
איך להסיר ניקוד וטעמים מטקסט בc#
-
איך להסיר ניקוד וטעמים מטקסט בc#
מצאתי שני דרכים אשמח לקבל המלצות איזה עדיף ולמה.
# אפשרות א על ידי רגקס
public static string RemoveDiactricts(string input) { return Regex.Replace(input, @"\p{M}", ""); }
# אפשרות ב על ידי ספריית Diactricts
דרך ה-NuGet התקינו את ספריית Diactricts

לאחמ"כ תוכלו להתשמש עם ה-class דלהלןpublic class HebrewDiacriticsMapping : IAccentMapping { private readonly Dictionary<char, MappingReplacement> mappings; public HebrewDiacriticsMapping() { mappings = CreateMappings(); } public IDictionary<char, MappingReplacement> Mapping => mappings; private Dictionary<char, MappingReplacement> CreateMappings() { var mappings = new Dictionary<char, MappingReplacement>(); // Remove all Hebrew diacritics by mapping them to an empty string // Diacritics in Hebrew range from U+0591 to U+05BD, U+05C1, U+05C2, U+05C4, U+05C5 // U+0591 - U+05AF (excluding U+05BE - U+05C0, which are vowels and other symbols) // U+05B0 - U+05BD, U+05C1, U+05C2, U+05C4, U+05C5 (including additional diacritics) for (int i = 0x0591; i <= 0x05AF; i++) { char diacriticChar = (char)i; mappings[diacriticChar] = new MappingReplacement(); } for (int i = 0x05B0; i <= 0x05BD; i++) { char diacriticChar = (char)i; mappings[diacriticChar] = new MappingReplacement(); } mappings['\u05C1'] = new MappingReplacement(); mappings['\u05C2'] = new MappingReplacement(); mappings['\u05C4'] = new MappingReplacement(); mappings['\u05C5'] = new MappingReplacement(); return mappings; } } public static class HebrewDiacriticsRemover { private static readonly DiacriticsMapper mapper = new DiacriticsMapper(new HebrewDiacriticsMapping()); public static string RemoveHebrewDiacritics(this string input) { return mapper.RemoveDiacritics(input); } } -
קשה להבין את השאלה שלך, למה יש לך צד שהשימוש בספריה עדיף?
במיוחד שהשימוש בספריה לא חוסך קוד אלא מוסיף.
להשתמש בספריה יש בזה מחירים: תלות, תחזוקה (אם קיימת) בשליטה חיצונית, אבטחה. לא משלמים את המחירים האלו בלי תמורה (עריכה: הספריה מהירה יותר מRegex בשליש בערך, ראה להלן).בשביל הספורט בדקתי ביצועים של האפשרויות שעלו לי בראש, להלן הקוד:
class Test { string text; public Test() { System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance); text = File.ReadAllText(@"D:\Tora\020_MISHNA\101_SEDER_MOED\13_MAS_ERUVIN\MZ2_ERUVIN_L2.txt", Encoding.GetEncoding(1255)); } string byRegex() => Regex.Replace(text, @"\p{M}", ""); string byRegexDedicated() => Regex.Replace(text, @"[\u0591-\u05CF]", ""); string byDiacritis() => text.RemoveHebrewDiacritics(); string byLinqReverseCondition() => new string(text.Where(x => x < 1425 || x > 1487).ToArray()); string byLinq() => new string(text.Where(x => x > 1487 || x < 1425).ToArray()); string byStringBuilder() { var sb = new StringBuilder(text.Length); foreach (var c in text) if (c > 1487 || c < 1425) sb.Append(c); return sb.ToString(); } } }תוצאות:
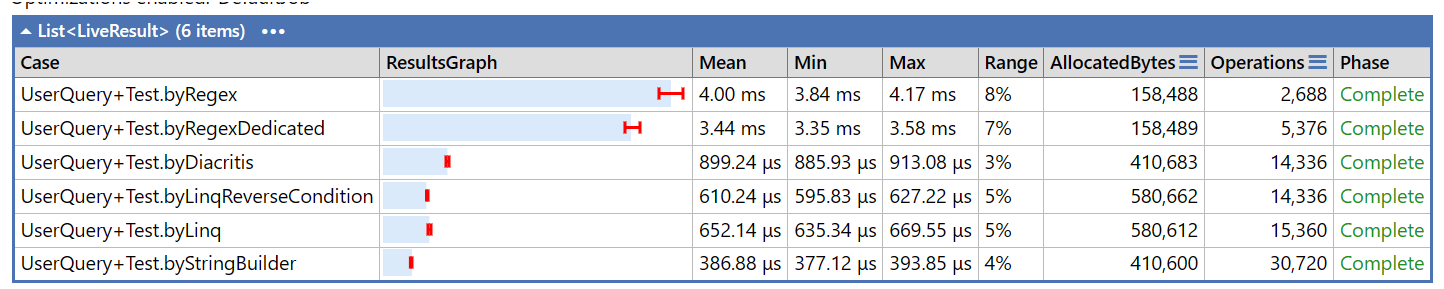
הסבר:
הטסט הוא על קובץ של ברטנורא מנוקד על עירובין מתוך תורת אמת.
יש פה חמישה דרכים, הראשונה (byRegex) היא Regex גנרי שמתאים לכל סימני הניקוד בעולם (כולל למשל גרמנית), השניה מטפלת בניקוד עברי בלבד שזה לעצמו חיסכון אבל הוא זניח כי עיקר הזמן הוא ההחלפה בפועל שלא יעילה יותר.
הדרך השלישית שזה הספריה שהוצעה, אכן מביאה שיפור בביצועים לעומת רגקס. היא כנראה כתובה הכי טוב שאפשר אבל היא גנרית מידי וכנראה לכן היא מפסידה לשיטות האחרות.
הדרך הרביעית והחמישית (byLinq) זהות מצד השיטה, הם בודקים אם האות בטווח התווים של הניקוד העברי, ההבדל ביניהם הוא רק בסדר התנאי, בהנחה שרוב האויות שייבדקו הם אותיות עבריות דוקא שערכם גדול מ1488 (האות א) אז יעיל קודם לבדוק אם האות גדולה מהערך הזה ולהימנע מבדיקה נוספת, אני לא מבין למה הדרך שנראאית לי פחות יעילה מהירה יותר עקבית אבל בהפרש זניח.
הדרך האחרונה זה עבודה שחורה, זה נראה הכי מהר.מה הייתי עושה? לפני הבדיקה הייתי לבטח משתמש בRegex כנראה, בגלל הקריאות והפשטות. אחריה? יש לי יצר להיות יעיל יותר, אבל זה פחות לגיטימי מרג'קס במקרים שיעילות לא נדרשת בדחיפות.
- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
קשה להבין את השאלה שלך, למה יש לך צד שהשימוש בספריה עדיף?
במיוחד שהשימוש בספריה לא חוסך קוד אלא מוסיף.
להשתמש בספריה יש בזה מחירים: תלות, תחזוקה (אם קיימת) בשליטה חיצונית, אבטחה. לא משלמים את המחירים האלו בלי תמורה (עריכה: הספריה מהירה יותר מRegex בשליש בערך, ראה להלן).בשביל הספורט בדקתי ביצועים של האפשרויות שעלו לי בראש, להלן הקוד:
class Test { string text; public Test() { System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance); text = File.ReadAllText(@"D:\Tora\020_MISHNA\101_SEDER_MOED\13_MAS_ERUVIN\MZ2_ERUVIN_L2.txt", Encoding.GetEncoding(1255)); } string byRegex() => Regex.Replace(text, @"\p{M}", ""); string byRegexDedicated() => Regex.Replace(text, @"[\u0591-\u05CF]", ""); string byDiacritis() => text.RemoveHebrewDiacritics(); string byLinqReverseCondition() => new string(text.Where(x => x < 1425 || x > 1487).ToArray()); string byLinq() => new string(text.Where(x => x > 1487 || x < 1425).ToArray()); string byStringBuilder() { var sb = new StringBuilder(text.Length); foreach (var c in text) if (c > 1487 || c < 1425) sb.Append(c); return sb.ToString(); } } }תוצאות:
הסבר:
הטסט הוא על קובץ של ברטנורא מנוקד על עירובין מתוך תורת אמת.
יש פה חמישה דרכים, הראשונה (byRegex) היא Regex גנרי שמתאים לכל סימני הניקוד בעולם (כולל למשל גרמנית), השניה מטפלת בניקוד עברי בלבד שזה לעצמו חיסכון אבל הוא זניח כי עיקר הזמן הוא ההחלפה בפועל שלא יעילה יותר.
הדרך השלישית שזה הספריה שהוצעה, אכן מביאה שיפור בביצועים לעומת רגקס. היא כנראה כתובה הכי טוב שאפשר אבל היא גנרית מידי וכנראה לכן היא מפסידה לשיטות האחרות.
הדרך הרביעית והחמישית (byLinq) זהות מצד השיטה, הם בודקים אם האות בטווח התווים של הניקוד העברי, ההבדל ביניהם הוא רק בסדר התנאי, בהנחה שרוב האויות שייבדקו הם אותיות עבריות דוקא שערכם גדול מ1488 (האות א) אז יעיל קודם לבדוק אם האות גדולה מהערך הזה ולהימנע מבדיקה נוספת, אני לא מבין למה הדרך שנראאית לי פחות יעילה מהירה יותר עקבית אבל בהפרש זניח.
הדרך האחרונה זה עבודה שחורה, זה נראה הכי מהר.מה הייתי עושה? לפני הבדיקה הייתי לבטח משתמש בRegex כנראה, בגלל הקריאות והפשטות. אחריה? יש לי יצר להיות יעיל יותר, אבל זה פחות לגיטימי מרג'קס במקרים שיעילות לא נדרשת בדחיפות.
@dovid
פשוט אין מילים!
אפשר לשאול איך עשית את הבדיקות? זה נראה שהתשמשת באיזשהו תוכנה לא visual studioכמו"כ אפשר לשאול למה בעצם על ידי string builder הוא הכי מהיר מכולם?
-
@dovid
פשוט אין מילים!
אפשר לשאול איך עשית את הבדיקות? זה נראה שהתשמשת באיזשהו תוכנה לא visual studioכמו"כ אפשר לשאול למה בעצם על ידי string builder הוא הכי מהיר מכולם?
@pcinfogmach כתב באיך להסיר ניקוד וטעמים מטקסט בc#:
אפשר לשאול איך עשית את הבדיקות? זה נראה שהתשמשת באיזשהו תוכנה לא visual studio
-
@dovid זה דוגמא לבדיקה לא נכונה של ביצועים.
אני מקליד מסמארטפון ולכן קשה לי להרחיב, אנסה לתמצת:
בקריאה לפונקציות מסוימות נדרש לפעמים למערכת הפעלה זמן דרישה להקצות משאבים.
ולכן לא מסתכלים על זמן ריצה כולל אלא זמן הקצאה + זמן עיבוד, וההפרש בא לביטוי בעיקר בעבודה עם כמות דאטה ענקית. ולכן בדיקה נכונה של ביצועים מתבצע עם כמות דאטא קטנה וכמות דאטה ענקית (לדוגמא: ניקוד של כל התנ"ך...) ואז מעניין יהיה לראות שחלק מהפונקציות מהירות בדאטא קטן וחלק בדאטא גדול, בפוריקט מסוים בדקתי גודל של דאטא ובהתאם לכך את הפונקציה המהירה לאותה כמות. -
קשה להבין את השאלה שלך, למה יש לך צד שהשימוש בספריה עדיף?
במיוחד שהשימוש בספריה לא חוסך קוד אלא מוסיף.
להשתמש בספריה יש בזה מחירים: תלות, תחזוקה (אם קיימת) בשליטה חיצונית, אבטחה. לא משלמים את המחירים האלו בלי תמורה (עריכה: הספריה מהירה יותר מRegex בשליש בערך, ראה להלן).בשביל הספורט בדקתי ביצועים של האפשרויות שעלו לי בראש, להלן הקוד:
class Test { string text; public Test() { System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance); text = File.ReadAllText(@"D:\Tora\020_MISHNA\101_SEDER_MOED\13_MAS_ERUVIN\MZ2_ERUVIN_L2.txt", Encoding.GetEncoding(1255)); } string byRegex() => Regex.Replace(text, @"\p{M}", ""); string byRegexDedicated() => Regex.Replace(text, @"[\u0591-\u05CF]", ""); string byDiacritis() => text.RemoveHebrewDiacritics(); string byLinqReverseCondition() => new string(text.Where(x => x < 1425 || x > 1487).ToArray()); string byLinq() => new string(text.Where(x => x > 1487 || x < 1425).ToArray()); string byStringBuilder() { var sb = new StringBuilder(text.Length); foreach (var c in text) if (c > 1487 || c < 1425) sb.Append(c); return sb.ToString(); } } }תוצאות:
הסבר:
הטסט הוא על קובץ של ברטנורא מנוקד על עירובין מתוך תורת אמת.
יש פה חמישה דרכים, הראשונה (byRegex) היא Regex גנרי שמתאים לכל סימני הניקוד בעולם (כולל למשל גרמנית), השניה מטפלת בניקוד עברי בלבד שזה לעצמו חיסכון אבל הוא זניח כי עיקר הזמן הוא ההחלפה בפועל שלא יעילה יותר.
הדרך השלישית שזה הספריה שהוצעה, אכן מביאה שיפור בביצועים לעומת רגקס. היא כנראה כתובה הכי טוב שאפשר אבל היא גנרית מידי וכנראה לכן היא מפסידה לשיטות האחרות.
הדרך הרביעית והחמישית (byLinq) זהות מצד השיטה, הם בודקים אם האות בטווח התווים של הניקוד העברי, ההבדל ביניהם הוא רק בסדר התנאי, בהנחה שרוב האויות שייבדקו הם אותיות עבריות דוקא שערכם גדול מ1488 (האות א) אז יעיל קודם לבדוק אם האות גדולה מהערך הזה ולהימנע מבדיקה נוספת, אני לא מבין למה הדרך שנראאית לי פחות יעילה מהירה יותר עקבית אבל בהפרש זניח.
הדרך האחרונה זה עבודה שחורה, זה נראה הכי מהר.מה הייתי עושה? לפני הבדיקה הייתי לבטח משתמש בRegex כנראה, בגלל הקריאות והפשטות. אחריה? יש לי יצר להיות יעיל יותר, אבל זה פחות לגיטימי מרג'קס במקרים שיעילות לא נדרשת בדחיפות.
יש בעיה בהסרת ניקוד וטעמים כאשר מופיע מקף עליון שצריך להחליף אותו ברוווח אחרת זה יחבר שני מילים
הנה הקוד המתוקן עבור שימוש ב- stringbuilder
public static string RemoveHebrewDiactrics(this string input) { var sb = new StringBuilder(input.Length); foreach (var c in input) if (c == '־') sb.Append(' '); else if (c > 1487 || c < 1425) sb.Append(c); return sb.ToString(); }