
ספריית החיפוש meilisearch ב-בC#
-
מישהו מכיר את ספריית החיפוש meilisearch
האם מישהו יכול להמליץ לי עליה.
כמו:כ הייתי שמח לדעת האם היא מתאימה לתוכנה שלי תורת אמת בוורד@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
מישהו מכיר את ספריית החיפוש meilisearch
האם מישהו יכול להמליץ לי עליה.
כמו:כ הייתי שמח לדעת האם היא מתאימה לתוכנה שלי תורת אמת בוורדאני כרגע מנסה אותה בשביל פרוייקט שלי, החיסרון המשמעותי הוא הגודל העצום של האינדקס, היא מיועדת בעיקר לשרתים ולא למשתמשי קצה ולכן אין אופטימיזציה של הגודל. אפשר לבדוק אינדקס שעשיתי לחלק מאוצריא כאן:
הצלחתי בינתיים ליצור אינדקס ל86% מהמאגר , זה שוקל 13 ג'יגה, דחסתי ל3.4 ג'יגה, ואפשר להוריד מכאן: https://drive.google.com/file/d/1NatVo7uHiCODzJ-t_NT9qJiVmgxMvBur/view?usp=sharingהוראות שימוש:
יש לחלץ את הקבצים באמצעות zip7
להפעיל את הקובץ בסיומת EXE, לא לסגור את החלון השחור.
לפתוח את הדפדפן בכתובת http://localhost:7700/
לחיפוש מדוייק יש להקיף את החיפוש במרכאות: "ביטוי לחיפוש מדוייק"
בלי מרכאות הוא מחפש חיפוש חופשי לפי רלוונטיות. מעניין אותי לשמוע תגובות על הרמה. -
ניסיתי ליצור פרוייקט דוגמא על פי המופיע כאן:
נתקלתי בשגיאה דלהלן: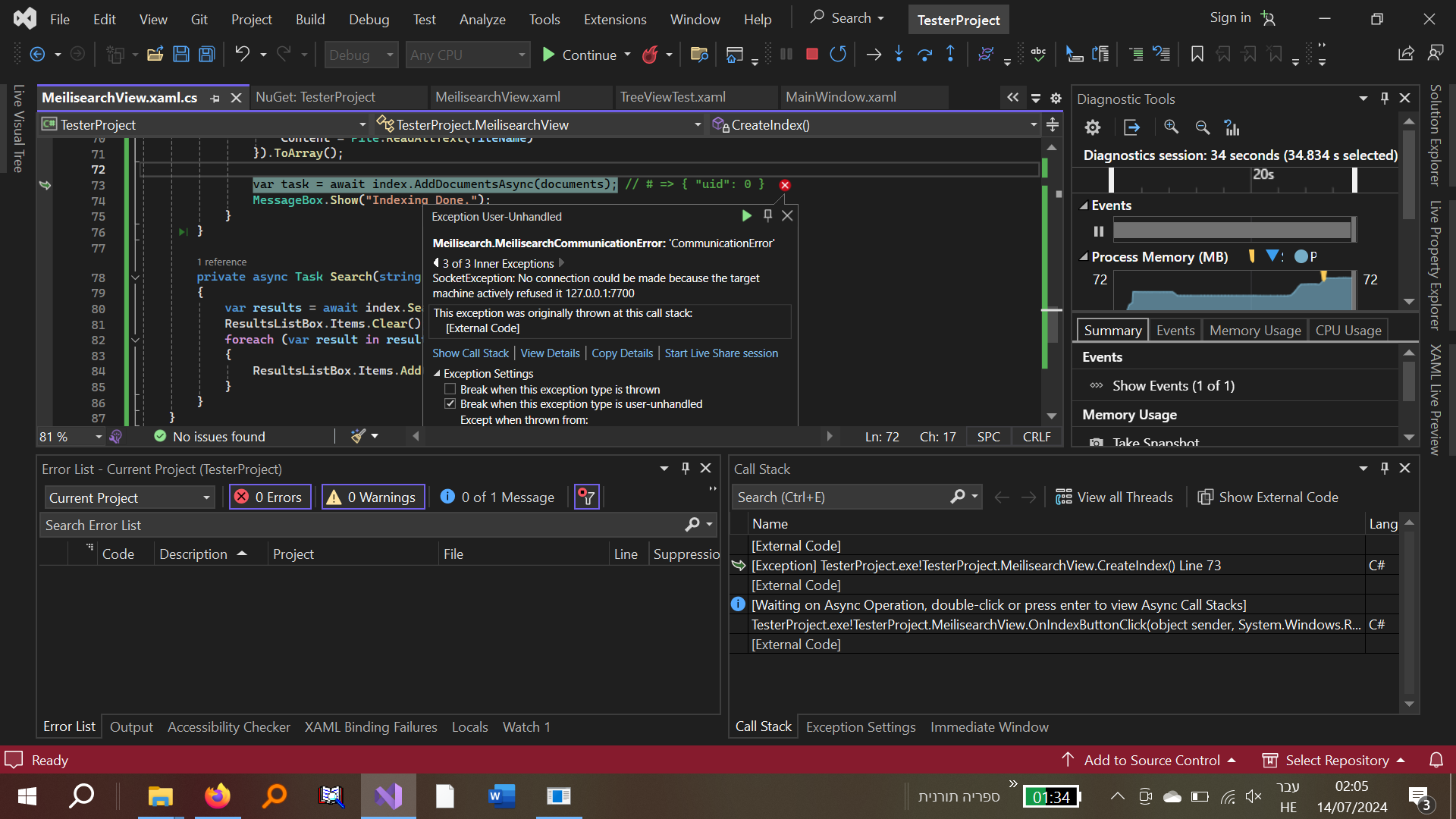
מו"ב הקוד שעשיתי
<UserControl x:Class="TesterProject.MeilisearchView" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:local="clr-namespace:TesterProject" mc:Ignorable="d" d:DesignHeight="450" d:DesignWidth="800"> <Grid> <Grid.RowDefinitions> <RowDefinition Height="auto"/> <RowDefinition Height="*"/> </Grid.RowDefinitions> <Grid Grid.Row="0" Margin="5"> <Grid.ColumnDefinitions> <ColumnDefinition Width="auto"/> <ColumnDefinition Width="*"/> </Grid.ColumnDefinitions> <TextBox Name="SearchBox" Margin="5" Grid.Column="1" Text="ברכות"/> <StackPanel Orientation="Horizontal" Grid.Column="0"> <Button Content="Search" Click="OnSearchButtonClick" Margin="5"/> <Button Content="Index Files" Click="OnIndexButtonClick" Margin="5"/> </StackPanel> </Grid> <ListBox Name="ResultsListBox" Grid.Row="1"/> </Grid> </UserControl>using Microsoft.Win32; using System.Diagnostics; using System.Windows; using System.Windows.Controls; using System.IO; using Meilisearch; using System.Linq; using System.Threading.Tasks; using System; namespace TesterProject { /// <summary> /// Interaction logic for MeilisearchView.xaml /// </summary> public partial class MeilisearchView : UserControl { private readonly MeilisearchClient client; Meilisearch.Index index; private Process _meiliSearchProcess; public MeilisearchView() { InitializeComponent(); client = new MeilisearchClient("http://localhost:7700"); index = client.Index("meiliIndex"); StartMeiliSearch(); Application.Current.Exit += (s, e) => { _meiliSearchProcess?.Kill(); }; } private async void OnIndexButtonClick(object sender, RoutedEventArgs e) { await CreateIndex(); } private async void OnSearchButtonClick(object sender, RoutedEventArgs e) { var searchTerm = SearchBox.Text; await Search(searchTerm); } private void StartMeiliSearch() { string appDirectory = AppDomain.CurrentDomain.BaseDirectory; string meiliFileName = Path.Combine(appDirectory, "meilisearch-windows-amd64.exe"); _meiliSearchProcess = new Process { StartInfo = new ProcessStartInfo { FileName = meiliFileName, Arguments = " --env production", UseShellExecute = false, RedirectStandardOutput = true, RedirectStandardError = true, CreateNoWindow = true } }; _meiliSearchProcess.Start(); } private async Task CreateIndex() { var openFileDialog = new OpenFileDialog { Multiselect = true }; if (openFileDialog.ShowDialog() == true) { var documents = openFileDialog.FileNames.Select(fileName => new MeiliDoc { FileName = fileName, Content = File.ReadAllText(fileName) }).ToArray(); var task = await index.AddDocumentsAsync(documents); // # => { "uid": 0 } MessageBox.Show("Indexing Done."); } } private async Task Search(string searchTerm) { var results = await index.SearchAsync<MeiliDoc>(searchTerm); ResultsListBox.Items.Clear(); foreach (var result in results.Hits) { ResultsListBox.Items.Add(result.FileName); } } } public class MeiliDoc { public string FileName { get; set; } public string Content { get; set; } } }@dovid כתב בספריית החיפוש meilisearch ב-בC#:
יש בהוראות שמה מקטע בשם run-meilisearch
שמה מבואר שצריך להריץ את המופע של התוכנה העצמאית שלהם, אתה יכול להוריד אותה פה:
https://github.com/meilisearch/meilisearch/releases/tag/v1.9.0
בWindows אתה צריך את meilisearch-windows-amd64.exe.תודה אבל זה כבר היה בקוד שלי סליחה שלא הדגשתי חלק זה מספיק.
@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
private void StartMeiliSearch()
{
string appDirectory = AppDomain.CurrentDomain.BaseDirectory;
string meiliFileName = Path.Combine(appDirectory, "meilisearch-windows-amd64.exe");
_meiliSearchProcess = new Process
{
StartInfo = new ProcessStartInfo
{
FileName = meiliFileName,
Arguments = " --env production",
UseShellExecute = false,
RedirectStandardOutput = true,
RedirectStandardError = true,
CreateNoWindow = true
}
};
_meiliSearchProcess.Start();
} -
@pcinfogmach אני חושב שזה לא הגיוני לעשות את זה בקוד, זה אמור לפעול ברקע בקביעות, אם התוכנה שלך תרוץ פעמיים יהיה שגיאה של פורט תפוס. כמו"כ בתיעוד שמה מופיעה בדיקה לוודא שהמופע מאזין.
- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
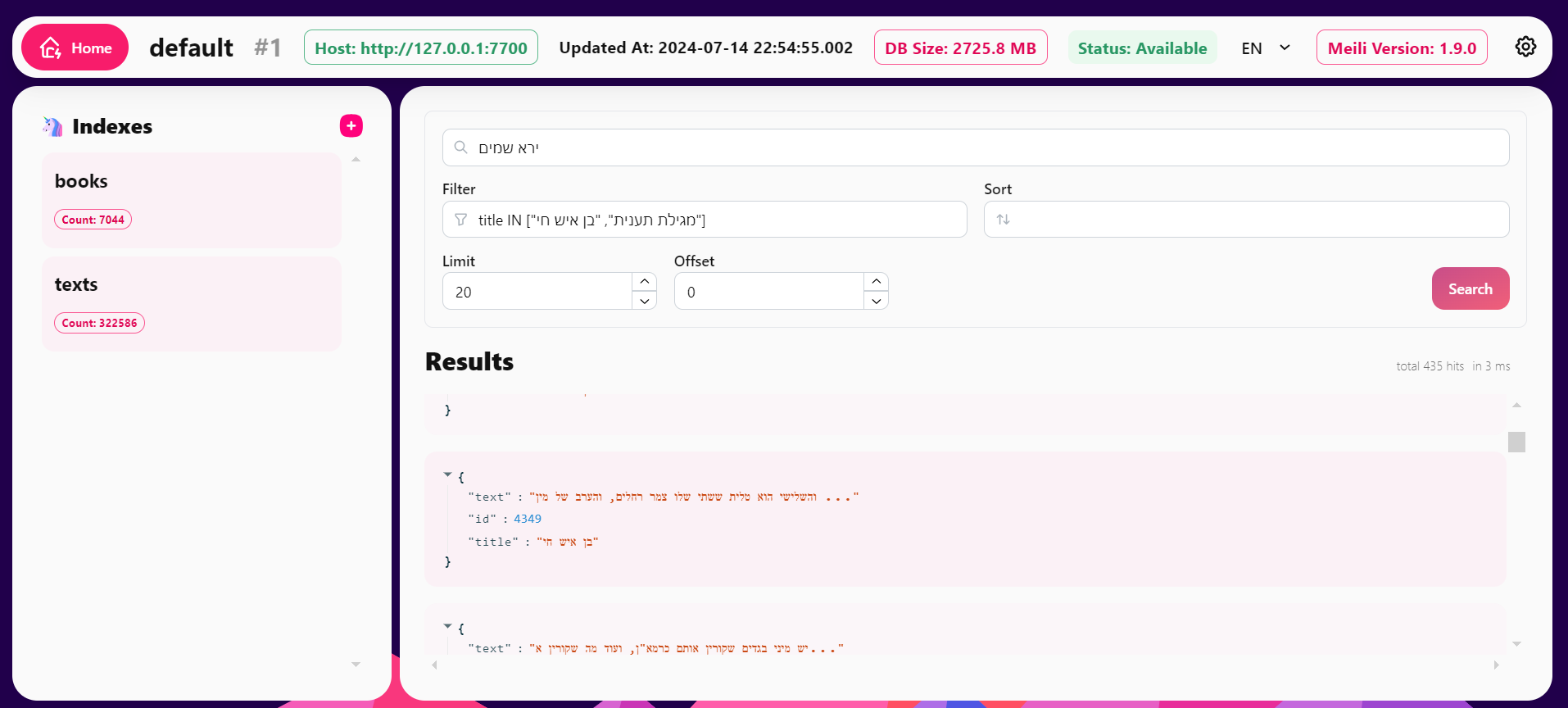
חוץ מהמיני דאשבורד המוגבל שמגיע מובנה, מצאתי דאשבורד מאד נחמד (הצלחתי להריץ עם דוקר): https://github.com/riccox/meilisearch-ui
-
@pcinfogmach אני חושב שזה לא הגיוני לעשות את זה בקוד, זה אמור לפעול ברקע בקביעות, אם התוכנה שלך תרוץ פעמיים יהיה שגיאה של פורט תפוס. כמו"כ בתיעוד שמה מופיעה בדיקה לוודא שהמופע מאזין.
@dovid כתב בספריית החיפוש meilisearch ב-בC#:
@pcinfogmach אני חושב שזה לא הגיוני לעשות את זה בקוד, זה אמור לפעול ברקע בקביעות, אם התוכנה שלך תרוץ פעמיים יהיה שגיאה של פורט תפוס. כמו"כ בתיעוד שמה מופיעה בדיקה לוודא שהמופע מאזין.
אולי לייצר service?
תכלס השגיאה הנ"ל עדיין קיימת
-
@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
מישהו מכיר את ספריית החיפוש meilisearch
האם מישהו יכול להמליץ לי עליה.
כמו:כ הייתי שמח לדעת האם היא מתאימה לתוכנה שלי תורת אמת בוורדאני כרגע מנסה אותה בשביל פרוייקט שלי, החיסרון המשמעותי הוא הגודל העצום של האינדקס, היא מיועדת בעיקר לשרתים ולא למשתמשי קצה ולכן אין אופטימיזציה של הגודל. אפשר לבדוק אינדקס שעשיתי לחלק מאוצריא כאן:
הצלחתי בינתיים ליצור אינדקס ל86% מהמאגר , זה שוקל 13 ג'יגה, דחסתי ל3.4 ג'יגה, ואפשר להוריד מכאן: https://drive.google.com/file/d/1NatVo7uHiCODzJ-t_NT9qJiVmgxMvBur/view?usp=sharingהוראות שימוש:
יש לחלץ את הקבצים באמצעות zip7
להפעיל את הקובץ בסיומת EXE, לא לסגור את החלון השחור.
לפתוח את הדפדפן בכתובת http://localhost:7700/
לחיפוש מדוייק יש להקיף את החיפוש במרכאות: "ביטוי לחיפוש מדוייק"
בלי מרכאות הוא מחפש חיפוש חופשי לפי רלוונטיות. מעניין אותי לשמוע תגובות על הרמה.@sivan22 כתב בספריית החיפוש meilisearch ב-בC#:
להפעיל את הקובץ בסיומת EXE, לא לסגור את החלון השחור.
גם בתוך התוכנה צריך שהחלון השחור ירוץ ברקע? לא נשמע פרקטי.....
-
@dovid כתב בספריית החיפוש meilisearch ב-בC#:
@pcinfogmach אני חושב שזה לא הגיוני לעשות את זה בקוד, זה אמור לפעול ברקע בקביעות, אם התוכנה שלך תרוץ פעמיים יהיה שגיאה של פורט תפוס. כמו"כ בתיעוד שמה מופיעה בדיקה לוודא שהמופע מאזין.
אולי לייצר service?
תכלס השגיאה הנ"ל עדיין קיימת
@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
תכלס השגיאה הנ"ל עדיין קיימת
מידע אינפורמטיבי מעולה בשביל משתמש נחמד בפורום אופיס. כמתכנת אתה אמור ללכת צעד צעד ולתת קצת יותר אינפורמציה. המופע רץ? הכתובת זמינה? זה דברים שכתבתי וגם הם בהדרכה, ואתה מדלג עליהם בלי לשים לב ישירות לשגיאה.
כמו כן הדיבור שלך בקשר לפרקטיקה עם יישום ברקע, זה מראה כמה שאתה קופץ, לא מדברים בעת פיתוח על אריזת הצלופן.
סליחה על המוסר, חזק ואמץ.
- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
תכלס השגיאה הנ"ל עדיין קיימת
מידע אינפורמטיבי מעולה בשביל משתמש נחמד בפורום אופיס. כמתכנת אתה אמור ללכת צעד צעד ולתת קצת יותר אינפורמציה. המופע רץ? הכתובת זמינה? זה דברים שכתבתי וגם הם בהדרכה, ואתה מדלג עליהם בלי לשים לב ישירות לשגיאה.
כמו כן הדיבור שלך בקשר לפרקטיקה עם יישום ברקע, זה מראה כמה שאתה קופץ, לא מדברים בעת פיתוח על אריזת הצלופן.
סליחה על המוסר, חזק ואמץ.
@dovid
אוקיי אולי קפצתי מדאי מהר מדאי אני קצת מבין יותר טוב עכשיו איך זה עובד בעצם meiliserach הינה "תוכנה" שאני יכול לגשת אליה דרך api ב-C#
אבל לא מדובר בספרייה של C# כלל -
@pcinfogmach נכון. זה דומה למסד נתונים, וזה הגיוני במידה והתוכנה שלך היא עם צד שרת.
- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
@pcinfogmach נכון. זה דומה למסד נתונים, וזה הגיוני במידה והתוכנה שלך היא עם צד שרת.
@dovid כתב בספריית החיפוש meilisearch ב-בC#:
וזה הגיוני במידה והתוכנה שלך היא עם צד שרת.
כלומר לא הגיוני בתוכנה שלי תורת אמת בוורד?
-
@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
מישהו מכיר את ספריית החיפוש meilisearch
האם מישהו יכול להמליץ לי עליה.
כמו:כ הייתי שמח לדעת האם היא מתאימה לתוכנה שלי תורת אמת בוורדאני כרגע מנסה אותה בשביל פרוייקט שלי, החיסרון המשמעותי הוא הגודל העצום של האינדקס, היא מיועדת בעיקר לשרתים ולא למשתמשי קצה ולכן אין אופטימיזציה של הגודל. אפשר לבדוק אינדקס שעשיתי לחלק מאוצריא כאן:
הצלחתי בינתיים ליצור אינדקס ל86% מהמאגר , זה שוקל 13 ג'יגה, דחסתי ל3.4 ג'יגה, ואפשר להוריד מכאן: https://drive.google.com/file/d/1NatVo7uHiCODzJ-t_NT9qJiVmgxMvBur/view?usp=sharingהוראות שימוש:
יש לחלץ את הקבצים באמצעות zip7
להפעיל את הקובץ בסיומת EXE, לא לסגור את החלון השחור.
לפתוח את הדפדפן בכתובת http://localhost:7700/
לחיפוש מדוייק יש להקיף את החיפוש במרכאות: "ביטוי לחיפוש מדוייק"
בלי מרכאות הוא מחפש חיפוש חופשי לפי רלוונטיות. מעניין אותי לשמוע תגובות על הרמה.@sivan22 מה מהירות החיפוש באינדקס זה?
אם זה מדאי כבד אפשר ליצור אינדקס עצמאי [לא צריך דווקא ספריה מוכנה...]הרעיון של אינדקס הוא די פשוט
A background index! That's a great idea to speed up search times. Creating an inverted index is a common technique to accelerate searching large amounts of text data. Here's a high-level overview of how you can create a background index:What is an inverted index?
An inverted index is a data structure that maps each unique term (word, phrase, keyword, etc.) to a list of documents that contain that term. This allows for efficient searching, as you can quickly retrieve the documents containing a given term.
How to create a background index?
To create a background index, you'll need to follow these steps:
- Preprocess the data: Read in your files, split them into individual documents, and tokenize them into individual words (tokens). You may also want to apply stemming, stopword removal, and other text processing techniques to reduce the dimensionality of the data.
- Build the index: Create an empty index data structure, such as a dictionary or a hash table, that will store the mapping between terms and documents. Iterate through the tokenized documents and update the index with each document. For each term, add the document ID to the list of documents that contain that term.
- Write the index to disk: Once the index is built, write it to disk as a file or a database. This will allow you to store the index independently of the original data and retrieve it quickly for searching.
- Build an index writer process: Create a separate process or thread that runs in the background, continuously updating the index as new documents are added, removed, or modified. This process will ensure that the index remains up-to-date.
How to query the index?
To query the index, you'll need to:
- Tokenize the search query: Break down the search query into individual words (tokens).
- Lookup terms in the index: Iterate through the tokens and look up each one in the index. This will give you a list of documents that contain each term.
- Intersect the results: Combine the lists of documents that contain each token to get the final result set.
- Retrieve and rank the results: Use the final result set to retrieve the actual documents and rank them according to their relevance.
Some considerations:
- Index size: The size of the index can grow rapidly as the number of documents increases. You may need to implement techniques like compression, sparse matrices, or distributed indexing to manage the index size.
- Index latency: Building and updating the index can take time, which may impact the freshness of the data. You may need to implement mechanisms to handle delayed updates or use a combination of real-time and batch updates.
- Search optimization: The querying process can also be optimized using techniques like caching, caching query results, or using specialized search algorithms.
- Index rebuilding: When rebuilding the index, you may need to consider strategies like incremental updating, iterative rebuilding, or even splitting the index into smaller pieces.
Bonus tip: Use existing libraries and tools
Many programming languages and libraries provide built-in support for creating and querying inverted indices. For example:
- Lucene.NET (C#): A popular search engine library for .NET that includes support for building and querying inverted indices.
- Elastic Search ( Java
:") A distributed search engine that provides high-performance search capabilities and automatically builds inverted indices.
A distributed search engine that provides high-performance search capabilities and automatically builds inverted indices. - Apache Solr (Java): A popular search server that allows you to create and query inverted indices.
Remember to consider the trade-offs between index size, query performance, and data freshness when designing your background index. Good luck!
למעשה יש כמה שיפורים קטנים ממש להוסיף ואז זה מושלם!
[למשל חלוקה של האינדקס לקבצים שונים לפי תווים וכן חלוקת כל מסמך למקטעים]. -
@אלף-שין הכי מגוחך שאתה מביא טקסט שממליץ להשתמש בספריה מוכנה.
- מנטור אישי בתכנות והמסתעף – להתקדם לשלב הבא!
- בכל נושא אפשר ליצור קשר dovid@tchumim.com
-
@אלף-שין,
כמישהו שחקר את הנושא למעלה משנה, אני רוצה לשתף אותך בתובנות שלי. התיאוריה של בניית אינדקסים באמת נשמעת פשוטה וקליטה, אבל היישום הרבה יותר מורכב. דוגמה קטנה לכך:כשאינדקס שוקל כמה גיגה-בייטים, כמה זמן לדעתך לוקח לקרוא את התוכן שלו בצורה הקלאסית של קריאת תוכן קובץ? הבעיה היא שאי אפשר לטעון אינדקס כזה לזיכרון ה-RAM כי הוא גדול מדי. לכן, נאלצים לעבור שורה שורה באינדקס בזמן החיפוש.
אני מקצר כי אין לי כוח להאריך, אבל תאמין לי, בניית אינדקס זה לא דבר של מה בכך. במיוחד כשמדובר באינדקסים גדולים.
-
חבל להמציא את הגלגל כשעשו לך כבר את העבודה, בפרט טיפול מיוחד בעברית כולל הבנת שורשים מתקדמת עם מילון וגם אלגוריתמים, שזו עבודת נמלים לבנות לבד.
meilisearch כולל באופן מובנה תמיכה ברלוונטיות, כלומר האינדקס כבר לוקח בחשבון מרחק וסדר של מילים, מרחק לוינשטיין לשגיאות כתיב, משקל שונה לכל שדה, והכל עם כפית של כסף out-of-the-box.
גם המהירות היא משמעותית, ועדיף להשתמש במנוע שכתוב בשפה מהירה כמו C++ או RUST.
לאנדקס לבד יכול להתאים למשימות קטנות יותר, אבל כשמדובר על כמה עשרות מיליונים של טקסטים, צריך בולדוזר מוכח. -
חבל להמציא את הגלגל כשעשו לך כבר את העבודה, בפרט טיפול מיוחד בעברית כולל הבנת שורשים מתקדמת עם מילון וגם אלגוריתמים, שזו עבודת נמלים לבנות לבד.
meilisearch כולל באופן מובנה תמיכה ברלוונטיות, כלומר האינדקס כבר לוקח בחשבון מרחק וסדר של מילים, מרחק לוינשטיין לשגיאות כתיב, משקל שונה לכל שדה, והכל עם כפית של כסף out-of-the-box.
גם המהירות היא משמעותית, ועדיף להשתמש במנוע שכתוב בשפה מהירה כמו C++ או RUST.
לאנדקס לבד יכול להתאים למשימות קטנות יותר, אבל כשמדובר על כמה עשרות מיליונים של טקסטים, צריך בולדוזר מוכח.@sivan22 כתב בספריית החיפוש meilisearch ב-בC#:
בפרט טיפול מיוחד בעברית כולל הבנת שורשים מתקדמת עם מילון וגם אלגוריתמים, שזו עבודת נמלים לבנות לבד.
הספקת לבדוק ביצועים ב-meilisearch בנוגע לזה? מאוד מסקרן אותי כמה הם מוצלחים בזה בפרט בטקסטים של חז"ל.
-
חבל להמציא את הגלגל כשעשו לך כבר את העבודה, בפרט טיפול מיוחד בעברית כולל הבנת שורשים מתקדמת עם מילון וגם אלגוריתמים, שזו עבודת נמלים לבנות לבד.
meilisearch כולל באופן מובנה תמיכה ברלוונטיות, כלומר האינדקס כבר לוקח בחשבון מרחק וסדר של מילים, מרחק לוינשטיין לשגיאות כתיב, משקל שונה לכל שדה, והכל עם כפית של כסף out-of-the-box.
גם המהירות היא משמעותית, ועדיף להשתמש במנוע שכתוב בשפה מהירה כמו C++ או RUST.
לאנדקס לבד יכול להתאים למשימות קטנות יותר, אבל כשמדובר על כמה עשרות מיליונים של טקסטים, צריך בולדוזר מוכח.@sivan22 כתב בספריית החיפוש meilisearch ב-בC#:
חבל להמציא את הגלגל כשעשו לך כבר את העבודה
@sivan22 כתב בספריית החיפוש meilisearch ב-בC#:
אני כרגע מנסה אותה בשביל פרוייקט שלי, החיסרון המשמעותי הוא הגודל העצום של האינדקס, היא מיועדת בעיקר לשרתים ולא למשתמשי קצה ולכן אין אופטימיזציה של הגודל
-
@אלף-שין,
כמישהו שחקר את הנושא למעלה משנה, אני רוצה לשתף אותך בתובנות שלי. התיאוריה של בניית אינדקסים באמת נשמעת פשוטה וקליטה, אבל היישום הרבה יותר מורכב. דוגמה קטנה לכך:כשאינדקס שוקל כמה גיגה-בייטים, כמה זמן לדעתך לוקח לקרוא את התוכן שלו בצורה הקלאסית של קריאת תוכן קובץ? הבעיה היא שאי אפשר לטעון אינדקס כזה לזיכרון ה-RAM כי הוא גדול מדי. לכן, נאלצים לעבור שורה שורה באינדקס בזמן החיפוש.
אני מקצר כי אין לי כוח להאריך, אבל תאמין לי, בניית אינדקס זה לא דבר של מה בכך. במיוחד כשמדובר באינדקסים גדולים.
@pcinfogmach כתב בספריית החיפוש meilisearch ב-בC#:
כשאינדקס שוקל כמה גיגה-בייטים, כמה זמן לדעתך לוקח לקרוא את התוכן שלו בצורה הקלאסית של קריאת תוכן קובץ?
זהותון מחפש תוך פחות משנייה על 3.5 GB שזה הרי ללא אינדקס........ [כי בכל אופן זה מילים חדשות אז אין מה לאנדקס....]
-
@sivan22 כתב בספריית החיפוש meilisearch ב-בC#:
חבל להמציא את הגלגל כשעשו לך כבר את העבודה
@sivan22 כתב בספריית החיפוש meilisearch ב-בC#:
אני כרגע מנסה אותה בשביל פרוייקט שלי, החיסרון המשמעותי הוא הגודל העצום של האינדקס, היא מיועדת בעיקר לשרתים ולא למשתמשי קצה ולכן אין אופטימיזציה של הגודל
-
@אלף-שין
כשזהו החיסרון היחיד זה מתגמד לעומת כל שאר התועליות@pcinfogmach
לפעמים זה נכון,
קח לדוגמה את המאגר של היברו בוקס,
מדובר על מאות גיגה! [קרוב ל650]
אם ניצור אינדקס באמצעות הספריה הזאת,
כמה זה ישקול?......
קרוב ל2 TB!