
מדריך כתיבת אפליקציה וובית, Full-Stack, צעד אחר צעד
-
אנחנו נעבוד ב: Node.js + Express, ובצד לקוח בangular.js. לנתונים אולי משתמש בmongo (שזה ביחד קרוי MEAN STACK).
סט הכלים הזה לא נבחר דוקא בגלל שאלו הטכנולוגיות הכי מומלצות (יכול להיות) אלא כי הם הכי קלים להסברה והבנה של תהליך הפיתוח המלא של אפליקציית ווב מודרנית.
שאלות/הערות/הארות על המדריך בנושא נפרד בפורום, תודה מראש!דרישות:
- ידע בשפת JavaScript (לכל הפחות בסיסי)
- ידע בשפת HTML (מספיק מינימלי).
במחשב:
בהודעה הבאה נתקדם.
-
שיעור 1, helo world!
א. ניצור תיקיה במחשב (אנגלית, ושלא יהיה רווחים בשם).
ב. נפתח את התוכנה Visual Studio Code.
ג. נלחץ על הלינק Open Folder או דרך התפריט File ואז Open Folder...
ד. בתיבת הדו שיח ננווט לתיקיה שיצרנו ונלחץ על Select Folderכעת אנחנו עם סביבת עבודה - תיקיה, ללא קבצים.
בצד שמאל יש (נכון לכתיבת המדריך) חמש אייקונים גדולים, הראשון הוא להראות את חלונית הסיור ב"פרוייקט" שלנו.
החלונית מחולקת לשני מקטעים, העליון (OPEN EDITORS) מראה את כל חלוניות העריכה הפתוחים כעת, והתחתון מראה את עץ הקבצים שנמצאים בתיקיה.
בריחוף על כותרת המקטע התחתון מופיעים כמה אייקונים שימושיים, מוקפים בצהוב חלש בתמונה: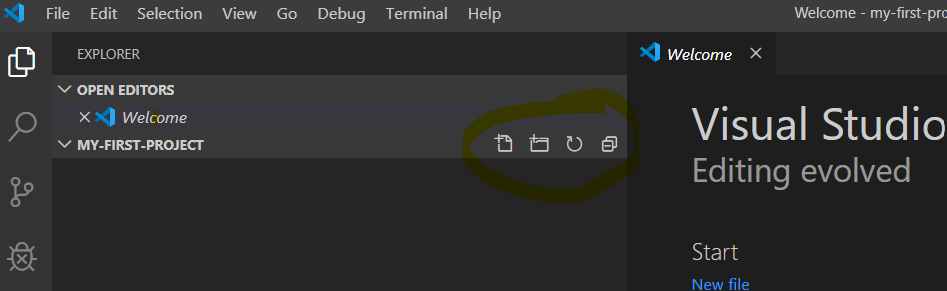
הסמלים האלה הם לחצנים לפעולות על הקבצים: ריענון, תיקיה חדשה, קובץ חדש.
ו. נלחץ על הלחצן של קובץ חדש (אפשר גם קליק ימני בחלל החלונית הזו ואז New File),
ז. נקרא לקובץ app.js, לחיצה על אנטר תשמור את השם ותפתח את הקובץ.
ח. נכתוב בקובץ את הקוד הבא:const http = require('http'); function handleAllRequest(req, res) { res.write('Hello World'); res.end(); } var server = http.createServer(handleAllRequest); server.listen(3000);ט. כעת נלחץ F5 במקלדת, או נלחץ על הסמל הצידי הרביעי (סוג של חיפושית שמסמלת את ה"באג") ואז ללחוץ על הכפתור Debug With Node.js.
י. נפנה לדפדפן, ונכתוב שמה בשורת הכתובת http://localhost:3000 ואנטר (או אפשר ללחוץ על הלינק פה...), נראה את המילים hello world.
עקרונית גמרנו כעת להקים "שירות אינטרנט דינמי".
בפוסטים הבאים אנתח את המשמעות של הקוד ואת המשמעות של התוצאה שלו צעד צעד.
שאלות? בשמחה! בפורום! תודה רבה שהייתם איתנו.
(נ.ב. המדריך מייגע למי שקצת יודע, אבל ככה הוא לא עושה שום הנחות בהסברים. אתכם הסליחה). -
שיעור 2, הפסקת פילוסופיה: טיפה הסבר על ארכיטקטורת שרת לקוח
(הרגעה: כל ההסבר בהודעה הזו, יעזור לכם מאוד לפעמים, אבל הוא לא קריטי כחלק מהמדריך. תרגישו חופשי לדלג או לקרוא בעת הפנאי בהמשך אחרי המשך המדריך).
בא נתבונן בכתובת http://localhost:3000, היא מורכבת משלושה חלקים:
א. http:// זה נקרא הסכמה, לא נדבר על זה.
ב. localhost - זה שם האתר. נקרא גם שם מתחם, או דומיין.
ג. 3000 זה מזהה שנקרא "פורט"
(הוא משומט ברוב כתובות האינטרנט שאנו מכירים, בהסתמך על מוסכמה שפרוטוקול http הוא בפורט 80 אלא"כ צויין אחרת).עם מי צריך לתקשר?
כשאנו כותבים בדפדפן את הכתובת הזו על שלושת חלקיה, הדפדפן קודם מברר מה כתובת המחשב הפיזית (בדרך כלל כתובת IP) של שם האתר. לבירור זה קוראים לפעמים DNS. ובכן במקרה שלנו הכתובת של localhost היא 127.0.0.1 שזה כתובת שמפנה אל המחשב עצמו.
כשם ששם רחוב אינו כתובת מספקת למשלוח דואר - כי יש ברחוב כמה בניינים וכמה וכמה דיירים, כך כתובת רשת פיזית של מחשב איננו מספיק כדי ליצור איתו קשר, שכן במחשב אחד יכולים להיות כמה וכמה תוכנות שמספקות מענה שונה לחלוטין זה מזה. ובשביל זה הדפדפן צריך מספר מזהה שמצביע לאיזה "דייר" הוא ממען את "מכתבו", למזהה הזה קוראים פורט, במקרה שלנו 3000 (המגוון האפשרי הוא 1-32767, זה הרבה מעבר לנדרש).איך מתקשרים?
אחרי שהדפדפן כבר יודע את כתובת היעד המדוייקת (כתבות פיזית + פורט), הוא צריך לבצע תקשורת.
הוא פותח מול המחשב ההוא "שיחה", סוג של שיחה זו נקראת TCP. בשיחה זו הנתונים הם תמיד בינאריים כך שניתן להעביר את נתונים שונים, אבל הדפדפן בוחר לדבר בשפה מאוד פשוטה וקלה להבנה, טקסט אנושי קריא ומובן. HTTP תמיד תמיד נשלח ומתקבל כמסמך טקסט פשוט.
בא נראה דוגמא. נחזור לדף האמור, הלא הוא http://localhost:3000 נפתח את כלי הפיתוח של כרום ע"י F12, או Ctrl+Shift+I בחלונית של כלי הפיתוח נבחר בכרטסת Network.
כעת נרענן את הדף ע"י F5 או על ידי לחיצה על כפתור הריענון ונראה בחלונית שורה עם המילה localhost.
נבחר אותה, ואז תיפתח חלונית צד ונאתר שמה כותרת בשם Request Headers. לצד הכותרת כתוב view source, נלחץ על זה, ויתגלה לנו המכתב המלא (במקרה הזה) אותו שלח הדפדפן לlocalhost:GET / HTTP/1.1 Host: localhost:3000 ... הרבה שורות נוספות ... User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4011.0 Safari/537.36 ... הרבה שורות נוספות ...לא נעבור כעת על כל תוכן המכתב, אבל נדע שפה יש את כל מה שהדפדפן כותב לשרת היעד כלומר האתר, בעת "כניסה" לדף או משאב אינטרנטי. לשרת/אתר היעד אין שום מושג עליכם מלבד מה שנאמר לו פה במסגרת "מכתב" זה, שנשלח כאמור בעת כל כניסה למסמך או משאב אינטרנטי.
התגובה-תשובה: סיום הקשר
למגיב נקרא להלן שרת. השם הזה משמעותו כמו משרת, מלצר שנענה לקריאה ונותן שירות.
אם נדבר על עובדות שרת, זה כינוי לתכונה שרצה במחשב המרוחק עליו מצביע האתר.HTTP, הוא שמו של הפרוטוקול עליו אנו מדברים.
לפיו נקבע "נוסח" וסגנון מכתב הטקסט האמור לעיל, ויש לו כללים מוקפדים איך כותבים.
הפרוטוקול הזה רואה את הקשר בין שני המחשבים - המחשב של הדפדפן והמחשב של האתר (בדוגמת הקוד שלנו זה אותו אחד) כקשר שנקרא שרת-לקוח. הביטוי הזה בא לומר, שבשונה משיחה חברותית בין חברים בה יש סימטריה לשני הצדדים, פה הצד של האתר מתפקד כ"עונה" - הוא נכנס לתמונה תמיד אך ורק לאחר קבלת ה"מכתב" מאתת הלקוח - המבקש, והוא מסיים את הקשר מייד עם תום התגובה שלו.איך נראית תגובת השרת? מכתב שדומה מאוד למכתב הנ"ל.
במקרה שלנו המכתב במלואו נראה ככה:HTTP/1.1 200 OK Date: Mon, 30 Dec 2019 00:31:02 GMT Connection: keep-alive Transfer-Encoding: chunked Hello Worldשימו לב שהדפדפן אחרי שקיבל את התשובה הזו, בחר לחתוך את השורה האחרונה ולהציג רק אותה. הכלל הוא שהדפדפן מחפש שורה ריקה במכתב, ומביא את כל מה שלאחריה לתוכן בחלון.
בהודעה הבאה נעבור לקוד שכתבנו בnode.js וננסה להסביר אותו בעזרת השם.
תודה, ולהתראות. -
שיעור 3, חזרה לקוד, רק הסברים
טרמינולוגיה קצרה בפרט למי שדילג על הפילוסופיה האחרונה:
בקשה request = ההודעה/מידע שהדפדפן שולח לאתר בעת כניסה לדף או בעת לחיצה על כפתור.
בקשה מכילה תמיד כתובת (מה שרואים בשורת הכתובת), כותרות כל שהם ואופציונלית תוכן נוסף בגוף בקשה (לא חשוב כעת להבין את השניים האחרונים).
תשובה, תגובה, response = ההודעה/המידע המידע שמגיע מהאתר לדפדפן כתגובה על בקשה (למשל דף אינטרנט רגיל או תמונה וכדומה).
שרת server = תוכנה שמגיבה לבקשות רשת האמורות ומחזירה תשובה. התוכנה הזו רצה על מחשב שלרוב מכונה גם שרת, למרות שזה "בניין" רב דירות שבו יכול להיות "שרת" אחד או יותר.
חיבור, שיחה, קונקשיין, connection = ערוץ תקשורת בין הדפדפן לאתר, שקול לשיחת טלפון בין שני אנשים. נפתח עם תחילת הבקשה ומסתיים עם סיום התשובה.שורה 1
const http = require('http');ייבוא מודול (מילה נרדפת לספריה, חבילה) מובנה של נוד בשם http. מודול זה מכיל המון כלים עבור תקשורת בפרוטוקול http.
הייבוא תמיד מחזיר ערך, במקרה שלנו אובייקט רב מימדים שאנו מציבים אותו במשתנה (לא בדיוק משתנה אלא קבוע, זה לא קריטי להבין כעת), למשתנה קראנו גם http.שורה 3-6
היא פונקציה JS שלא עושה "בינתיים" כלום, נחזור אליה להלן.
שורה 8
var server = http.createServer(handleAllRequest);קריאה לפונקציה createServer שבמודול http.
בא נתמקד בפונקציה. שמה createServer כלומר "צור שרת". הסברנו בחלק התיאורטי ששרת הנה תוכנה שמתפקדת על תקן "מלצר", מקבלת בקשות רשת (קרי למשל כתובות של דפי אינטרנט של האתר שלנו) ומגיבה עליהם.
כשאנו רוצים ליצור שרת, אנחנו רוצים להחליט מה תהיה התגובה לכל בקשה (למשל לענות שלום עולם).
אנו רוצים לומר לשרת הזה שאנחנו יוצרים מה הוא צריך "לענות" כתגובה לכל סוג של כתובת/בקשה.
לשם כך הפונקציה הזו מקבלת פרמטר שנקרא לעיתים קרובות קאלבק-callback.
לשם הפשטות ניתן להתייחס לקלאבק בשפת JS, כאירוע.
אירוע זה כמו בhtml שיש כפתור עם התכונה onclick שמשמעותו "לכשהכפתור יילחץ עשה כך" כך כל אירוע בשפות תכנות זה הקוד או הפקודה שיש לעשות לכשייקרה משהו שהתזמון שלו מתבצע ע"י חלק חיצוני לקוד שלנו.
כך במקרה שלנו אנו מספקים לcreateServer בסוגריים פרמטר שהוא פונקציה שהשרת יפעיל כל פעם שהוא יקבל בקשה (אפשר לכתוב ישירות את הפונקציה בתוך הסוגריים, אנו כתבנו את שמה של הפונקציה - זה אותו הדבר).השרת האמור לא יפעיל את הפונקציה סתם ככה:
handleAllRequest()אלא הוא יספק לה בסוגריים פרמטרים נחוצים שנידע מי ביקש מה ואיך לענות לו ישירות. הפרמטר הראשון הוא request (מייצג את כל פרטי הבקשה) השני response (מייצג את כל פרטי התשובה העתידה, ואת הפעולות שניתן לבצע עליה, שהרי היא עוד לא נשלחה).הפונקציה מחזירה מופע (מה זה מופע, ומה זה אובייקט? לא דחוף כעת להבין, תמיד אפשר ומומלץ לשאול!) של אובייקט מסוג server שמייצג את ה"שרת", את המופע הזה אנו שמים בתוך משתנה בשם server.
כעת השרת מכובה, צריך להפעיל אותו, ויש לכך פונקציה בשם listen, פה נעבור לשורה 9:server.listen(3000);פה אנו משתמשים במופע השרת שיצרנו, ומפעילים בו פונקציה בשם listen = תתחיל להאזין - לתת שירות (כלומר להפעיל בכל בקשה את הפונקציה handleAllRequest שסיפקנו בעת יצירתו) לכל מי שפונה אליך מעתה ואילך, עם פרמטר 3000 של מספר הפורט.
כשנוד (יוסבר בהמשך מה זה) מריץ את הקוד שלנו ומגיע לשורה זו, הוא פונה למערכת ההפעלה, ומבקש ממנה לנתב אליו (ורק אליו) את הבקשות שפונות לפורט 3000 שיתקבלו בכלל כרטיסי הרשת של המחשב פעולה זו מחייבת הרשאות ניהול (וגם בפעם הראשונה זה מאושר רק אחרי שנאשר הודעה על כך).
מערכת ההפעלה בודקת האם כבר הפורט הזה התבקש ע"י תוכנית שרצה כעת, ואם כן היא תדחה את הבקשה, הפונקציה תעורר שגיאה והתהליך יפול ויהיה כתוב בהודעות אדומות למטה את הודעת השגיאה. בחרנו את פורט 3000 כי הוא לא בשימוש שכיח וממילא הוא כנראה פנוי. תוכלו לנסות את פורט 80, אם לא תקרה שגיאה תוכלו לגשת בדפדפן לדף עם http:/localhost ללא הנקודתיים 3000, שכן סתם http הוא בחזקת 80 אז שאומרים אחרת.שורה 3-6, הפונקציה handleAllRequest.
function handleAllRequest(req, res) { res.write('Hello World'); res.end(); }הפונקציה הזו היא השחקן הראשי בקוד שלנו. בגלל ששמה סופק כפרמטר לcreateServer היא תרוץ כל פעם שתהיה בקשה (כל ריענון של הדף).
צריך להבין שכלל הקוד שכתבנו רץ פעם אחת מייד עם הפעלתו ע"י נוד או ע"י F5 כפי שעשינו. הוא מבוצע מיידית, אחת ולתמיד. אבל הפונקציה הזו היא בדיוק להיפך, היא לא רצה מייד, אלא כל פעם שיש בקשה, הsever מריץ אותה והיא מתבצעת.
בא נעבור עליה: יש בה מבנה פונקציה רגיל, שם (איזה שבא לנו), שתי פרמטרים (עם שמות איזה שבא לנו כבל פונקציה). בגוף הפונקציה יש שני שורות שניהם עושים שימוש באובייקט res שמייצג את הresponse, הוא סופק לנו על ידי אותו אחד שהפעיל את הפונקציה בבוא בעת של הבקשה, הלא הוא יקרינו השרת.
השורה הראשונה כותבת לתשובה, מלל, השניה פוקדת על סיום הבקשה, סגירת ה"שיחה".בהודעה הבאה נוסיף טיפה דינמיות (=היפך מסטטי, סטטי = מצב בלתי משתנה, תמיד התשובה היא זהה - hello world)
לקוד שלנו. -
ניתוב, הקדמת רשות
המושג ניתוב (route) באנגלית, זה "כיוון תנועה", למשל איש בדלפק מודיעין של משרד הפנים מנתב את הנכנסים לעמדות שונות בהתאם למה שהם צריכים.
בשרת אינטרנט המושג ניתוב בא לציין מי יטפל בבקשה, בהתאם לתכונה ובד"כ בהתאם לנתיב שלה. הנתיב זה מה שכתוב בדפדפן אחרי שם הדומיין, כלומר מהלוכסן שאחרי השם.אם כבר אנו מנתחים את הכתובת בא נעשה את זה יותר. ניקח למשל את הכתובת דוגמא הזו:
http://example.com/store/item/30?val=50&result=video#desc25נמחיש בתמונה את החלקים:
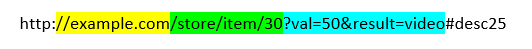
למכלול הזה אנו קוראים URL שפירוש המונח הזה זה כתובת שמצביעה על תוכן/פעולה, באופן ייחודי (אין כפל של כאלה כתובות ברחבי הגלקסיה - כי צייננו גם שם דומיין).
הURL הזה מרוכב מהפרטים הבאים:- http: סכמה - פרוטוקול גישה.
- //example.com משני הלוכסנים (עד הלוכסן הבא אם ישנו) זה הדומיין/host/שם המחשב (זה מתורגם לכתובת פיזית ויכול להיות ישירות כתובת פיזית כמו הכתובת 10.0.0.127:3000 שהיא הכתובת של המחשב הנוכחי).
- /store/item/30 - נתיב, באנגלית path. כל מה שאחרי הלוכסן הראשון (עד סימן שאלה או סולמית אם ישנם).
- ?val=50&result=video נקרא Query או Query-string. זה סט של צירופים, של שם תכונה, סימן =, וערך (מוכר בתכנות כ"מפתח וערך"). לציון תחילת הquery יש סימן שאלה, ולהפרדה בין סטים של צירופים (כמו במקרה שלנו שיש שתיים) משתמשים בתו &.
- #desc25 - נקרא fragment, זה כל מה שמהסולמית ואילך.
רוב החלוקות הללו הם מוסכמות שגורמות לדפדפן וגם לשרת האינטרנט להתנהג בהתאם.
מי שמגיע מphp או מasp או מסתם דפים סטטיים, רגיל שהנתיב דומה למערכת קבצים ממש - ב"תיקיה של האתר" (שזה באמת תיקיה של קבצים שנמצאת בשרת) יש קבצים וגם תיקיות משנה. אבל זו לא התנהגות מחוייבת בכלל, זו פשוט ההתנהגות האוטומטית של תוכנות שרתי האינטרנט הנפוצים (אפאצ'י וIIS ועוד).הנתיב הוא סה"כ עוד פרט בבקשה
כאמור בקשת אינטרנט היא מכתב טקסטואלי, שתמיד ממוען לכתובת המחשב המשוייכת להhost/דומיין, בלי קשר לנתיב.
ניתוב כזה או אחר זה סה"כ הבדל קטן בשורה הראשונה של הבקשה, שאם כבר, בא ננתח אותה.
בפניה לדף הבית (כלומר שורש האתר, שם האתר/דומיין ללא המשך), שתי השורות הראשונה של מכתב הבקשה נראית ככה:GET / HTTP/1.1 Host: example.comבשורה הראשונה יש שלושה מקטעים:
- מתודה (ניגע בהמשך, לא לפחד): GET
- נתיב / (כלומר כלום, / מציין שורש).
- HTTP/1.1 שם הפרוטוקול וגירסתו (לא ניגע בהמשך).
לעומת זאת בגישה לכתובת http://example.com/store/item/30?val=50&result=video#desc25 השורה הראשונה נראית בהתאם:
GET /store/item/30?val=50&result=video HTTP/1.1 Host: example.comנ.ב. חדי העין אולי שמו לב שהסוף, הלא הוא הפרגמנט #desc25, לא נמצא במכתב כלל, ואכן הדפדפן לא טורח להודיע לשרת על קיומו.
-
שיעור 4, דינמיות
מעכשיו ואילך נתחיל לכתוב משהו אמיתי. קיבלנו נניח הזמנה לבנות אפליקציית ווב "מורכבת", - רשימה.
האפיון שקיבלנו:
א. אפשר להוסיף פריט לרשימה
ב. אפשר לראות את הרשימה
בשביל זה נשתמש בניתוב (בסיסי ופרימיטיבי) בו נבדיל בין שתי כתובות:
לכלל הרשימה, localhost:3000, ולהוספת פריט לרשימה, localhost:3000/add-item.בשביל הניתוב אנחנו צריכים בגוף הפונקציה הנ"ל לבדוק מה הנתיב עימו הגיעה הבקשה.
איפה נוכל לדעת את זה?עבור כך, וסתם ככה כפרקטיקה ספציפית לנוד שזו פלטפורמה עניה בתיעוד, נשתמש בכלי החזק שעומד לרשותנו: מצב הדיבאג של תוכנת Visual Studio Code (כמה ארוך! להלן VSCODE, אוקי?).
נקודות עצירה ומצב DEBUG בVSCODE
בא נחזור לקוד שלנו, ונשים נקודת עצירה בשורה 4, זו:
res.write('Hello World');איך שמים נקודת עצירה? לוחצים בשורה הרצויה על השולים שלה שלשמאל מספר השורה. זה יצור שמה עיגול אדום יפה.
מאי משמע נקודת עצירה? זה כלי רב עוצמה בעורכי קוד של שפות תוכנה שמאפשרות מצב של "דיבאג" בה מריצים את התוכנה ואפשר לעצור אותה בשורה מסויימת שסומנה מראש לשם כך, ולצפות בערכי המשתנים המקומיים ולהבין מזה הרבה דברים.אחרי ששמנו נקודת עצירה נריץ את האפליקציה ע"י הקשה על F5, וניכנס לקישור הזה: http://localhost:3000/add-item. נחזור מייד לVSCODE, שם נמצא אותו עם שורה מודגשת, הלא היא שורה 4.
המצב כעת נקרא מצב DEBUG (שזה "פתרון בעיות קוד" בשפת מתכנתים - הפירוש המילולי הוא משהו כמו נטרול ג'וקים...).
יש שפע מידע שימושי מאוד במצב זה, ואני ממליץ בחום להכיר אותו בהמשך הרבה.
כעת נרחף עם העכבר על הפרמטר req בפונקציה, כדי לצפות בערכו האקטואלי נכון לרגע העצירה.
אני מצרף צילום מסך של החלון הצף שקופץ בעת ריחוף על המילה req:
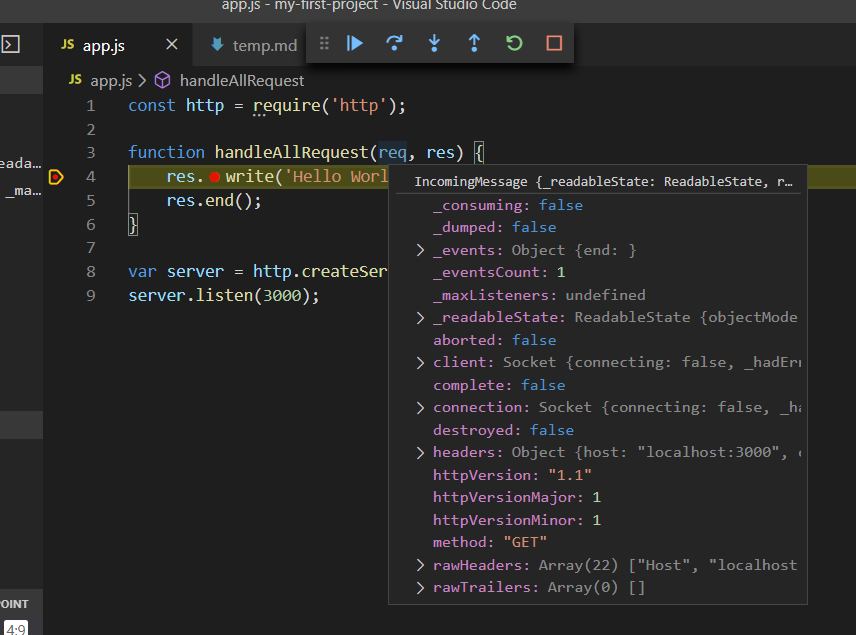
חלון צף זה מראה לנו בעצם את ערכו של req... כפי שאתם רואים לא מדובר בערך יבש כמו טקסט או מספר, אלא באובייקט בעל המון מאפיינים שהVSCODE מראה בעץ מרשים... בעת שהעכבר על החלון הצף תוכלו לגלול כלפי מטה ולמצוא בתחתית הרשימה מאפיין צנוע בשם url שמכיל את הערך "/add-item". יש! אנחנו יכולים לעשות כעת ניתוב בסיסי לאפליקציה "רשימה" שהזמינו אצלנו.
רשות - פרקטיקות בסיסיות במצב הדיבאג
זה לא תמיד כ"כ נוח לחפש מאפיינים בעומק החלון הצף. יש דרכים ממוסדות יותר. לבדיקה של ערך באופן חד פעמי נוכל למטה בשורה שתחת החלונית debug console למצוא מקום בו ניתן להקליד כל ביטוי שנרצה וללחוץ על אנטר ולקבל את הערך שלו בהתאם לנקודת הזמן שלנו. למשל במקרה שלנו אפשר לכתוב שמה req.url וללחוץ אנטר.
.
אם נרצה לעקוב אחרי ערך שוב ושוב נוסיף אותו לחלונית watch שנמצאת בפאנל השמאלי. בלחיצה על סמל הפלוס שבכותרת החלון או בקליק ימני > add expression נוכל להוסיף ביטוי כמו req.url ותמיד לצפות בערך בכל עצירה שתהיה.בהודעה הבאה נכניס מין if בקוד של הפונקציה, לטיפול שונה במקרה שהreq.url שווה ל"/add-item".
-
שיעור 5
תקציר: אנו באמצע לכתוב אתר "משוכלל" בו יוכלו להוסיף פריט לרשימה ולצפות כמובן ברשימה.
החלטנו על שני כתובות, אחת להוספת פריט, ואחת לרשימה כולה. בדקנו איך אנו יכולים לדעת בתוך הפונקציה את ה"פרט" הזה שנקרא כתובת, ומצאנו אותו כמאפיין url בפרמטר req. כיון שכן נתחיל בבניית שלד לקוד האתר:const http = require('http'); var list = []; function handleAllRequest(req, res) { if (req.url == '/') res.write('Hello To List Page!'); else if (req.url == '/add-item') res.write('Hello To Item-Add Page!'); else res.write('Opss... Not Found!'); res.end(); } var server = http.createServer(handleAllRequest); server.listen(3000);הכרזנו פה בשורה 3 על משתנה בשם list ושמנו בו מערך ריק. בו יהיו הפריטים של הרשימה.
להזכיר, נוד מריץ את הקוד פעם אחת בלבד. הפוקנציה handleAllRequest יוצאת דופן כי אותה ביקשנו להריץ לכשתהיה בקשה, וליתר דיוק כל פעם שתהיה. לכן, המשתנה list בעצם מוכרז ומאוכלס במערך ריק פעם אחת, אבל הוא נגיש מתוך הפוקנציה handleAllRequest לאורך כל חיי האתר.בשורות 6-11 אנו בודקים את ערכו של המאפיין url ופועלים בהתאם (אחד לשורש האתר, add-item יביא לדף יכיל טופס להוספת ערך, וכל כתובת אחרת תיתקל בסוג של 404...). בינתיים זה רק שלד, בהמשך נצטרך לעשות יותר בכל מצב.
קצת html וגם על content-type וכותרות (headers)
בשביל שצד הלקוח יתקשר עם צד השרת, אנו חייבים טופס בו ניתן לרשום ערך, וכפתור שליחה יפה.
בשביל זה אנו צריכים לעבוד עם HTML ולא עם טקסטים כמו שעשינו עד עכשיו.
בשביל לשלוח ללקוח HTML לא די לשנות את הטקסט לHTML אלא יש להסביר לדפדפן שהתוכן הוא HTML, עושים את זה באמצעות כותרת בשם content-type (דיברנו על כותרות קצת בעבר, ונייחד לזה שוב דיבור כשנגיע למושג עוגיות שם נרחיב, כך שכעת אפשר לחפף). וזה אומר שנכתוב בפונקציה שלנו כזה קוד:function handleAllRequest(req, res) { res.setHeader('Content-Type', 'text/html'); if (req.url == '/') res.write('Hello To List Page!'); else if (req.url == '/add-item') res.write(`<form> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); else res.write('Opss... Not Found!'); res.end(); }בלגן. ובכן,
בשורה 2 אנו מגדירים (דרך הפרמטר res שמייצג את אובייקט התשובה) כותרת באובייקט התשובה. בגלל פונקציה זו תתנוסס במכתב-התשובה שלנו השורה content-type: text/html דבר שישפיע מאוד על יחס הדפדפן לתוכן - הוא לא יציג תגיות, אלא טקסט מובנה/מעוצב בהתאם לתגיות.
בשורות 6-11 השתמשנו עם טילדה (התו הזה: `) כדי לעשות מחרוזת טקסט מרובת שורות, בה כתבנו טופס HTML צנוע (ובלתי חוקי, כי הרי מסמך HTML יש לו כללי פתיחה והמינימום שלו ארוך בהרבה! אבל כל עוד הדפדפן מגלה יחס סובלני, וזה טוב ללימוד דוגמה קומפקטית, אז למי אכפת?). מייד נדון על תוכנו של הטופס שכתבנו.
תריצו ותיכנסו לכתובת http://localhost:3000/add-item ותראו את הטופס הHTML היפה שיצרנו.HTML, הקדמת רשות (קצרה ולא מסבירה, רק ריענון. להרחבה אנא שאלו בפורום):
HTML הוא פורמט/תחביר כתיבה שכולל תגיות (הסוגריים הזויותיות הללו <>), תכונות (מפתח ערך, בסגנון הזהאני="אתה") וערכים (התוכן שבין צמתי התגיות והערכים של התכונות.
זה קובץ טקסט עלוב, ככל טקסט אחר, אלא שהדפדפן קורא אותו ואינו מציג אותו כפי שהוא, אלא אחרי "הבנה" של המוסכמות על התגיות והתכונות והערכים שבהם.
הוא נוצר בראשית ימי האינטרנט להצגת מסמכים. מסמך טקסט רגיל הוא "שטוח" חסר מבנה ויכולת לעצבו.
לעמות זאת מסמך HTML מאפשר להגידר היררכיה וחלקים במסמך, לתאר אותם הן ע"י שמות התגיות והן ע"י התכונות וגם ע"י מיקומם בהיררכיה של התגיות. בהתחלה השתמשו חזק מאוד בHTML כדי לעצב ישירות את מראה המסמך הסופי, אך מאוחר יותר הבינו שלא חכם לערבב חזות עם מבנה, וכיום מאוד משתדלים שHTML ישמש נטו לעיצוב מבני (כמו כותרת, קטע, כפתור וכו'), ולא לצרכי עיצוב (כמו טקסט אדום).
בראשית ימי האינטרנט שרת היה יודע תמיד למפות נתיב של בקשה לקבוץ הנכון וככה להגיש קבצים סטטייים- בלתי משתנים. בהמשך התפתחות האינטרנט התחילו לפתח שרתים דינמיים שהגיבו לבקשות חיפוש למשל, וייצרו דף HTML שהכיל תוצאות מחיפוש שבוצע בצד השרת. בשביל זה הכניסו בפרומט הHTML תגיות ותכונות מיוחדות שאפשר להכליל אותם בכותרת "טפסים". ועל כך בקטע הבא. סיום ההקדמה.טפסי HTML, ומתודות HTTP
טפסי HTML הם מכלול התגיות והתכונות שרלוונטיות ליצירת אינטראקציה בין הדף לבין השרת.
האלמנט הראשי של טפסי HTML הוא התגית Form. היא נדרשת תמיד בטופס HTML, וכל הקלט של המשתמש צריך להיות "עטוף" בה.
אלמנט שני וכמעט אחרון זה הinput. זה אלמנט שבו המשתמש יכול להזין/לפעול ערך/פעולה שהטופס ישלח לצד השרת. יש המון סוגים של input שנקבעים לפי הtype, כמו text, number email וכו'. יש סוג שנקרא submit שהוא סוג שמוצג ככפתור "שליחה". לחיצה עליו בטופס תשלח את הטופס על ערכיו לצד השרת.מאי משמע "תשלח"? בדואר אויר? איך, ולאיפה?
ובכן הערכים יישלחו בבקשת אינטרנט, שאנו לא מפסיקים לדבר עליה.
נחזור לבקשת אינטרנט:
השורה הראשונה של בקשת כניסה לדף http://localhost:3000/add-item נראית ככה:GET /add-item HTTP/1.1המילה GET היא המתודה, אחת מכמה מתודות שיש בפרוטוקול HTTP. מתודה אחרת שמעניינת אותנו כעת היא POST.
בקצרה נאמר בGET זה בקשה "ריקה", כמו כל הזנת כתובת בדפדפן ואנטר, וPOST זה בקשה "מלאה, אפשר לשים בה תוכן מעבר לכתובת ולכותרות (התוכן נמצא אחרי הכותרות - מה שמבדיל ביניהם זו שורה ריקה).עוד הבדל חושב: מתודת GET נועדה עבור בקשות "קריאה בלבד" כלומר בקשות שלא נועדו לעשות שינוי כל שהוא בעולם. למשל בקשת רשימת ערכים זו בקשת קריאה. בקשת הוספה מחיקה ועדכן הם בקשות שמבקשות לעשות שינוי, ואמורים שלא להתשמש במתודה GET עבורם (אין לכם במועדפים כתובת שלחיצה עליה שולחת מייל למשל, נכון?).
למרות שהמתודה GET לא עשויה לשלוח נתונים של ממש, אבל אי אלו פרמטרים לבקשה. במתודת GET הדרך להעביר אותם היא בquery, אותו חלק אפשרי של הURL שפעם סיפרנו עליו שמתחיל בסימן השאלה, עד לסופוף הכתובת (או לסולמית אם ישנה)
נחזור לטופס שלנו, הוא נראה ככה:
<form> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>תגית הטופס (form), היא המפתח לפעולה של הדפדפן בעת השליחה.
בטופס הזה יש רק שני רכיבי קלט משתמש, אחת לטקסט ואחת לכפתור השליחה. לכפתור הטקסט יש תכונה (attribute) שנקראת name שעשויה להצמדה על הערך שהמשתמש יכניס, שנדע תחת איזה שדה בטופס הוא הוזן (שהרי יכולים להיות כמה וכמה שדות).
באלמנט הform יש שני תכונות אופציונליות (=בלתי נדרשות לפעולה תקינה) אחת בשם action והשניה בשם method.
action קובע לאיזה כתובת הדפדפן ישלח את הבקשה ובהתאם יקבע את הכתוב בשורת הכתובת.
במידה והactio לא קיים, הברירת מחדל היא הכתובת הנוכחית. זה מה שיקרה אצלנו.
method קובע באיזה מתודת HTTP תהיה הבקשה, GET או POST. אם שולחים בPOST הערכים יהיו ב"מכתב" הבקשה, אחרי שורה ריקה שאחרי הכותרות. במקרה של GET הנתונים יישלחו בכתובת עצמה, אחרי סימן שאלה להפרדה בין הכתובת לנתונים.
בשני המקרים, הנתונים יעוצבו בפומט כזה שם=ערך&שם-אחר-ערך&שם-נוסף=ערך.
תוכלו לנסות לשים ערך בטופס שלנו בכתובת http://localhost:3000/add-item ולצפות בכתובת שהדפדפן הוביל אליה. התשובה שמתקבלת היא לא מעניינת (אנו מקבלים Opss... Not Found! כי לא תכנוו אפשרות של כתובת עם סימן שאלה אחרי הadd-item).המתודה GET לא מתאימה עבורינו, כי אנו הולכים לעשות שינויים בצד שרת, לכן בא נכתוב בטופס ככה:
res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`);שינינו פה רק שתי מילים, שהוספנו את התכונה
method="POST"לאלמנט הטופס.
כעת נריץ שוב (בעת הרצה בVSCODE יש סרגל צף של אפשרות הפסקת ההרצה, ויש גם כפתור להתחיל מחדש, שימושי!) וניכנס לכתובת http://localhost:3000/add-item נכניס ערך ולחץ על ה"שלח", לא יקרה משהו מיוחד, אבל עשינו כל מה שדרוש בצד לקוח!בשיעור הבא נדבר על טיפול בטפסי HTML בצד שרת.
כמו"כ נראה לי שנעביר את הקוד של הHTML לקבצים בפני עצמם. -
סליחה על ההפסקה הארוכה, טוב מאוחר מלא כלום...
ראשית לפני ההמשך, במידה ואתם לא יודעים JavaScript, אנא למדו אותה! המדריך הנוכחי הוא לא דרך ללמוד את השפה. בואו למדריך הזה עם ידע מספיק בJS בשביל לכתוב ממש קוד של עשרות שורות. ולא הביישן למד: תרגישו בנח לבקש עזרה אפילו "תת-רמה" בשאלות בפורום. פתחו ניק חדש למקרה של "בושות". כמו"כ כל פיסת קוד פה שאתם לא מבינים מזוית השפה, אסור לכם לחכות, זה לא יובהר בהמשך המדריך בשום צורה.. ת-ש-א-ל-ו! (או תחפשו באינטרנט מצידי).הקדמה לשיעור 6, ארכיטקטורה של טפסי HTML וקצת על נוד.
תקציר וריענון
קודם כל לקלות המצטרפים אנחנו אוחזים בשלב של קובץ בודד בשם app.js שמכיל את הקוד הבא:
const http = require('http'); var list = []; function handleAllRequest(req, res) { res.setHeader('Content-Type', 'text/html'); if (req.url == '/') res.write('Hello To List Page!'); else if (req.url == '/add-item') res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); else res.write('Opss... Not Found!'); res.end(); } var server = http.createServer(handleAllRequest); server.listen(3000);בעת הרצה של קובץ זה בF5 בVSCODE, אפשר להיכנס לכתובות הבאות:
http://localhost:3000/ - רואים כיתוב Hello To List Page!
http://localhost:3000/add-item - רואים טופס ובו שדה בודד, עם לחצן שליחת נתונים. משום מה הכיתוב הוא באנגלית, אולי נגיע להסביר למה. בהמשך הכל יהיה עברית טהורה, אל דאגה!
הטופס הוא מסוג POST שהוסבר לעיל: מתודת POST פונה לכתובת (URL) אבל עם "מסוגלות" לשלוח נתונים בגוף הבקשה, קרי לא בURL. משמעות הצורה היא: נפח בקשה גדול, שיש מוסכמה שאופי הבקשה היא ביצוע פעולה (הדפדפן יתריע במקרה של ריענון, וגם לא ישמור את ה"ביקור" בהיסטוריה).
השליחה לא עושה משהו בינתיים.וכמו תמיד, שוב הקדמת חובה מייגעת של דברים שכבר נאמרו...
כאמור בהודעה האחרונה בטופס HTML יש שני דרכי שליחה POST וגם GET, אבל שניהם עושים כמעט אותו דבר.
הם לוקחים את ערכי הקלט ואת שמותיהם בהתאמה בפורמט הבא:
שם-שדה-ראשון=ערך&שם-שדה-שני=ערך2&שם-אחר=ערך3&גיל=15
ושולחים אותם לשרת (לכתובת שנבחרה בaction ואם לא נבחרה כזו אז לכתובת הנוכחית).
איך שולחים? רק פה ההבדל במתודה. בGET, זה נוסף לנתיב, כלומר הכתובת כולה נראית למשל ככה:
http://site.com/some-path/add-product?name=camera&value=50
כלומר התוכן מצורף לכתובת אחרי סימן שאלה שמפריד בין הכתובת לבין ערכי בקשת הGET בפורמט האמור.
במתודת POST הכתובת נשארת http://site.com/some-path/add-product בלבד ללא כל תוספת, אבל בגוף הבקשה נוכל לראות* את התוכן הזה שם-שדה-ראשון=ערך&שם-אחר=ערך2&גיל=15 בלי סימן שאלה מקדים.*איך? אפשר למשל בדפדפן בכלי הפיתוח, בלשונית Network בבחירת בקשת POST בכרטסת Headers למטה תחת Form Data או Palyload.
הערה: שני הקטעים הבאים, הם רשות. לא מזיק בכלל לקרוא אותם..., אבל אפשר להתעייף ולעבור לשיעור 6 - טפסי HTML, צד שרת
גוף בקשת הPOST
הוא תיאורטית ארוך...
המונח גוף הבקשה נקרא בשפת המקצוע body, או גם payload.
הוא בעצם כל תוכן הבקשה, החל מאחרי הכותרות שכמה שקובע איפה נגמר הכותרות זה שורה ריקה.
אין הגבלה עקרונית לגודל בקשה (מעשית יש ברוב המקרים וגם מצד הפרקטיקה), ממילא הPOST מסוגל להעביר הרבה מידע לשרת, בשונה ממתודת GET ששם זה הכתובת עצמה שיש לה הגבלות רשמיות כאלו ואחרות.
למה כל זה משנה כעת? כי כשבאים בnode לחפש את הbody של בקשה (כפי שעשינו במקרה של הurl) לא תמצאו אותו במאפיינים של הreq. למה? כי הוא אפילו לא הגיע לשרת. כלומר מייד כשמתחילה להגיע בקשה, הnode מטפל זה (וזה קורה מהר! כשברקע גוף הבקשה ממשיך להיטען). במידה ונדרש גם תוכן הבקשה, יש לבקש מנוד "להודיע" כשזה ייגמר, ואז להיכנס לפעולה."אתה יכול לקרוא לי כשגמרת?" callback ואירועים - Events
הבקשה הזאת לבקש מנוד ש"יודיע" כשהבקשה סיימה להתקבל, נקראת (בעולם התכנות) ל"הירשם לאירוע". כשקורה האירוע - במקרה שלנו סיום קבלת הבקשה מהלקוח, כל מי שהיה "רשום" לקבל הודעה מקבל אותה. צורת הרישום כבר מוכרת לנו, השתמשנו בה בhttp.createServer. סיפקנו שמה בסוגריים של פונקציה שיש להפעיל כאשר קורה אירוע של בקשה חדשה.
צורת ההירשמות הזו של http.createServer נקראת callback, משמעות המילה הזו מקפלת בתוכה call back (קריאה בחזרה): "כשתגמור את מה שאני אומר לך עכשיו, חזור וקרא לX". זה בפועל מממש את רעיון האירוע כי אפשר ככה ל"הירשם" לכל אירוע ע"י שמספקים למי (במקרה שלנו מודול הhttp של נוד) שיודע מתי שיקרה משהו (במקרה שלנו בקשה אינטרנט חדשה) שיודיע לנו - יפעיל את הפונקציה שסיפקנו.
הערה: בדרך כלל callback לא בא לממש את רעיון אירוע שרעיונית הוא רב פעמי (כל פעם שקורא בקשה תפעיל את X), אלא את רעיון המשכיות של פקודה (כשאתה גומר את זה תעשה את זה). ברוב שפות התכנות כשיש שתי שורות קוד, השניה תקרה תמיד אחרי שהראשונה תסיים לחלוטין וגם בJavaScript זה ככה, אולם בJavaScript כל פקודה שקשורה לקלט פלט (קבצים רשת ועוד) היא מסתיימת כביכול מיידית, בחינת "שגר ושכח", אבל עם callback - קרי "מה לעשות כשאני באמת אגמור". אם רוצים שהשורה שלאחריה תקרה רק בסיומה הרי שיש להעבירה לcallback ולא לשים אותה סתם שורה אחריה.התכונה הזו של נוד שכל דבר שלוקחת זמן יש "להירשם" כדי לבצע דברים בעקבות סיומה, היא מעצבנת הרבה מפתחים שבאים ממחוזות בעלי השקפה שונה, אולם היא עיקר המעלה של נוד בביצועים, והביצועים של נוד הם מדהימים בעיקר במובן הזה. כך שמאוד כדאי לכוף את האזן ולשמוע ולהתרגל עד ש... נהנים.
נוד, וספריות
הקדמה: בין מי שמכיר את נוד, בין מי שלא, וקל וחומר מי שמגיע ממחוזות אחרים, יכול לתהות:
- למה דברים כ"כ פשוטים צריכים כ"כ הרבה קוד וסיבוך?
- למי שמגיע ממחוזות דוטנט או PHP , לכשיראה בהמשך שנעבוד עם ספריות תעלה השאלה - איך במדריך "לפי הספר" של א' ב' של סביבה, נכנסים ספריות? הרי זו התחלה על רגל שמאל לכל סביבה שמכבדת את עצמה שכבר במדריך הראשוני, בGet-Started מדברים על פלאגין/הרחבה שמשמעותם שהסביבה "שכחה" יכולת זו או שהיא שולית בצורך הפיתוח.
- למי שמכיר את נוד הנוסח הוא: למה הוא לא משתמש בexpress או בXYZ וכו'?
התשובה על 1+2 היא: נוד זה ליבה כה רזה, שאי אפשר לפתח בה משהו אמיתי בלי ספריות.
למה עשו כזה דבר? כי זה הדרך המודרנית בסביבות עבודה ובפרט בקוד פתוח, לעשות הפרדה כלל היותר בין רכיבים ולהימנע ממטריה כוללת של all in one שיש בה כמה נזקים. דמיינו שאנחנו חייבים לקנות את העוף לשבת ואת הסלטים מאותה חברה/חנות.
א. אנחנו נתפשר באחד מהם כי אין לנו יכולת להפריד ולקחת את החנות הטובה לכל אחד מהם, ב. וגם החנות תידרש להיות טובה רק באחד מהם, כי הרי השני כבר "מחוייב". ג. אם אחד ממש יפריע לנו נעזוב את החנות למרות שהשני הוא הכי טוב/זול/מתאים לנו דוקא שמה. ד. היכולת של החברה/חנות להיות טובה יותר בשני תחומים נופלת בהרבה מהיכולת להיות הכי טובים/זולים/מתאימים בתחום אחד
שימו לב למילים "מתאים לנו", כי כמו שבאוכל כל אחד מבין שגם ברמה התיאורטית אין הכל "הכי טוב", שהרי יש מי שמתאים לו ככה ויש אחרת, ככה ויותר זה גם בפיתוח. למרות שיש דרישות נורמליות של רוב היישומים בצרכים, זה רחוק מלהיות אמיתי לכל מקרה. כלומר תמיד יש צורך בהתאמות או בהתנהגות שהיא היפך הצורך הרגיל, ממילא גם אם מתכנתי סביבה הם מלאכים, הרי בשביל שהמוצר שלהם יתאים לכולם תמיד הם צריכים לפתח מאה אלטרנטיבות והגדות לכל יכולת.
לכן כל סביבת עבודה חדשה שמפתחים היום (למעט סביבות שבאות לטפל בחלק שולי או נקודתי של מערכת) נזהרת בעניין הזה - א. לתת חופש מלא למפתח להשתמש לצרכים אחרים בדברים אחרים, ב. להתמקד בנושא אחד ולא להתפזר.
אז אם ככה דרך המלך להשתמש טוב בנוד זה לחבר אליה אליה ספריות מובילות של נושא שאני זקוק לו לפי ההתאמה אלי. מכאן אנו עוברים לשאלה 3, למה אני לא משתמש במדריך פה בספריות, הרי זה לא שייך ככה לכתוב אפליקציה.
התשובה על שאלה 3 כבר נאמרה ברמזים כאלה או אחרים בעבר: המדריך פה אינו לנוד, אלא לפיתוח אינטרנט. כל הסיבה שבחרתי בנוד זה כדי לעקוב אחרי הצרכים ב"קיצורים" וספריות. לראות איפה צריך אותם ובעיקר מה הם עושים, שהשימוש בהם לא יהיה "קסם" שגורם לתלות ולערפל גמור בנבכי העניין אלא כלי שמבינים עם מה הוא מתמודד ומה יכולותיו ותו לא.
אנחנו ממש קרובים לשלב שבו נעבור לשימוש בספריות מפורסמות שיקלו את החיים באופן דרמטי. -
קדימה, ממשיכים:
שיעור 6 טפסי HTML, צד שרת.
כעת א. נקבל בצד השרת את תוכן הבקשה בPOST מהטופס ששלחנו בadd-item, ב. ננתח אותו (כי הוא כתוב בפורמט הנקרא querystring של א=1&ב=2 ובמקרה שלנו משהו כמו the-name=דוגמה), ג. נוסיף את האיבר החדש לרשימה list ו... בינתיים זהו.
איך עושים את זה? פשוט מאוד? אוי ממש לא. מסובך, אבל לא נורא. בא נעקוב.
ראשית נשנה את הקוד הראשי של המתודה handleAllRequest שמכיל תנאי if שבודק את ערך הURL,
במקום שורה בודדת בכל בלוק בתנאי ללא { }, נשנה את זה כעת לבלוק מרובה שורות לכל מקטע:function handleAllRequest (req, res) { res.setHeader('Content-Type', 'text/html'); if (req.url == '/') { res.write('Hello To List Page!'); } else if (req.url == '/add-item') { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } else { res.write('Opss... Not Found!'); } res.end(); }כאמור לא שיניתי כלום, רק עטפתי כל מקטע בבלוק {}, שמאפשר לעשות שורות מרובות לכל התניה.
כעת, נבדיל במקרה של /add-item האם זה הגיע כGET שזה ביקור הדפדפן בדף או כPOST שזה לחיצת הלחצן בטופס:else if (req.url == '/add-item') { if (req.method == "POST") { // TODO: פה בעצם צריך לקבל את גוף הבקשה, לנתח אותו ואז להוסיף לרשימה (list) את האיבר שהתקבל מהטופס. } else { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } } else { res.write('Opss... Not Found!'); }כפי שרואים בשורה 3, המאפיין method מחזיק את דרך הגישה כטקסט.
אוקי. כעת נכתוב מתודה שתטפל ב: א. קבלת כל הבקשה, ב. ניתוח הטקסט.
נוסיף מחוץ לפונקציה (למשל בסוף הדף לגמרי אחרי כל הקוד) פונקציה חדשה בשם parsePostData שתקבל שתי פרמטרים א. הבקשה, ב. callback - פונקציה להפעלה כאשר היא תסיים את קבלת הבקשה וניתוחה:function parsePostData (req, callback) { }בתוך הפונקציה נאזין לאירוע של הבקשה. יותר נכון לשתי אירועים: 1. קבלת "חתיכת" מידע בגוף הבקשה (עקרונית יכול להיות הרבה, בגלל האופן בו עובד הTCP כל פעם מגיע "גוש") 2. סיום - כל החתיכות התקבלו. למה לא מספיק לנו רק הסיום? כי הנוד גם לא שומר לנו שום דבר שלא ביקשנו, כלומר החתיכות שמגיעות לא נשמרות בשום מקום בזיכרון וממילא בסיום לא תהיה לנו דרך לשחזר מה הסתיים בכלל...
רשות: הפעם זה אירוע ממש, לא סתם callback. הרשמה לאירוע נעשית בJS ע"י המתודה on על האובייקט שמממש אירועים, כשהארגומנט הראשון זה האירוע, והשני זה המטפל - אפשר לקרוא לזה שוב הcallback.
האובייקט req של נוד מממש אובייקט בשם Stream שזה תבנית תכנות מפורסמת, שמייצגת אובייקט שמספק נתונים כזרם - הוא לא מחזיק את הנתונים אלא מספק להם גישה ממש כמו צינור: יש לו פתח קבלה ופתח שפיכה ואפשר להירשם לאירועים שלו כדי לאגור את המידע או כדי לשנות את המידע ולספק אותו הלאה כזרם משלנו וכו'. בנוד יש כמה סוגי זרמים, כתיבה - Writable קריאה -Readable ושניהם. במקרה של בקשה הזרם הוא קריאה - הרי לא ניתן לכתוב לה. האירועים המפורסמים של Stream זה data לגוש חדש שמתקבל (הגוש נקרא בעגה התכנותית buffer וגודלו של הbuffer מותאם בד"כ למיטוב המקסימלי של היכולת הטכנית של הקלט/פלט הרלוונטיים) וend לסיום הזרימה (לא שזה בהכרח חייב לקרות).הנה ככה נראית ההרשמה לשני האירועים:
function parsePostData (req, callback) { req.on('data', function (chunk) { }) req.on('end', function () { }); }יש פה בעצם שתי שורות קוד בלבד, שורה 3 ושורה 7. בשורה 3 אנחנו נרשמים לאירוע data של הבקשה, כלומר כל פעם שמגיע גוש. בשורה 7 אנחנו נרשמים לאירוע end כלומר הודעה על כך שכל החתיכות יתקבלו.
צורת ההרשמה לשני האירועים זהה: אנחנו קוראים לפונקציה בשם on, מספקים לה כטקסט את האירוע המבוקש, ובנוסף מספקים לה כארגומנט שני פונקציה (ריקה בינתיים) חסרת שם (אנונימית) שתרוץ (כל פעם ש)האירוע יקרה.
באירוע של data אנחנו צריכים לאסוף את המידע. אתם בטח תוהים מה יש לאסוף מידע בפיסת מידע כה קצרה כמו שלנו, שזה אמור להיות כמה תווים בודדים כמו the-name=פרה. אבל נוד לא אמור לדעת מה גודל הבקשה, ומבחינתו ככה "קוראים" בקשות - נרשמים לקבלת פיסות מידע.
באירוע של end נדע שהמידע הסתיים להתקבל ורק אז ננתח אותו (ביישומים שונים ניתן לנתח את המידע תוך כדי קבלתו, אבל במקרה של פורמט הנתונים שלנו והצורך שלנו בהם, זה לא שייך).
נתחיל עם איסוף המידע. נקצה משתנה לאיסוף בשם text, ונדאג להוסיף לו כל חתיכה לכשתתקבל:function parsePostData (req, callback) { var text = ""; req.on('data', function (chunk) { text += chunk; }) req.on('end', function () { }); }כעת צריך לנתח את הכל בסיום. לשם כך נשתמש במחלקה בנוד. נעלה למעלה היכן שכתוב const http = require('http'); ונוסיף מתחתיה או מעליה את השורה:
const querystring = require('querystring');כעת נחזור לפונקציה שלנו ונשתמש בספריה כדי לנתח את הtext:
function parsePostData (req, callback) { var text = ""; req.on('data', function (chunk) { text += chunk; }) req.on('end', function () { var result = querystring.parse(text ); callback(result); }); }הניתוח מתבצע ע"י המתודה querystring.parse בשורה 9. הקלט שיהא מקבלת יהיה משהו כמו the-name=פרה והפלט יהיה אובייקט JS יפה כזה { "the-name": "פרה" }.
בשורה 10 אנחנו "קוראים חזרה" להמשך ביצוע: "גמרנו, קח את התוצאה ותעשה איתה מה שאתה רוצה". מי שלוקח את התוצאה זה מי שביקש אותה. בא נבקש אותה בhandleAllRequest במקרה של POST:else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { }); else { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); }בשורה 3 אנחנו מבקשים מparsePostData לנתח את גוף הבקשה, ולכשזה יתבצע להריץ את הפונקציה האנונימית שאנו מספקים לו כארגומנט שני. כעת יש להוסיף את האלמנט לרשימה שלנו, ע"י list.push. הקוד הסופי של כל האפליקציה שלנו ייראה ככה:
const http = require('http'); const querystring = require('querystring'); var server = http.createServer(handleAllRequest); server.listen(3000); var list = []; function handleAllRequest (req, res) { res.setHeader('Content-Type', 'text/html'); if (req.url == '/') { res.write('Hello To List Page!'); } else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { list.push(result["the-name"]); }); } else { res.write(`<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } } else { res.write('Opss... Not Found!'); } res.end(); } function parsePostData (req, callback) { var text = ""; req.on('data', function (chunk) { text += chunk; }) req.on('end', function () { var result = querystring.parse(text ); callback(result); }); }(העליתי את שורות הserver למעלה בשביל הסדר. אפשר לשנות את זה לטעמכם).
כעת בהרצת הקוד וכניסה לדף /add-item ומילוי הטופס ושליחתו יתווסף למערך List הערך שממנו בתיבה. אך הדף יהיה ריק, זאת משום שלא שלא כתבנו שום תשובה לבקשה. נשאיר זאת למחר, תודה שהייתם איתי!בהודעה הבאה נדבר בל"נ: א. פרקטיקות בתשובות לשליחת נתונים, ב. העברות התצוגות לקבצים מסודרים, ג. הקדמה למעבר לexpress.
-
הקדמה:
כעת אני קורא את השיעור הקודם
(למי שמעוניין יש בו את הקוד המלא של איפה שאנחנו אוחזים, מדובר באפליקצייה של דף בודד ותו לא),
ואני רואה שלא ממש גמרנו, צריך גם להראות את הרשימה.
לשם כך אני משנה את המקטע שלif (req.url == '/')שזה מתייחס ל"דף הבית" שלנו, ככה:if (req.url == '/') { res.write('Hello To List Page!<br>' + list.join('<br>') + '<br><a href="/add-item">Add Item To List</a>') ; }זה משרשר כמה טקסטים, בתוכם יש קריאה לפונקציה join של מערך (הליסט שלנו), כשהמפריד הוא הbr שזה אלמנט קפיצת שורה בHTML. בסוף על הדרך שמתי לינק (אלמנט a בHTML) לדף הadd-item להוספת פריט חדש.
כעת אפשר להריץ ולראות בהתחלה בדף הבית לינק להוספת פריט.
כעוברים לדף add-item וכשמזינים את הטופס ושלחים מקבלים דף ריק, אם נחזור ידנית לדף הבית נראה את הפריט שהתווסף בהצלחה.שיעור 7 - שוב על POST וגם על REDIRECT.
הסברתי בעבר שבשביל לשלוח את הטופס לשרת אני משתמש בPOST כי זה בדיוק התפקיד שלו.
למה? זה גורם לפעולה בצד השרת, זה בקשת אינטרנט שיש לה השפעה ולא רק קבלת מידע.
ומה הרווחנו שאנו פועלים לפי הכלל הזה? למשל את התנהגות הדפדפן שבעת ריענון של הדף אחרי השליחה זה יזהיר אותנו מפני פעולה כפולה. בGET זה יעשה את הפעולה שוב בלי אומר ודברים.
בצד שרת אנחנו יכולים לזהות האם הבקשה היא POST וGET בדיוק כפי שאנו יכולים לבדוק מה הURL. אם כן אנו יכולים להעמיס על URL שכבר בשימוש לGET, כמו כאן שכניסה לadd-item מביאה את הטופס, פעולה נוספת במקרה של POST.
השאלה היא מה קורה אחרי הPOST. אם נחזיר חזרה את הטופס בדיוק כפי שהיה, אז ללקוח יהיה תחושה שלא קרה כלום.
מה שמקובל (כל עוד אנו לא בAJAX - לא להיבהל, יילמד בהמשך) זה או להחזיר את הלקוח לרשימה ואז הוא מבין (וגם רואה) שבקשתו בוצעה.
בפשוטת יכולנו לעשות את זה פשוט - להחזיר בres.write את הרשימה, משהו כזה:else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { list.push(result["the-name"]); //בשלב זה אנחנו יכולים לכתוב תשובה ללקוח בדיוק כמו שעשינו בדף הבית res.write('Hello To List Page!<br>' + list.join('<br>') + '<br><a href="/add-item">Add Item To List</a>') ; }); }זה לא טוב. למה? כי למשתמש כעת יהיה בשורת הכתובת כתוב add-item והדף בעצם כעת מכיל רשימה. זה גם מאוד "לא נכון" וגם מבלבל, הוא יכול להעתיק את הלינק הזה או לשמור אותו במועדפים מאוחר יותר בלי להתייחס למה כתוב בו, ולהניח שזה לינק לרשימה, שהרי זה מה שהוא רואה.
אז אנחנו צריכים "לשנות את הכתובת בדפדפן" לדף הבית, ובכן זה בלתי אפשרי. מה שעושים זה גורמים לדפדפן לעבור לכתובת של דף הבית כאילו המשתמש לחץ על היפר קישור. עושים את זה ע"י תשובת Redirect.
יש כמה סוגי תשובות REDIRECT, הם מצויינים בקודים 3xx (כלומר 300, 301 וכו'). הסוג שנדרש לנו הוא 303 - See Other. הוא סוג פשוט שאומר, הכל בסדר, כעת תעבור לX.
המבנה של תשובת Redirect בבסיסה רק כותרת אחת ללא כל תוכן:HTTP/1.1 303 See Other Location: /אבל לא נוכל לעשות זאת מייד,
א. כי בקוד שלנו לפני התנאי בכלל כבר שמנו כותרת בשם 'Content-Type', עם HTML, מה שלא מתאים מקרה הזה.
ב. בקוד שלנו שמנו אחרי התנאי res.end שזה אומר לגמור את התשובה ולסגור את החיבור. הבעיה שבמקרה של הpost שלנו שאנו מוסיפים אלמנט לרשימה, הres.end קורה עוד לפני הוספת האלמנט שכן הוספת האלמנט נעשית כcallback למתודה האסינכרונית parsePostData (כזכור, המתודה parsePostData ניגשת לגוף הבקשה וגישה זו בנויה באופן אסינכרוני = "נודיע לך כזה יקרה", כי הטיפול בבקשה מתחיל עוד לפני שהיא סיימה להגיע).
לשם כך נשנה את הקוד בכמה דברים:function handleAllRequest(req, res) { if (req.url == '/') { var page = 'Hello To List Page!<br>' + list.join('<br>') + '<br><a href="/add-item">Add Item To List</a>'; sendHtml(res, page) ; } else if (req.url == '/add-item') { if (req.method == "POST") { parsePostData(req, function (result) { list.push(result["the-name"]); res.writeHead(303, { Location: '/' }); res.end(); }); } else { sendHtml(res, `<form method="POST"> Enter the item value: <input type="text" name="the-name" > <br> <input type="submit" > </form>`); } } else { sendHtml(res, 'Opss... Not Found!'); } } function sendHtml(res, str){ res.setHeader('Content-Type', 'text/html'); res.end(str); }ראשית הסרנו את הres.setHeader והres.end שהיו לפני ואחרי התנאי, כי באחד המקרים של התנאי איננו רוצים את שניהם.
שנית בנינו פונקציה קטנה לשלוח html בתשובה, כדי לחסוך לכתוב שוב ושוב שלושה שורות: res.setHeader, ואז rew.write ולבסוף res.end. בעצם דילגנו על res.write לגמרי גם בפונקציה כי הres.end מקבלת כפרמטר תוכן בדיוק בשביל לחסוך מקרים כאלה (הwrite עושי למקרה של כתיבות רבות לאותה תשובה, במקרה של בודדת אפשר להשתמש בקיצור הזה).
שלישית, וזה הסיבה שעשינו את כל השינויים, הוספנו אחרי הוספת אלמנט (שורות 9-11) הפניה חזרה ל"דף הבית" כלומר לרשימה.תוכלו כעת לראות אפליקציה לתפארת ששומרת רשימה, אבל כל הרצה הרשימה נמחקת שהרי הכל שמור במשתנה list שבריצת האפליקציה עדיין ריק. אם נרצה לשמור בעולם האמיתי נשתמש כנראה במסד נתונים או בקבצים.
יש לציין שההעברה לרשימה אמנם מקובלת אבל היא לא "100%" מבחינת חוויית משתמש, כיון שיש משתמשים שעד שלא יאמרו להם שזה הצליח, הם לא יהיו בטוחים אם המחשב עשה את מה שהם התכוונו.
בשביל אלו אפשר לעשות העברה לדף אחר, בו כתוב "ההוספה הצליחה!", ומתחת לזה לינק "חזרה לרשימה". יש בזה אבל משהו מייגע עבור יתר המשתמשים. לכן יש כאלה שיעשו שהדף הזה יופיע לשלוש שניות - יהיה כתוב "מעביר אותך לרשימה...". זה בעצם REDIRECT שנעשה בצד הלקוח עם קוד עם השהיית זמן.
יש סיטאוציות שהכי הגיוני זה להישאר באותו הדף של הטופס, למשל אם מטבע הדברים אמורים לשלוח טופס שוב ושוב רצוף (בדוגמה שלנו לשים כמה הפריטים ברשימה). במקרה כזה מחזירים את אותו דף של add-item אבל כותבים איזה חיווי בצד לקוח (למטה או בכותרת צפה זמנית) שהנתונים נשלחו בהצלחה. -
 צ צדיק תמים התייחס לנושא זה ב
צ צדיק תמים התייחס לנושא זה ב
-
א אביחיל התייחס לנושא זה ב
-
Y Y.Excel.Access התייחס לנושא זה ב
-
 C chagold התייחס לנושא זה ב
C chagold התייחס לנושא זה ב