פיצוח קאפצ'ה
-
אתמול יצא לי לכתוב קוד לפצח קאפצ'ה של אתר מסויים. (אני לא נכנס כרגע לשיקולי אתיקה...).
מכיון שנהניתי מאוד מהקלות וההצלחה רציתי לשתף את החברים...קאפצה לדוגמה:

ועוד אחד:

הרעיון ברור - 4 ספרות, קשקוש אחד או שניים ש(אמורים ל)עבור תוך הספרות, וזריית קצת פלפל שחור לשם קינוח.
 אגב, מעניין לדעת מי יוצר הקאפצ'ה? במקרה שלי מדובר באתר ASP .NET ושימוש בקומפוננט מחברת telerik בשם RadCaptcha. ראיתי במקום אחר שיש להם קאפצ'ות יותר מסובכות, אני לא יודע אם פה מדובר בגירסה ישנה או בהגדרות שונות.
אגב, מעניין לדעת מי יוצר הקאפצ'ה? במקרה שלי מדובר באתר ASP .NET ושימוש בקומפוננט מחברת telerik בשם RadCaptcha. ראיתי במקום אחר שיש להם קאפצ'ות יותר מסובכות, אני לא יודע אם פה מדובר בגירסה ישנה או בהגדרות שונות.איך נפצח את זה?
א) ננקה את התמונה עד כמה שנוכל,
ב) נשתמש בספריית OCR כלשהו לקרוא את התוכן של התמונה הנקייה.
השפה המועדפת עלי כרגע הוא JS.איך מנקים את התמונה?
אם ננסה למצוא מכנה משותף לשני סוגי ה"רעשים" (דהיינו הנקודות והקשקוש) שלא נמצא בחלק שאנחנו רוצים לשמור, קל לשים לב שהרעש דק יותר מהספרות. אז יש לנו אסטרגיה פשוטה: שהתמונה תעבור דיאטה, כלומר, נמצא דרך לדלל את הכל החלק השחור, כך שהרעש ייעלם ונישאר עם התוכן.
בתחום עיבוד תמונות דיגיטליות, הפעולה הזו של דיאטה נקרא dilate. הפעולה ההפוכה (השמנה) נקרא erode. בעצם זה הפוך, המשמעות של המילה dilate קשור להשמנה מכיון שהוא משמין את החלקים הלבנים, והמילה erode קשור לדילול מכיון שהוא מדלל את החלקים הלבנים. למה הפעולות מתייחסות לחלקים הלבנים? כי כידוע בגרפיקה דיגיטלית שחור הוא העדר צבע -- 0 ולבן הוא 255.טוב! הלאה לביצוע!
בחרתי בספרייה זו לשם עיבוד התמונה ובספרייה זו לשם ביצוע ה-OCR.
הנה שורת הקוד שמבצע את הניקוי:
const image = await Image.load(imageBuffer); const resultImage = image.grey().dilate().erode().mask();יש כאן כמה נקודות לשים לב אליהם:
- בייצוג הדיגיטלי של התמונה יש בברירת מחדל 4 ערוצים: RGBA, פעולות ה-dilate ו-erode אפשריים על ערוץ אחד בלבד, לשם כך קודם הופכים את התמונה לבעלת ערוץ אחד על ידי קריאה לפונקציית
grey. - פעולות dilate ו-erode מקבלות פרמטר של כמה פיקסלים להשמין אותו או להיפך בכמה פיקסלים לדלל אותו. השתמשתי בברירת המחדל שהוא פיקסל לכל צד.
- הפעולה האחרונה (
mask) נקרא גם threshold הוא פעולה שהופכת את כל האפור לשחור או לבן. פיקסל שעובר את אחוז החסימה נהיה לבן ואם לא הוא נהיה שחור. אני עושה את זה כי אחרי ה-dilate עדיין נשארים רשמים אפורים.
איך נראה התוצאה?

והשני:
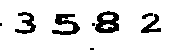
יפה!
עכשיו ל-OCR:
const { createWorker, PSM, OEM } = require('tesseract.js'); const worker = createWorker(); await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng', OEM.LSTM_ONLY); await worker.setParameters({ tessedit_char_whitelist: '0123456789', init_oem: OEM.LSTM_ONLY, tessedit_pageseg_mode: PSM.SINGLE_BLOCK, }); const res = await worker.recognize(resultBuffer); await worker.terminate(); console.log(res.data.text);נקודות לשימת לב:
- יש כמה פרמטרים שעוד לא למדתי את משמעותן ואולי יעזרו לשיפור הדיוק.
- הפרמטר העיקרית הוא:
tessedit_char_whitelist- כלומר רשימה לבנה של תווים מותרים. זה משפר את הדיוק מאוד.
התוצאה:
2964 3582מגניב! התוכנה הצליחה!
(יש עדיין טעויות בפחות מ-10% של המקרים. ויש עדיין מה לשפר בפרמטרים של ה-OCR).📧 יוסי@מייל.קום | 🌎 בלוג | ☕ קפה
👈 רוצים כתובת מייל בעברית? כנסו למייל.קום 👉 - בייצוג הדיגיטלי של התמונה יש בברירת מחדל 4 ערוצים: RGBA, פעולות ה-dilate ו-erode אפשריים על ערוץ אחד בלבד, לשם כך קודם הופכים את התמונה לבעלת ערוץ אחד על ידי קריאה לפונקציית
-
אתמול יצא לי לכתוב קוד לפצח קאפצ'ה של אתר מסויים. (אני לא נכנס כרגע לשיקולי אתיקה...).
מכיון שנהניתי מאוד מהקלות וההצלחה רציתי לשתף את החברים...קאפצה לדוגמה:
ועוד אחד:
הרעיון ברור - 4 ספרות, קשקוש אחד או שניים ש(אמורים ל)עבור תוך הספרות, וזריית קצת פלפל שחור לשם קינוח.
אגב, מעניין לדעת מי יוצר הקאפצ'ה? במקרה שלי מדובר באתר ASP .NET ושימוש בקומפוננט מחברת telerik בשם RadCaptcha. ראיתי במקום אחר שיש להם קאפצ'ות יותר מסובכות, אני לא יודע אם פה מדובר בגירסה ישנה או בהגדרות שונות.איך נפצח את זה?
א) ננקה את התמונה עד כמה שנוכל,
ב) נשתמש בספריית OCR כלשהו לקרוא את התוכן של התמונה הנקייה.
השפה המועדפת עלי כרגע הוא JS.איך מנקים את התמונה?
אם ננסה למצוא מכנה משותף לשני סוגי ה"רעשים" (דהיינו הנקודות והקשקוש) שלא נמצא בחלק שאנחנו רוצים לשמור, קל לשים לב שהרעש דק יותר מהספרות. אז יש לנו אסטרגיה פשוטה: שהתמונה תעבור דיאטה, כלומר, נמצא דרך לדלל את הכל החלק השחור, כך שהרעש ייעלם ונישאר עם התוכן.
בתחום עיבוד תמונות דיגיטליות, הפעולה הזו של דיאטה נקרא dilate. הפעולה ההפוכה (השמנה) נקרא erode. בעצם זה הפוך, המשמעות של המילה dilate קשור להשמנה מכיון שהוא משמין את החלקים הלבנים, והמילה erode קשור לדילול מכיון שהוא מדלל את החלקים הלבנים. למה הפעולות מתייחסות לחלקים הלבנים? כי כידוע בגרפיקה דיגיטלית שחור הוא העדר צבע -- 0 ולבן הוא 255.טוב! הלאה לביצוע!
בחרתי בספרייה זו לשם עיבוד התמונה ובספרייה זו לשם ביצוע ה-OCR.
הנה שורת הקוד שמבצע את הניקוי:
const image = await Image.load(imageBuffer); const resultImage = image.grey().dilate().erode().mask();יש כאן כמה נקודות לשים לב אליהם:
- בייצוג הדיגיטלי של התמונה יש בברירת מחדל 4 ערוצים: RGBA, פעולות ה-dilate ו-erode אפשריים על ערוץ אחד בלבד, לשם כך קודם הופכים את התמונה לבעלת ערוץ אחד על ידי קריאה לפונקציית
grey. - פעולות dilate ו-erode מקבלות פרמטר של כמה פיקסלים להשמין אותו או להיפך בכמה פיקסלים לדלל אותו. השתמשתי בברירת המחדל שהוא פיקסל לכל צד.
- הפעולה האחרונה (
mask) נקרא גם threshold הוא פעולה שהופכת את כל האפור לשחור או לבן. פיקסל שעובר את אחוז החסימה נהיה לבן ואם לא הוא נהיה שחור. אני עושה את זה כי אחרי ה-dilate עדיין נשארים רשמים אפורים.
איך נראה התוצאה?
והשני:
יפה!
עכשיו ל-OCR:
const { createWorker, PSM, OEM } = require('tesseract.js'); const worker = createWorker(); await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng', OEM.LSTM_ONLY); await worker.setParameters({ tessedit_char_whitelist: '0123456789', init_oem: OEM.LSTM_ONLY, tessedit_pageseg_mode: PSM.SINGLE_BLOCK, }); const res = await worker.recognize(resultBuffer); await worker.terminate(); console.log(res.data.text);נקודות לשימת לב:
- יש כמה פרמטרים שעוד לא למדתי את משמעותן ואולי יעזרו לשיפור הדיוק.
- הפרמטר העיקרית הוא:
tessedit_char_whitelist- כלומר רשימה לבנה של תווים מותרים. זה משפר את הדיוק מאוד.
התוצאה:
2964 3582מגניב! התוכנה הצליחה!
(יש עדיין טעויות בפחות מ-10% של המקרים. ויש עדיין מה לשפר בפרמטרים של ה-OCR).@yossiz אמר בפיצוח קאפצ'ה:
מגניב! התוכנה הצליחה!
באותה שעה אמרו: וי לקאפצה שפגע בה @yossiz ...
ישר כח על ההסבר, זה נראה כל כך קל כשאתה מסביר את זה, וגם על הדרך למדנו על OCR ועיבוד תמונה.
מבלי לגרוע ח"ו מהשיטה הנפלאה, אני קצת מתפלא על הקאפצ'ה העלוב. יש היום דברים שאני בקושי מצליח לפענח (אולי אני רובוט?) - בייצוג הדיגיטלי של התמונה יש בברירת מחדל 4 ערוצים: RGBA, פעולות ה-dilate ו-erode אפשריים על ערוץ אחד בלבד, לשם כך קודם הופכים את התמונה לבעלת ערוץ אחד על ידי קריאה לפונקציית
-
@yossiz אמר בפיצוח קאפצ'ה:
מגניב! התוכנה הצליחה!
באותה שעה אמרו: וי לקאפצה שפגע בה @yossiz ...
ישר כח על ההסבר, זה נראה כל כך קל כשאתה מסביר את זה, וגם על הדרך למדנו על OCR ועיבוד תמונה.
מבלי לגרוע ח"ו מהשיטה הנפלאה, אני קצת מתפלא על הקאפצ'ה העלוב. יש היום דברים שאני בקושי מצליח לפענח (אולי אני רובוט?)@odeddvir אמר בפיצוח קאפצ'ה:
באותה שעה אמרו: וי לקאפצה שפגע בה @yossiz ...
מצחיק, אבל אתה צודק, זה קאפצ'ה די עלוב. מזל שלי.
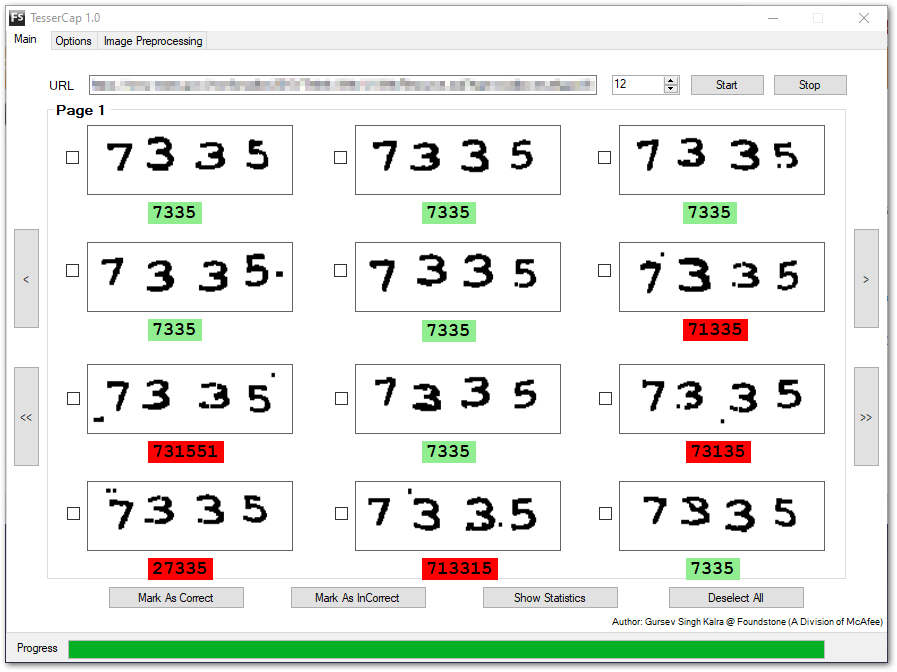
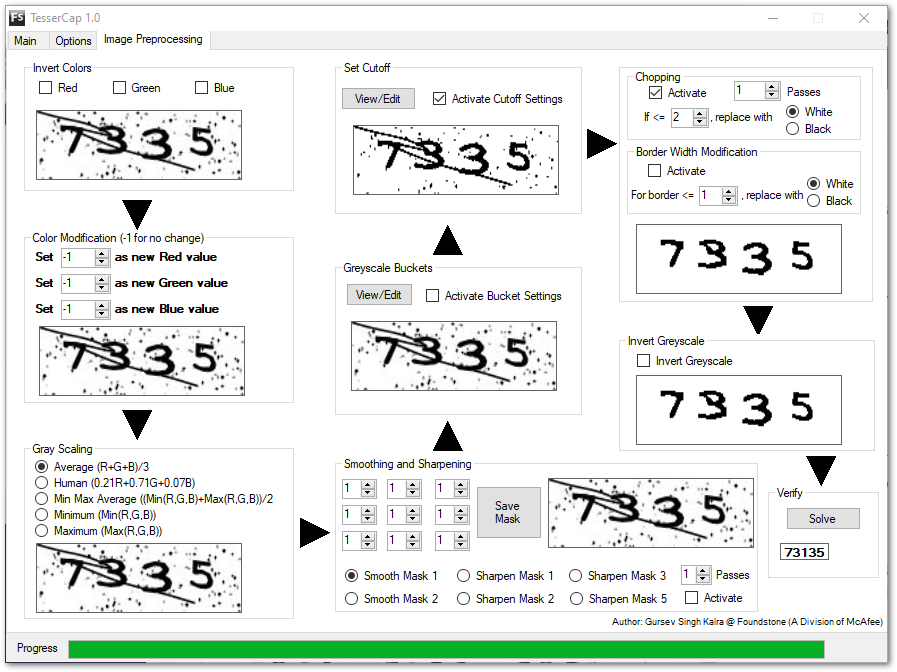
אגב, נתקלתי במחקר של חברת mcafee (משנת 2011) שטוענת שיותר מדי קאפצ'רים חלשים מדי. עורך המחקר גם שחרר כלי חינמי לפיצווח קאפצ'ות:
https://github.com/gursev/TesserCap📧 יוסי@מייל.קום | 🌎 בלוג | ☕ קפה
👈 רוצים כתובת מייל בעברית? כנסו למייל.קום 👉 -
@odeddvir אמר בפיצוח קאפצ'ה:
באותה שעה אמרו: וי לקאפצה שפגע בה @yossiz ...
מצחיק, אבל אתה צודק, זה קאפצ'ה די עלוב. מזל שלי.
אגב, נתקלתי במחקר של חברת mcafee (משנת 2011) שטוענת שיותר מדי קאפצ'רים חלשים מדי. עורך המחקר גם שחרר כלי חינמי לפיצווח קאפצ'ות:
https://github.com/gursev/TesserCap