
מה זה ליסט בדוט נט
-
תמיד חשבתי שליסט של דוטנט בנוי בצורה הכי טוב שיכול להיות, אבל היום שנוכחתי לדעת שהביצועים שלו נהיים מאוד גרועים במעל כמה מאות אלפי פריטים החלטתי לבדוק איך הוא בנאי לעומק
פתחתי אותו ברפלקטור ונדהמתי לגלות שהוא בעצם בנוי על בסיס מערך רגיל שכל הזמן גודל וכל פעם מקצים מחדש מערך רגיל קצת יותר גדול ומעתיקים מהישן לחדש !! זה פשוט בזבוז נורא למה לא בנו את זה כמו שמתואר כאן ??
אבל אולי בכל זאת יש איזה מחלקה בדוט נט שעובדת כמו בקישור שלעיל ?
או אולי מישהו יפקח את עיני בעינין זה?
תודה לכולם.פורסם במקור בפורום CODE613 ב06/04/2014 21:19 (+03:00)
-
דבר ראשון הכותרת לא מספיק מבטאת את שאלתך.
שנית, מנין לך שרשימה מקושרת טובה מלבנות כל פעם מערך חדש?ובכן, ליסט זה כמו מערך. ומערך, זה הכי מהיר שיש, וגם הכי חסכוני.
הבעיה שלך עם הגדילה של הליסט, זה בעיה שאם תתחבט בה תעשה כמו שמפתחי דוט נט עשו. המתכנת מצידו צריך להשתדל שהגידול יהיה צפוי כפי האפשר, ולהיערך בצורה מאוזנת בין נפח הזיכרון שיש לתפוס ובין תדירות הגידול וכמותו.
הליסט מקבל באחד מבנאיו ערך מספרי שקובע את הצפי הראשוני - זה פשוט בונה מערך בגודל זה.על כל פנים הלינק שנתת מביא את עיקרון הרשימה מקושרת, שמשמשת להרבה דברים בעקרונות תוכנה.
יש את הדבר הזה בדוט נט בשם LinkedList תוכל לנסות לראות אם הוא מהיר יותר או להיפך.
הנה כמה שבדקו זאת: http://stackoverflow.com/q/169973/1271037, וכאן הסברים לתופעות http://stackoverflow.com/q/5983059/1271037 ועוד http://www.codeproject.com/Articles/340797/Number-crunching-Why-you-should-never-ever-EVER-us.וכללית, השכל מחייב את ההנחה שכל דבר בדוט בנוי בצורה טובה מאוד, רק שצריך לדעת מה מיועד למה, ומה יש יותר טוב לכל סיטואציה.
פורסם במקור בפורום CODE613 ב06/04/2014 21:33 (+03:00)
-
אז מה מומלץ למצב הבא:
מצד אחד הליסט צריך להיות מסוגל להכיל הרבה מאוד ערכים, בסביבות חצי מליון עד מליון ולזה עדיף לכאורא רשימה מקושרת כיון שעבור כל איבר חדש היא מקצה שטח קטן חדש שאינו צריך להיות רצוף לשטח הזכרון של איברים אחרים, אלא הוא נמצא אי שם ומדברים איתו דרך מצביע,
ומצד שני כל הערכים הם יחודיים, כלומר לפני שאני מכניס ערך כל שהוא אני צריך לבדוק שהוא לא קיים כבר ברשימה ולזה עדיף מערך רגיל כדי שיהיה אפשר לעשות חיפוש בינארי לפני שמכניסים איבר חדש ולא לעבור מהתחלה עד הסוף כל פעם.פורסם במקור בפורום CODE613 ב06/04/2014 21:47 (+03:00)
-
מצד אחד הליסט צריך להיות מסוגל להכיל הרבה מאוד ערכים, בסביבות חצי מליון עד מליון ולזה עדיף לכאורא רשימה מקושרת כיון שעבור כל איבר חדש היא מקצה שטח קטן חדש שאינו צריך להיות רצוף לשטח הזכרון של איברים אחרים, אלא הוא נמצא אי שם ומדברים איתו דרך מצביע,
למה רצוף זה לא טוב? אדרבא זה טוב. אם אתה דואג איפה יהיה שטח רצוף זה לא נראה לי עניינך :).
ולזה עדיף מערך רגיל כדי שיהיה אפשר לעשות חיפוש בינארי לפני שמכניסים איבר חדש ולא לעבור מהתחלה עד הסוף כל פעם.
למה החלטת שבליסט א"א לעשות חיפוש בינארי?
מה שחשוב לדעת זה בכמה פעמים אתה מכניס את הערכים (בבת אחת, כמה פעמים, הרבה הרבה פעמים), לפי מה אתה שולף אותם (סדרתי או גם אקראי - לפי key וכדו') ומה המחלקה/מבנה שמשמשים לקבוע את ייחדויותו של הערך ואת השוואתו, והאם נלווים לערך נתונים נוספים מלבדו.
בשביל להכניס לרשימה ערכים ייחודיים, יש מחלקה HashSet (גם גנרית), היא עושה את העבודה בשקט (אל תדאג, היא עושה זאת ביעילות) - אפשר להוסיף ערכים והיא מדלגת על קיים (היא מחזירה ערך בוליאני אם הערך הוכנס או לא).
אבל יש עוד הרבה וריאציוות של אוספים, ראה כאן.פורסם במקור בפורום CODE613 ב07/04/2014 13:22 (+03:00)
-
@דוד ל.ט.
למה החלטת שבליסט א"א לעשות חיפוש בינארי?
בליסט אפשר, אבל זה רק בגלל שהליסט מבוסס על מערך רגיל, בקוד הבא השורה השניה מתקבלת אבל השלישית לא:
Dim list As New List(Of String) Dim num = list.BinarySearch("A") Array.BinarySearch(list, "A")תוכל לראות ברפלקטור שכאשר אתה מבקש לעשות חיפוש בינארי בליסט הוא נעשה על המערך הרגיל שהליסט מבוסס עליו.
@דוד ל.ט.
מה שחשוב לדעת זה בכמה פעמים אתה מכניס את הערכים (בבת אחת, כמה פעמים, הרבה הרבה פעמים), לפי מה אתה שולף אותם (סדרתי או גם אקראי - לפי key וכדו') ומה המחלקה/מבנה שמשמשים לקבוע את ייחדויותו של הערך ואת השוואתו, והאם נלווים לערך נתונים נוספים מלבדו.
הקוד שלי בנוי בצורה הבאה:
Dim dic As New SortedList(Of String, List(Of Integer())) ' את הפעולה הבאה אני צריך להריץ אלפי פעמים ' כדי להכניס אלפי רשימות לתוך הרשימה הממויינת Sub mySub(ByVal list As List(Of myType)) For Each myType As myType In list ' בודק אם המפתח כבר קיים If dic.Keys.IndexOf(myType.A) > -1 Then dic(myType.A).Add(myType.B) Else ' אם לא קיים יוצר מפתח חדש Dim L As New List(Of Integer()) L.Add(myType.B) dic.Add(myType.A, L) End If Next End Sub Public Class myType Public A As String Public B As Integer() End Classכרגע הפעולה לוקחת כעשרים דקות!!
כלומר להכניס כ 1200 ליסטים שבכל אחד יש בממוצע כ 20,000 פריטים לתוך הליסט הראשי לוקח המון זמן, בסוף מתקבל ליסט ראשי שיש בו 'רק' 800,000 פריטים כי הכפולים נמצאים ביחד.
ניסיתי לבדוק מה לוקח כל כך הרבה זמן, והחלטתי להכניס את כל הליסטים לליסט הראשי בלא לבדוק אם הפריט קיים וממילא בלא לאחד את הכפולים [והוצרכתי לצורך זה להשתמש בליסט לא ממויין] ואז באמת אף שהליסט נהיה ענק אבל הפעולה נגמרה מהר, ולמדתי מזה שהבדיקה על כל פריט אם הוא כבר קיים גורם את רוב העיכוב ולא זה שהליסט מתנפח מאוד.
אז מה העצה כאן?פורסם במקור בפורום CODE613 ב07/04/2014 14:28 (+03:00)
-
@דוד ל.ט.
למה החלטת שבליסט א"א לעשות חיפוש בינארי?בליסט אפשר, אבל זה רק בגלל שהליסט מבוסס על מערך רגיל, בקוד הבא השורה השניה מתקבלת אבל השלישית לא:
Dim list As New List(Of String) Dim num = list.BinarySearch("A") Array.BinarySearch(list, "A")")
 :x :lol: <!-- s8-) --><img src="{SMILIES_PATH}/icon_cool.gif" alt="8-)" title="מגניב" /><!-- s8-) -->
:x :lol: <!-- s8-) --><img src="{SMILIES_PATH}/icon_cool.gif" alt="8-)" title="מגניב" /><!-- s8-) -->  :oops:
:oops: אפשר להבין מה אתה רוצה?
פורסם במקור בפורום CODE613 ב07/04/2014 14:31 (+03:00)
-
בקשר לקוד שלך, הוא לא עונה על השאלות שלי. א"א לנחש דרכו את השאלות הפשוטות שאותם שאלתי.
חוץ מזה טרחתי והבאתי לך קישור, עשית בו שימוש?בשביל לבדוק אם איבר קיים ולפי זה להכניס SortedList הוא ודאי לא האידאלי. למה החלטת שאתה צריך אותו? (בשביל לקבל בסוף מיון, תמיין בסוף. הSortedList עשוי להחזקת רשימה ממויינת שתישאר ככה גם כשמוסיפים לה טיפונת איברים פה ושם).
Dictionary ייתן לך ביצועים משופרים (בדרך שבחרת בקוד שלך), וHashSet יחסוך לך את הקוד שכתבת לבדיקת המצאות איבר (קראת את ההודעה שלי הקודמת? שם כבתי גם שהוא עושה זאת יעיל).פורסם במקור בפורום CODE613 ב07/04/2014 14:43 (+03:00)
-
מה לא מובן?
תפתח ברפלקטור ותראה איך בנוי ליסט
מאחורי הקלעים יש מערך רגיל שעושים לו REDIM כל פעם מחדשהתום לב שלך שובה את ליבי.
אתה כתבת "לזה עדיף מערך רגיל כדי שיהיה אפשר לעשות חיפוש בינארי" אז הערתי שגם בליסט אפשר.
אז אתה מתחיל להסביר לי שמאחורי הקלעים זה מבוסס על מערך (כאילו שאלמלא כן לא היה אפשר).
אתה אפי' מצרף קוד...
מה זה נוגע לנידון היפה שאנו דנים בו? מה משנה איך זה ממומש?!?פורסם במקור בפורום CODE613 ב07/04/2014 14:48 (+03:00)
-
@דוד ל.ט.
חוץ מזה טרחתי והבאתי לך קישור, עשית בו שימוש?
קראתי את המאמר שם אבל עדיין אני זקוק להכוונה.
@דוד ל.ט.
בשביל לבדוק אם איבר קיים ולפי זה להכניס SortedList הוא ודאי לא האידאלי. למה החלטת שאתה צריך אותו? (בשביל לקבל בסוף מיון, תמיין בסוף. הSortedList עשוי להחזקת רשימה ממויינת שתישאר ככה גם כשמוסיפים לה טיפונת איברים פה ושם).
כל פריט חייב להכנס לליסט הראשי בסופו של דבר, רק שאם המפתח קיים הפריט נכנס לאותו מפתח ואם הפריט לא קיים הוא נכנס ויוצר מפתח חדש, כך שכולם נכנסים אבל אין כפיליות, אלא כל הכפולים הם ביחד בתוך איבר אחד.
זה דומה למילון של שפה בצד אחד כתוב מילה האנגלית ובצד שני הרבה פרושים בעברית, כל מילה חדשה שנכנסת למילון אם היא כבר קיימת רק הפירוש שלה יכנס לחלק הפרושים שבעברית, ואם היא לא קיימת במילון אז גם המילה האנגלית תכנס.@דוד ל.ט.
Dictionary ייתן לך ביצועים משופרים (בדרך שבחרת בקוד שלך)
מה שונה Dictionary מ SortedList ?
@דוד ל.ט.
וHashSet יחסוך לך את הקוד שכתבת לבדיקת המצאות איבר (קראת את ההודעה שלי הקודמת?).
קראתי אבל HashSet לא יאמר לי רק אמת ושקר אבל לא איפה הפריט כבר נמצא כדי שאצרף אותו לחברו הדומה לו וכמו שכתבתי לעיל שכל הכפולים צריכים להיות ביחד.
אולי אני אנסה להוסיף את הכל למערך אחד לא ממויין ואז למיין ולאחד הכפולים, ונראה אם זה יהיה יותר מהר.
פורסם במקור בפורום CODE613 ב07/04/2014 14:56 (+03:00)
-
אני אכן לא קראתי מספיק בעיון את הקוד שלך (לתשומת לבך, קוד זה לא צורה להבהיר מה אתה רוצה לעשות).
אז אכן הDictionary ייתן לך לכאורה ביצועים משופרים למציאת הערך (פי שתיים).
חוץ מזה הקוד שלך באמת לוקה ביעילות בזה: במידה והמפתח קיים הוא מאתר פעמיים (אינדקס, ואח"כ לפי KEY).
היית צריך לעשות ככה:Sub mySub(ByVal list As List(Of myType)) For Each myType As myType In list ' בודק אם המפתח כבר קיים Dim key As List(Of Integer) If dic.TryGetValue(myType.A, key) = False Then key = New List(Of Integer) dic.Add(myType.A, key) End If dic(myType.A).Add(myType.B) Next End Sub(בטעות בקוד לשי הטיפוס הוא int במקום מערך של int, אבל העיקרון זהה).
אם אתה מקבל את כל הנתונים בבת אחת אני גם חושב שעדיף לרכז לבסוף.
תוכל להיעזר בשאילתת לינק לקיבוץ משהו כזה:Sub mySub(ByVal list As List(Of myType)) Dim q = From el In list Group el By el.A Into grp = Group Select New With {.Key = A, .Ints = grp.SelectMany(Function(x) x.B)} ... End Subפורסם במקור בפורום CODE613 ב07/04/2014 15:53 (+03:00)
-
להרחבת הידיעות אודות סוגי הקולקשיינס:
http://geekswithblogs.net/BlackRabbitCoder/archive/2011/06/16/c.net-fundamentals-choosing-the-right-collection-class.aspx
והנה עוד מMSDNבקשר לסוגי המילונים - מפתח-ערך, הנה תמונה מתוך ספר C# in nutshell שנותנת אינדיקציה לשם מה עשוייה כל אחת:
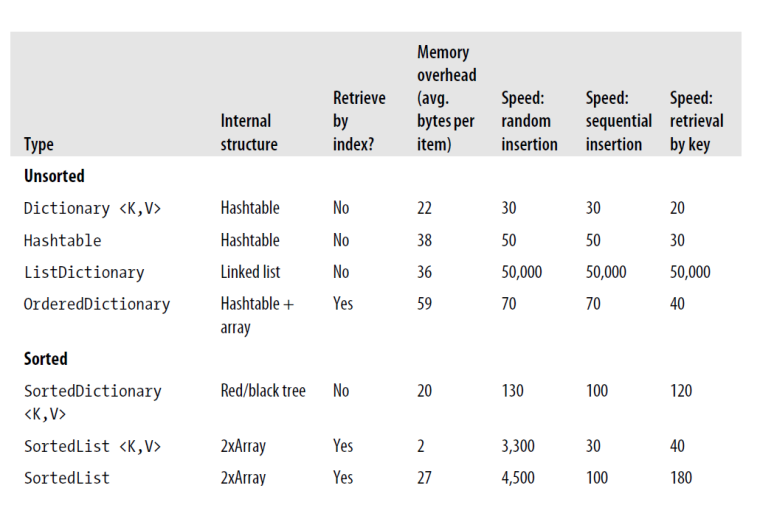
לצפייה טובה לחצו קליק ימני על התמונה > פתח בכרטיסייה חדשה.
המספרים הם אלפיות שניה, לביצוע 50,000 פעולות, במחשב הבדיקה (1.5 Ghz).ורחמים, אם אתה רוצה באמת עצות טובות, פרוש את התמונה במלואה, חסר הרבה פרטים שבירורם היה יכול לעזור לתשועה ברוב יועץ.
פורסם במקור בפורום CODE613 ב07/04/2014 15:58 (+03:00)
-
-
תודה רבה על כל המידע החשוב !
@דוד ל.ט.ורחמים, אם אתה רוצה באמת עצות טובות, פרוש את התמונה במלואה, חסר הרבה פרטים שבירורם היה יכול לעזור לתשועה ברוב יועץ.
הכי פשוט להמחיש מה הקלט שלי ומה הפלט שהתוכנה צריכה להוציא זה הדוגמא שאמרתי לעיל, תחשוב שיש לך המון קבצים שבכל קובץ בכל שורה יש מילה באנגלית ולידה פירוש אחד בעברית, בכל קובץ יש כ 20,000 מילים בלבד ולא את כל שפת האנגלית וגם כל מילה באנגלית קיבלה רק פרוש אחד בעברית כאשר יתכן יש כמה פרושים.
זה הקלט
הפלט הוא שהתוכנה צריכה לאחד את כל הקבצים למילון אחד שלם, שבו יופיעו כל המילים באנגלית עם כל הפרושים שלהם בעברית.
אז כרגע כמו שהסברתי אני עובר קובץ קובץ, שורה שורה בקובץ ומכניס כל מילה באנגלית לליסט הראשי אם המילה קיימת רק הפירוש שלה נכנס במקום המתאים ואם היא לא קיימת שניהם נכנסים.
אם התמונה לא מספיק ברורה אסביר עוד.כעת סיימתי את הנסיון, תחילה הכנסתי את כל המילים לרשימה אחת ארוכה, אח''כ מיינתי ואח''כ הסרתי כפולים במקום 20 דקות זה הסתיים ב 40 שניות עבור המיון ועוד 7 שניות עבור הסרת איחוד הכפולים !!!
פורסם במקור בפורום CODE613 ב07/04/2014 16:16 (+03:00)
-
אם הנמשל ממש זהה למשל, אני חושש שהדרך הנכונה והמעצבנת (כי זה מוריד את כל האתגר) זה הוא מסד נתונים.
זה לא באמת פיתרון, כי למסד יש אותו בעיה אבל מבחינה מעשית זה פשוט להיפטר מהמטלה...
הכי מהיר אני חושב זה טבלה ארוכה ואח"כ Distinct לטבלה אחרת.פורסם במקור בפורום CODE613 ב07/04/2014 16:34 (+03:00)
-
כעת סיימתי את הנסיון, תחילה הכנסתי את כל המילים לרשימה אחת ארוכה, אח''כ מיינתי ואח''כ הסרתי כפולים במקום 20 דקות זה הסתיים ב 40 שניות עבור המיון ועוד 7 שניות עבור הסרת איחוד הכפולים !!!
שתי שאלות:
כמה איברים יש?
איך הסרת כפולים?פורסם במקור בפורום CODE613 ב07/04/2014 16:57 (+03:00)
-
כעת הרצתי שוב וזה הדוח:
מספר פריטים 7,474,693
מיון 00:00:29.7094737
צירוף כפולים 00:00:04.0372530את הכפולים צירפתי בינהם [לא הסרתי] כך:
יצרתי ליסט חדש
עברתי בלולאה על כל הליסט הראשי
הכנסתי את האיבר לליסט החדש
בלולאה חדשה המשכתי להכניס את האיברים הבאים עד שהגיע איבר שונה
ואז המשכתי בלולאה של הליסט הראשיבליסט החדש נוצרו 611,496 פריטים.
פורסם במקור בפורום CODE613 ב07/04/2014 17:18 (+03:00)
-
המיון + האיחוד הוא לכאורה בזבוז, כי המיון הוא לא רק סורק, אלא גם ממקם, ובמקרה שלך היה עדיף שכבר יאחד בנקודת זמן זו.
השאלה איך לממש איחוד מהיר ללא מיון, הרי איחוד מחפש ובשביל חיפוש בינארי צריך מיון. התשובה היא שצריך רשימה חדשה למאוחדים (וזו רשימה הרבה יותר קצרה, ממילא המיון שלה זול יותר) שהיא תהיה ברת חיפוש מהיר כמו רשימה ממויינת.
אבל, אף שאינני מבין איך, Dictionary מוצא מהר יותר מחיפוש בינארי. וממילא עדיף Dictionary.לפי מה שנראה לי, Dictionary מהתחלה יעשה את העבודה מהר יותר.
אם תמשיך בקו שלך, אז יש לי שיפור:
הפירוש שבמשל הוא המערך השלמים שבנמשל. כמה פירושים = כמה מערכים. במקור יש רק פירוש לכל מילה, אז עדיף שתעבוד עם אובייקט שונה שמכיל במקום ליסט משתנה שלם פשוט (זה חיסכון גם בזיכרון וגם במעבד). ובאובייקט היעד (המאוחד) יהיה מערך ולא ליסט (חיסכון בזיכרון).פורסם במקור בפורום CODE613 ב07/04/2014 19:24 (+03:00)
-
@דוד ל.ט.
השאלה איך לממש איחוד מהיר ללא מיון, הרי איחוד מחפש ובשביל חיפוש בינארי צריך מיון.
מה שאני עשיתי זה שקודם מיינתי ואז לא הייתי צריך לחפש כדי לאחד את הכפולים, כי אחרי מיון כל הכפולים עומדים אחד אחרי השני ברצף. אם לא נמיין וכדי לאחד נחפש הרי שנצטרך לעשות המון חיפושים חיפוש לכל פריט. אבל המיון הוא יותר מהיר מזה, ואחרי המיון האיחוד הוא ב 4 שניות.
@דוד ל.ט.ובאובייקט היעד (המאוחד) יהיה מערך ולא ליסט (חיסכון בזיכרון).
גם אני נוכחתי לראות שמערך לוקח פחות זכרון מאשר ליסט אבל למה זה? הרי גם הליסט מבוסס על מערך?
פורסם במקור בפורום CODE613 ב07/04/2014 20:33 (+03:00)
-
שוב, לדעתי המיון מיותר. מתשובתך ניכר שנמאס לך לעיין בנושא...
בקשר לליסט מול מערך זה מאוד פשוט, מערך לוקח בדיוק את הגדול שהוא תופס, וליסט תופס מראש מקומות לאפשר הוספה.
עוד שיפור (גם בדרכך שלך) זה לעשות את המחלקה לטרום האיחוד כמבנה.פורסם במקור בפורום CODE613 ב08/04/2014 11:19 (+03:00)