ממשק קצת יותר נוח מ"תורת אמת".
הבעיה היא שאין לאף מושג איך ליצור את הפונקציה של החיפוש. הרבה דברים נוסו ולבינתיים ללא הועיל. אם תוכל להדריך אותנו בנושא זה מאוד יעזור.התוכנה כעת בפיתוח בשפת c#
מצו"ב תמונה (למרות שזה ממש באמצע העבודה - לשם האמינות)
יש לנו עוד פרוייקט בשלב יותר מתקדם - תוסף תורת אמת בוורד
שם לבינתיים אילתרנו משהו אבל אם כבר שם נוכל לעשות מנוע חיפוש זה יהיה כמעט מושלם.
@pcinfogmach כתב בשאלה: מה הסוד מאחורי מנוע החיפוש של בר אילן? (מבחינת תיכנות):
זה שאלה מאוד מעשית
(הסר דאגה. להבנתי @dovid לא התכוון לאסור עליך לדבר על הנושא הרעיוני, אלא ציין שכאשר תהיה שאלה מעשית, תפתח עליה נושא חדש ולא תמשיך בשרשור הזה.)