צאט AI | מודל שפה!
-
@nigun מכיוון שאני גם לא מומחה אז אין לי דרך לסתור אותך, אבל שים לב שהדוגמאות שהבאת הם דוגמאות שהסבירו לו את התשובה בדרך מסוימת וגרמו לו להבין אותה. זה לא קשור להסתברות למילה עוקבת.
זה גם לא מסביר איך הוא יכול להמציא הסבר גאוני [ורוב הפעמים גם לא נכון...] על כל תחום ועניין...@one1010 כתב בצאט AI | מודל שפה!:
@nigun מכיוון שאני גם לא מומחה אז אין לי דרך לסתור אותך, אבל שים לב שהדוגמאות שהבאת הם דוגמאות שהסבירו לו את התשובה בדרך מסוימת וגרמו לו להבין אותה. זה לא קשור להסתברות למילה עוקבת.
זה גם לא מסביר איך הוא יכול להמציא הסבר גאוני [ורוב הפעמים גם לא נכון...] על כל תחום ועניין...זה מה שצ'אט GPT כתב על ההסבר של @nigun :
נראה שההסבר שציטטת מנסה לתאר כיצד מודל שפה כמו GPT-3 עשוי לתפקד בביצוע ניחושים לוגיים או תחזיות על סמך דפוסים שהוא למד מנתוני אימון. עם זאת, יש כמה תפיסות שגויות ואי דיוקים בהסבר. להלן פירוט של הבעיות:
-
אימון חוזר ושינויים במבנה המודל: ההסבר מרמז שהמודל ממשיך לאמן את עצמו ולשנות את המבנה שלו אלפי פעמים עד שהוא מקבל תשובה ספציפית נכונה. במציאות, אימון מודל כרוך בתהליך אימון חד פעמי על מערך נתונים מסיבי, והמודל אינו משנה את המבנה שלו בכל פעם שהוא נתקל בנתונים חדשים.
-
הסבר מוגבל של כוונון עדין: ההסבר אינו מתייחס לתהליך הכוונון העדין שלאחר האימון הראשוני. כוונון עדין הוא ספציפי ליישומים בודדים ומחדד עוד יותר את התנהגות המודל בהתבסס על נתונים ויעדים צרים יותר.
-
הסבר לא מדויק של למידה: ההסבר מצביע על כך שה"ניחושים" של המודל הם תוצאה של ניסוי וטעייה במהלך כל מפגש עם טקסט חדש. עם זאת, GPT-3 לומד דפוסים ויחסים מהטקסט עליו הוכשר, והוא לא משנה באופן אקטיבי את המבנה שלו כדי לנחש נכון.
-
פישוט יתר של זיהוי דפוסים: בעוד ש-GPT-3 אכן מזהה דפוסים בשפה, הוא לא עובד בגישה של כוח גס של ניסיון שינויים שונים במבנה הפנימי שלו. הוא מייצר תגובות על סמך ההסתברויות של רצפי מילים שלמד במהלך האימון.
-
הנחה של "משהו" שנכנס למודל: ההסבר מתייחס ל"משהו" מסתורי שנכנס למודל כאשר נתקלים בטקסט חדש. במציאות, המודל אינו מאחסן מופעים נפרדים של טקסט במבנה שלו; הוא מייצר תגובות על סמך הדפוסים שלמדה ממערך נתונים מגוון.
-
אי הבנה של הבנת המודל: ההסבר מצביע על כך שלמודל יש איזושהי "הבנה" של מושגים כמו "כחול שמיים" או "צבעים". במציאות, המודל אינו מבין מושגים; הוא מנבא על סמך דפוסים.
-
תפיסה מוטעית לגבי שינויים ברשת עצבית: נראה שההסבר מצביע על כך שמבנה הרשת העצבית של המודל משתנה בתגובה לשאלות בודדות, וזה לא האופן שבו מודלים מאומנים מראש כמו GPT-3 עובדים. המבנה נשאר קבוע לאחר אימון ראשוני.
למעשה, למרות שההסבר עשוי להיות ניסיון להבין כיצד פועלים מודלים של GPT-3 או שפה דומות, הוא אינו משקף במדויק את התהליכים בפועל המעורבים בפעולות המודלים הללו. GPT-3 משתמש בתבניות והסתברויות נלמדות כדי ליצור טקסט קוהרנטי על סמך הקלט שהוא מקבל, אבל הוא לא משנה את המבנה שלו באופן אקטיבי או מעורב בתהליך הניסוי והטעייה המתואר.
אלף בוט - תמלול מדויק לתוכן תורני
https://alef-bot.top -
-
@one1010 כתב בצאט AI | מודל שפה!:
@nigun מכיוון שאני גם לא מומחה אז אין לי דרך לסתור אותך, אבל שים לב שהדוגמאות שהבאת הם דוגמאות שהסבירו לו את התשובה בדרך מסוימת וגרמו לו להבין אותה. זה לא קשור להסתברות למילה עוקבת.
זה גם לא מסביר איך הוא יכול להמציא הסבר גאוני [ורוב הפעמים גם לא נכון...] על כל תחום ועניין...זה מה שצ'אט GPT כתב על ההסבר של @nigun :
נראה שההסבר שציטטת מנסה לתאר כיצד מודל שפה כמו GPT-3 עשוי לתפקד בביצוע ניחושים לוגיים או תחזיות על סמך דפוסים שהוא למד מנתוני אימון. עם זאת, יש כמה תפיסות שגויות ואי דיוקים בהסבר. להלן פירוט של הבעיות:
-
אימון חוזר ושינויים במבנה המודל: ההסבר מרמז שהמודל ממשיך לאמן את עצמו ולשנות את המבנה שלו אלפי פעמים עד שהוא מקבל תשובה ספציפית נכונה. במציאות, אימון מודל כרוך בתהליך אימון חד פעמי על מערך נתונים מסיבי, והמודל אינו משנה את המבנה שלו בכל פעם שהוא נתקל בנתונים חדשים.
-
הסבר מוגבל של כוונון עדין: ההסבר אינו מתייחס לתהליך הכוונון העדין שלאחר האימון הראשוני. כוונון עדין הוא ספציפי ליישומים בודדים ומחדד עוד יותר את התנהגות המודל בהתבסס על נתונים ויעדים צרים יותר.
-
הסבר לא מדויק של למידה: ההסבר מצביע על כך שה"ניחושים" של המודל הם תוצאה של ניסוי וטעייה במהלך כל מפגש עם טקסט חדש. עם זאת, GPT-3 לומד דפוסים ויחסים מהטקסט עליו הוכשר, והוא לא משנה באופן אקטיבי את המבנה שלו כדי לנחש נכון.
-
פישוט יתר של זיהוי דפוסים: בעוד ש-GPT-3 אכן מזהה דפוסים בשפה, הוא לא עובד בגישה של כוח גס של ניסיון שינויים שונים במבנה הפנימי שלו. הוא מייצר תגובות על סמך ההסתברויות של רצפי מילים שלמד במהלך האימון.
-
הנחה של "משהו" שנכנס למודל: ההסבר מתייחס ל"משהו" מסתורי שנכנס למודל כאשר נתקלים בטקסט חדש. במציאות, המודל אינו מאחסן מופעים נפרדים של טקסט במבנה שלו; הוא מייצר תגובות על סמך הדפוסים שלמדה ממערך נתונים מגוון.
-
אי הבנה של הבנת המודל: ההסבר מצביע על כך שלמודל יש איזושהי "הבנה" של מושגים כמו "כחול שמיים" או "צבעים". במציאות, המודל אינו מבין מושגים; הוא מנבא על סמך דפוסים.
-
תפיסה מוטעית לגבי שינויים ברשת עצבית: נראה שההסבר מצביע על כך שמבנה הרשת העצבית של המודל משתנה בתגובה לשאלות בודדות, וזה לא האופן שבו מודלים מאומנים מראש כמו GPT-3 עובדים. המבנה נשאר קבוע לאחר אימון ראשוני.
למעשה, למרות שההסבר עשוי להיות ניסיון להבין כיצד פועלים מודלים של GPT-3 או שפה דומות, הוא אינו משקף במדויק את התהליכים בפועל המעורבים בפעולות המודלים הללו. GPT-3 משתמש בתבניות והסתברויות נלמדות כדי ליצור טקסט קוהרנטי על סמך הקלט שהוא מקבל, אבל הוא לא משנה את המבנה שלו באופן אקטיבי או מעורב בתהליך הניסוי והטעייה המתואר.
-
-
@aaron כתב בצאט AI | מודל שפה!:
הסתברות של עשרות מיליארדי פרמטרים שונים, בעיקר, כן.
שזה אומר במילים אחרות הבנה של המילה...
ברמה כזו או אחרת@one1010 כתב בצאט AI | מודל שפה!:
@aaron כתב בצאט AI | מודל שפה!:
הסתברות של עשרות מיליארדי פרמטרים שונים, בעיקר, כן.
שזה אומר במילים אחרות הבנה של המילה...
ברמה כזו או אחרתאוקי כאן מתחיל השאלה הפילוסופית מה זה "הבנה"
לבנתיים למודלי שפה אין "הבנה" כמו שאנחנו רגילים לחושב עליו, אלא רק חישובים סטטיסטיים מאוד מורכבים.
ולכן אי אפשר לצפות ש"יבינו" כמו בני אדם. -
@one1010 כתב בצאט AI | מודל שפה!:
@nigun מכיוון שאני גם לא מומחה אז אין לי דרך לסתור אותך, אבל שים לב שהדוגמאות שהבאת הם דוגמאות שהסבירו לו את התשובה בדרך מסוימת וגרמו לו להבין אותה. זה לא קשור להסתברות למילה עוקבת.
זה גם לא מסביר איך הוא יכול להמציא הסבר גאוני [ורוב הפעמים גם לא נכון...] על כל תחום ועניין...זה מה שצ'אט GPT כתב על ההסבר של @nigun :
נראה שההסבר שציטטת מנסה לתאר כיצד מודל שפה כמו GPT-3 עשוי לתפקד בביצוע ניחושים לוגיים או תחזיות על סמך דפוסים שהוא למד מנתוני אימון. עם זאת, יש כמה תפיסות שגויות ואי דיוקים בהסבר. להלן פירוט של הבעיות:
-
אימון חוזר ושינויים במבנה המודל: ההסבר מרמז שהמודל ממשיך לאמן את עצמו ולשנות את המבנה שלו אלפי פעמים עד שהוא מקבל תשובה ספציפית נכונה. במציאות, אימון מודל כרוך בתהליך אימון חד פעמי על מערך נתונים מסיבי, והמודל אינו משנה את המבנה שלו בכל פעם שהוא נתקל בנתונים חדשים.
-
הסבר מוגבל של כוונון עדין: ההסבר אינו מתייחס לתהליך הכוונון העדין שלאחר האימון הראשוני. כוונון עדין הוא ספציפי ליישומים בודדים ומחדד עוד יותר את התנהגות המודל בהתבסס על נתונים ויעדים צרים יותר.
-
הסבר לא מדויק של למידה: ההסבר מצביע על כך שה"ניחושים" של המודל הם תוצאה של ניסוי וטעייה במהלך כל מפגש עם טקסט חדש. עם זאת, GPT-3 לומד דפוסים ויחסים מהטקסט עליו הוכשר, והוא לא משנה באופן אקטיבי את המבנה שלו כדי לנחש נכון.
-
פישוט יתר של זיהוי דפוסים: בעוד ש-GPT-3 אכן מזהה דפוסים בשפה, הוא לא עובד בגישה של כוח גס של ניסיון שינויים שונים במבנה הפנימי שלו. הוא מייצר תגובות על סמך ההסתברויות של רצפי מילים שלמד במהלך האימון.
-
הנחה של "משהו" שנכנס למודל: ההסבר מתייחס ל"משהו" מסתורי שנכנס למודל כאשר נתקלים בטקסט חדש. במציאות, המודל אינו מאחסן מופעים נפרדים של טקסט במבנה שלו; הוא מייצר תגובות על סמך הדפוסים שלמדה ממערך נתונים מגוון.
-
אי הבנה של הבנת המודל: ההסבר מצביע על כך שלמודל יש איזושהי "הבנה" של מושגים כמו "כחול שמיים" או "צבעים". במציאות, המודל אינו מבין מושגים; הוא מנבא על סמך דפוסים.
-
תפיסה מוטעית לגבי שינויים ברשת עצבית: נראה שההסבר מצביע על כך שמבנה הרשת העצבית של המודל משתנה בתגובה לשאלות בודדות, וזה לא האופן שבו מודלים מאומנים מראש כמו GPT-3 עובדים. המבנה נשאר קבוע לאחר אימון ראשוני.
למעשה, למרות שההסבר עשוי להיות ניסיון להבין כיצד פועלים מודלים של GPT-3 או שפה דומות, הוא אינו משקף במדויק את התהליכים בפועל המעורבים בפעולות המודלים הללו. GPT-3 משתמש בתבניות והסתברויות נלמדות כדי ליצור טקסט קוהרנטי על סמך הקלט שהוא מקבל, אבל הוא לא משנה את המבנה שלו באופן אקטיבי או מעורב בתהליך הניסוי והטעייה המתואר.
@NH-LOCAL כתב בצאט AI | מודל שפה!:
הסבר לא מדויק של למידה: ההסבר מצביע על כך שה"ניחושים" של המודל הם תוצאה של ניסוי וטעייה במהלך כל מפגש עם טקסט חדש. עם זאת, GPT-3 לומד דפוסים ויחסים מהטקסט עליו הוכשר, והוא לא משנה באופן אקטיבי את המבנה שלו כדי לנחש נכון.
אני משער שהתהליך הוא הרבה יותר חכם ויעיל ממה שכתבתי, בעיקר נסיתי לפשט.
אבל גם במאמר הזה נראה שהוא מתאר משהו דומה (יכול להיות שהוא רק ניסה לפשט)But, OK, given all this data, how does one train a neural net from it? The basic process is very much as we discussed it in the simple examples above. You present a batch of examples, and then you adjust the weights in the network to minimize the error (“loss”) that the network makes on those examples. The main thing that’s expensive about “back propagating” from the error is that each time you do this, every weight in the network will typically change at least a tiny bit, and there are just a lot of weights to deal with. (The actual “back computation” is typically only a small constant factor harder than the forward one.)
-
-
הנה עוד קטע מהמאמר הנ"ל
מה באמת מאפשר ל-ChatGPT לעבוד?
השפה האנושית - ותהליכי החשיבה הכרוכים ביצירתה - תמיד נראו כמעין שיא של מורכבות. ואכן זה נראה קצת מדהים שמוחות אנושיים - עם הרשת שלהם של "רק" 100 מיליארד נוירונים בערך (ואולי 100 טריליון קשרים) יכולים להיות אחראים לכך. אולי, אפשר היה לדמיין, יש משהו יותר במוח מאשר רשתות הנוירונים שלהם - כמו איזו שכבה חדשה של פיזיקה שלא התגלתה. אבל עכשיו עם ChatGPT יש לנו פיסת מידע חדשה וחשובה: אנחנו יודעים שרשת עצבית טהורה ומלאכותית עם קשרים רבים כמו למוח שיש לנו נוירונים מסוגלת לעשות עבודה טובה באופן מפתיע לייצר שפה אנושית.וכן, זו עדיין מערכת גדולה ומסובכת - עם משקלים עצביים רבים בערך כמו שיש מילות טקסט הזמינות כיום בעולם. אבל ברמה מסוימת עדיין נראה שקשה להאמין שכל העושר של השפה והדברים שהיא יכולה לדבר עליהם יכולים להיות מובלעים במערכת כה סופית. חלק ממה שקורה הוא ללא ספק השתקפות של התופעה בכל מקום (שהתבררה לראשונה בדוגמה של כלל 30) שתהליכי חישוב יכולים למעשה להגביר מאוד את המורכבות הנראית לעין של מערכות גם כאשר הכללים הבסיסיים שלהן פשוטים. אבל למעשה, כפי שדיברנו לעיל, רשתות עצביות מהסוג המשמש ב-ChatGPT נוטות להיבנות באופן ספציפי כדי להגביל את ההשפעה של תופעה זו - וחוסר ההפחתה החישובית הקשורה אליה - מתוך אינטרס להפוך את האימון שלהן לנגיש יותר.
אז איך זה, אם כן, שמשהו כמו ChatGPT יכול להגיע עד כמה שהוא מגיע עם השפה? התשובה הבסיסית, אני חושב, היא שהשפה היא ברמה בסיסית איכשהו פשוטה יותר ממה שהיא נראית. וזה אומר ש-ChatGPT - אפילו עם מבנה הרשת העצבית הפשוט בסופו של דבר - מסוגל "ללכוד את המהות" של השפה האנושית והחשיבה שמאחוריה. ויותר מכך, בהכשרתה, ChatGPT איכשהו "גילתה באופן מרומז" את כל הקביעות בשפה (ובחשיבה) שמאפשרות זאת.
הצלחתו של ChatGPT היא, לדעתי, נותנת לנו עדות לפיסת מדע בסיסית וחשובה: היא מעידה על כך שאנו יכולים לצפות שיהיו "חוקי השפה" חדשים עיקריים - ולמעשה "חוקי המחשבה" - כדי לגלות שם. . ב-ChatGPT - שנבנה כפי שהוא כרשת עצבית - החוקים האלה הם לכל היותר מרומזים. אבל אם נוכל איכשהו להבהיר את החוקים, יש פוטנציאל לעשות את הדברים ש-ChatGPT עושה בדרכים הרבה יותר ישירות, יעילות ושקופות.
אבל, בסדר, אז איך החוקים האלה עשויים להיות? בסופו של דבר הם חייבים לתת לנו איזשהו מרשם לאופן שבו השפה - והדברים שאנו אומרים איתה - מורכבים יחד. מאוחר יותר נדון כיצד "הסתכלות בתוך ChatGPT" עשויה לתת לנו כמה רמזים על כך, וכיצד מה שאנו יודעים מבניית שפת חישוב מעיד על דרך קדימה. אבל תחילה בואו נדון בשתי דוגמאות ידועות ארוכות של מה שמסתכם ב"חוקי השפה" - וכיצד הם קשורים לפעולה של ChatGPT.
הראשון הוא תחביר השפה. שפה היא לא רק ערבוביה אקראית של מילים. במקום זאת, ישנם כללים דקדוקיים מוגדרים (די) לאופן שבו ניתן לחבר מילים מסוגים שונים: באנגלית, למשל, שמות עצם יכולים להיות מקדימים שמות תואר ואחריהם פעלים, אבל בדרך כלל שני שמות עצם לא יכולים להיות ממש ליד כל אחד מהם. אַחֵר. מבנה דקדוקי כזה יכול (לפחות בקירוב) להיתפס על ידי מערכת כללים המגדירים כיצד ניתן להרכיב איזו כמות ל"נתח עצים" :

ל-ChatGPT אין "ידע" מפורש על כללים כאלה. אבל איכשהו באימון שלו הוא "מגלה" אותם במרומז - ואז נראה שהוא טוב במעקב אחריהם. אז איך זה עובד? ברמת "תמונה גדולה" זה לא ברור. אבל כדי לקבל קצת תובנות זה אולי מאלף להסתכל על דוגמה הרבה יותר פשוטה.
שקול "שפה" שנוצרה מרצפים של סוגריים דהיינו התווים () עם דקדוק המציין שסוגריים תמיד צריכים להיות מאוזנים, כפי שמיוצג על ידי עץ ניתוח כמו:

האם נוכל לאמן רשת עצבית לייצר רצפי סוגריים "נכונים מבחינה דקדוקית"? ישנן דרכים שונות לטפל ברצפים ברשתות עצביות, אבל בואו נשתמש ברשתות שנאים, כפי שעושה ChatGPT. ובהינתן רשת transformer פשוטה, נוכל להתחיל להזין אותה ברצפי סוגריים נכונים מבחינה דקדוקית כדוגמאות אימון. עדינות (שלמעשה מופיעה גם בדור השפה האנושית של ChatGPT) היא שבנוסף ל"אסימוני התוכן" שלנו (כאן "(" ו")") עלינו לכלול אסימון "סוף", שנוצר כדי לציין שה- הפלט לא אמור להמשיך יותר (כלומר עבור ChatGPT, זה הגיע ל"סוף הסיפור").
אם נקים רשת transformer עם רק בלוק קשב אחד עם 8 ראשים ווקטורי תכונה באורך 128 (ChatGPT משתמש גם בוקטורי תכונה באורך 128, אבל יש לו 96 בלוקי קשב, כל אחד עם 96 ראשים), אז לא נראה שאפשר להביא אותו ללמוד הרבה על שפת סוגריים. אבל עם 2 בלוקים של קשב, נראה שתהליך הלמידה מתכנס - לפחות לאחר שניתנו 10 מיליון דוגמאות לערך (וכפי שמקובל ברשתות transformer, הצגת דוגמאות נוספות נראה רק פוגעת בביצועים שלה).
אז עם הרשת הזו, אנחנו יכולים לעשות את האנלוגי של מה ש-ChatGPT עושה, ולבקש הסתברויות מה צריך להיות האסימון הבא - ברצף של סוגריים:

ובמקרה הראשון, הרשת "די בטוחה" שהרצף לא יכול להסתיים כאן - וזה טוב, כי אם כן, הסוגריים היו נותרים לא מאוזנים. אולם במקרה השני, הוא "מזהה נכון" שהרצף יכול להסתיים כאן, אם כי הוא גם "מציין" שאפשר "להתחיל מחדש", לשים ")", ככל הנראה עם "(" שאחריו. . אבל, אופס, אפילו עם כ-400,000 המשקולות שאומנו בעמל רב, זה אומר שיש סבירות של 15% לקבל "(" בתור האסימון הבא - וזה לא נכון, כי זה בהכרח יוביל לסוגריים לא מאוזנים.
זה מה שנקבל אם נבקש מהרשת את ההשלמות בעלות ההסתברות הגבוהה ביותר עבור רצפים ארוכים יותר ויותר של ) :

וכן, עד אורך מסוים הרשת מסתדרת מצוין. אבל אז זה מתחיל להיכשל. זה סוג די אופייני לראות במצב "מדויק" כזה עם רשת עצבית (או עם למידת מכונה באופן כללי). מקרים שאדם "יכול לפתור במבט חטוף" גם הרשת העצבית יכולה לפתור. אבל מקרים הדורשים לעשות משהו "אלגוריתמי יותר" (למשל ספירה מפורשת של סוגריים כדי לראות אם הם סגורים) הרשת העצבית נוטה איכשהו להיות "רדודה מדי מבחינה חישובית" מכדי לעשות זאת בצורה מהימנה. (אגב, אפילו ChatGPT הנוכחי המלא מתקשה להתאים נכון סוגריים ברצפים ארוכים.)
אז מה זה אומר לגבי דברים כמו ChatGPT והתחביר של שפה כמו אנגלית? שפת הסוגריים היא "מחמירה" - והרבה יותר "סיפור אלגוריתמי". אבל באנגלית זה הרבה יותר ריאלי להיות מסוגל "לנחש" מה יתאים מבחינה דקדוקית על סמך בחירות מקומיות של מילים ורמזים אחרים. וכן, הרשת העצבית הרבה יותר טובה בזה - למרות שאולי היא עשויה להחמיץ מקרה "נכון פורמלית" שגם בני אדם עלולים לפספס. אבל הנקודה העיקרית היא שהעובדה שיש מבנה תחבירי כולל לשפה - עם כל הסדירות שמשתמעת מכך - מגבילה במובן מסוים "כמה" לרשת העצבית צריכה ללמוד.
תחביר מספק סוג אחד של אילוץ על השפה. אבל ברור שיש עוד. משפט כמו "אלקטרונים סקרנים אוכלים תיאוריות כחולות לדגים" הוא נכון מבחינה דקדוקית אבל הוא לא משהו שבדרך כלל היה מצפים לומר, ולא ייחשב להצלחה אם ChatGPT ייצר אותו - כי, ובכן, עם המשמעויות הרגילות עבור מילים בו, זה בעצם חסר משמעות.
אבל האם יש דרך כללית לדעת אם יש משמעות למשפט? אין תיאוריה כללית מסורתית לכך. אבל זה משהו שאפשר לחשוב על ChatGPT כמי ש"פיתח עבורו תיאוריה" באופן מרומז לאחר שעבר הכשרה עם מיליארדי משפטים (כנראה בעלי משמעות) מהאינטרנט וכו'.
איך יכולה להיות התיאוריה הזו? ובכן, יש פינה אחת קטנטנה שבעצם ידועה כבר אלפיים שנה, וזה היגיון. ובוודאי בצורה הסילוגיסטית שבה גילה זאת אריסטו, ההיגיון הוא בעצם דרך לומר שמשפטים העוקבים אחר דפוסים מסוימים הם סבירים, בעוד שאחרים לא. כך, למשל, סביר לומר "כל ה-X הם Y. זה לא Y, אז זה לא X" (כמו ב"כל הדגים כחולים. זה לא כחול, אז זה לא דג"). וכמו שאפשר לדמיין בצורה קצת גחמנית שאריסטו גילה את ההיגיון הסילוגיסטי על ידי מעבר ("סגנון למידה מכונה") על המון דוגמאות של רטוריקה, כך גם אפשר לדמיין שבאימונים של ChatGPT הוא היה מסוגל "לגלות היגיון סילוגיסטי" על ידי הסתכלות על הרבה טקסט באינטרנט וכו'. (וכן, בעוד שניתן לצפות מ-ChatGPT לייצר טקסט שמכיל "מסקנות נכונות" על סמך דברים כמו לוגיקה סילוגיסטית,
אבל מעבר לדוגמא הצרה של ההיגיון, מה ניתן לומר על איך לבנות באופן שיטתי (או לזהות) אפילו טקסט בעל משמעות מתקבלת על הדעת? כן, יש דברים כמו Mad Libs שמשתמשים ב"תבניות ביטוי" מאוד ספציפיות. אבל איכשהו ל-ChatGPT יש באופן מרומז דרך הרבה יותר כללית לעשות את זה. ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
מייל: nigun@duck.com
-
הנה עוד קטע מהמאמר הנ"ל
מה באמת מאפשר ל-ChatGPT לעבוד?
השפה האנושית - ותהליכי החשיבה הכרוכים ביצירתה - תמיד נראו כמעין שיא של מורכבות. ואכן זה נראה קצת מדהים שמוחות אנושיים - עם הרשת שלהם של "רק" 100 מיליארד נוירונים בערך (ואולי 100 טריליון קשרים) יכולים להיות אחראים לכך. אולי, אפשר היה לדמיין, יש משהו יותר במוח מאשר רשתות הנוירונים שלהם - כמו איזו שכבה חדשה של פיזיקה שלא התגלתה. אבל עכשיו עם ChatGPT יש לנו פיסת מידע חדשה וחשובה: אנחנו יודעים שרשת עצבית טהורה ומלאכותית עם קשרים רבים כמו למוח שיש לנו נוירונים מסוגלת לעשות עבודה טובה באופן מפתיע לייצר שפה אנושית.וכן, זו עדיין מערכת גדולה ומסובכת - עם משקלים עצביים רבים בערך כמו שיש מילות טקסט הזמינות כיום בעולם. אבל ברמה מסוימת עדיין נראה שקשה להאמין שכל העושר של השפה והדברים שהיא יכולה לדבר עליהם יכולים להיות מובלעים במערכת כה סופית. חלק ממה שקורה הוא ללא ספק השתקפות של התופעה בכל מקום (שהתבררה לראשונה בדוגמה של כלל 30) שתהליכי חישוב יכולים למעשה להגביר מאוד את המורכבות הנראית לעין של מערכות גם כאשר הכללים הבסיסיים שלהן פשוטים. אבל למעשה, כפי שדיברנו לעיל, רשתות עצביות מהסוג המשמש ב-ChatGPT נוטות להיבנות באופן ספציפי כדי להגביל את ההשפעה של תופעה זו - וחוסר ההפחתה החישובית הקשורה אליה - מתוך אינטרס להפוך את האימון שלהן לנגיש יותר.
אז איך זה, אם כן, שמשהו כמו ChatGPT יכול להגיע עד כמה שהוא מגיע עם השפה? התשובה הבסיסית, אני חושב, היא שהשפה היא ברמה בסיסית איכשהו פשוטה יותר ממה שהיא נראית. וזה אומר ש-ChatGPT - אפילו עם מבנה הרשת העצבית הפשוט בסופו של דבר - מסוגל "ללכוד את המהות" של השפה האנושית והחשיבה שמאחוריה. ויותר מכך, בהכשרתה, ChatGPT איכשהו "גילתה באופן מרומז" את כל הקביעות בשפה (ובחשיבה) שמאפשרות זאת.
הצלחתו של ChatGPT היא, לדעתי, נותנת לנו עדות לפיסת מדע בסיסית וחשובה: היא מעידה על כך שאנו יכולים לצפות שיהיו "חוקי השפה" חדשים עיקריים - ולמעשה "חוקי המחשבה" - כדי לגלות שם. . ב-ChatGPT - שנבנה כפי שהוא כרשת עצבית - החוקים האלה הם לכל היותר מרומזים. אבל אם נוכל איכשהו להבהיר את החוקים, יש פוטנציאל לעשות את הדברים ש-ChatGPT עושה בדרכים הרבה יותר ישירות, יעילות ושקופות.
אבל, בסדר, אז איך החוקים האלה עשויים להיות? בסופו של דבר הם חייבים לתת לנו איזשהו מרשם לאופן שבו השפה - והדברים שאנו אומרים איתה - מורכבים יחד. מאוחר יותר נדון כיצד "הסתכלות בתוך ChatGPT" עשויה לתת לנו כמה רמזים על כך, וכיצד מה שאנו יודעים מבניית שפת חישוב מעיד על דרך קדימה. אבל תחילה בואו נדון בשתי דוגמאות ידועות ארוכות של מה שמסתכם ב"חוקי השפה" - וכיצד הם קשורים לפעולה של ChatGPT.
הראשון הוא תחביר השפה. שפה היא לא רק ערבוביה אקראית של מילים. במקום זאת, ישנם כללים דקדוקיים מוגדרים (די) לאופן שבו ניתן לחבר מילים מסוגים שונים: באנגלית, למשל, שמות עצם יכולים להיות מקדימים שמות תואר ואחריהם פעלים, אבל בדרך כלל שני שמות עצם לא יכולים להיות ממש ליד כל אחד מהם. אַחֵר. מבנה דקדוקי כזה יכול (לפחות בקירוב) להיתפס על ידי מערכת כללים המגדירים כיצד ניתן להרכיב איזו כמות ל"נתח עצים" :
ל-ChatGPT אין "ידע" מפורש על כללים כאלה. אבל איכשהו באימון שלו הוא "מגלה" אותם במרומז - ואז נראה שהוא טוב במעקב אחריהם. אז איך זה עובד? ברמת "תמונה גדולה" זה לא ברור. אבל כדי לקבל קצת תובנות זה אולי מאלף להסתכל על דוגמה הרבה יותר פשוטה.
שקול "שפה" שנוצרה מרצפים של סוגריים דהיינו התווים () עם דקדוק המציין שסוגריים תמיד צריכים להיות מאוזנים, כפי שמיוצג על ידי עץ ניתוח כמו:
האם נוכל לאמן רשת עצבית לייצר רצפי סוגריים "נכונים מבחינה דקדוקית"? ישנן דרכים שונות לטפל ברצפים ברשתות עצביות, אבל בואו נשתמש ברשתות שנאים, כפי שעושה ChatGPT. ובהינתן רשת transformer פשוטה, נוכל להתחיל להזין אותה ברצפי סוגריים נכונים מבחינה דקדוקית כדוגמאות אימון. עדינות (שלמעשה מופיעה גם בדור השפה האנושית של ChatGPT) היא שבנוסף ל"אסימוני התוכן" שלנו (כאן "(" ו")") עלינו לכלול אסימון "סוף", שנוצר כדי לציין שה- הפלט לא אמור להמשיך יותר (כלומר עבור ChatGPT, זה הגיע ל"סוף הסיפור").
אם נקים רשת transformer עם רק בלוק קשב אחד עם 8 ראשים ווקטורי תכונה באורך 128 (ChatGPT משתמש גם בוקטורי תכונה באורך 128, אבל יש לו 96 בלוקי קשב, כל אחד עם 96 ראשים), אז לא נראה שאפשר להביא אותו ללמוד הרבה על שפת סוגריים. אבל עם 2 בלוקים של קשב, נראה שתהליך הלמידה מתכנס - לפחות לאחר שניתנו 10 מיליון דוגמאות לערך (וכפי שמקובל ברשתות transformer, הצגת דוגמאות נוספות נראה רק פוגעת בביצועים שלה).
אז עם הרשת הזו, אנחנו יכולים לעשות את האנלוגי של מה ש-ChatGPT עושה, ולבקש הסתברויות מה צריך להיות האסימון הבא - ברצף של סוגריים:
ובמקרה הראשון, הרשת "די בטוחה" שהרצף לא יכול להסתיים כאן - וזה טוב, כי אם כן, הסוגריים היו נותרים לא מאוזנים. אולם במקרה השני, הוא "מזהה נכון" שהרצף יכול להסתיים כאן, אם כי הוא גם "מציין" שאפשר "להתחיל מחדש", לשים ")", ככל הנראה עם "(" שאחריו. . אבל, אופס, אפילו עם כ-400,000 המשקולות שאומנו בעמל רב, זה אומר שיש סבירות של 15% לקבל "(" בתור האסימון הבא - וזה לא נכון, כי זה בהכרח יוביל לסוגריים לא מאוזנים.
זה מה שנקבל אם נבקש מהרשת את ההשלמות בעלות ההסתברות הגבוהה ביותר עבור רצפים ארוכים יותר ויותר של ) :
וכן, עד אורך מסוים הרשת מסתדרת מצוין. אבל אז זה מתחיל להיכשל. זה סוג די אופייני לראות במצב "מדויק" כזה עם רשת עצבית (או עם למידת מכונה באופן כללי). מקרים שאדם "יכול לפתור במבט חטוף" גם הרשת העצבית יכולה לפתור. אבל מקרים הדורשים לעשות משהו "אלגוריתמי יותר" (למשל ספירה מפורשת של סוגריים כדי לראות אם הם סגורים) הרשת העצבית נוטה איכשהו להיות "רדודה מדי מבחינה חישובית" מכדי לעשות זאת בצורה מהימנה. (אגב, אפילו ChatGPT הנוכחי המלא מתקשה להתאים נכון סוגריים ברצפים ארוכים.)
אז מה זה אומר לגבי דברים כמו ChatGPT והתחביר של שפה כמו אנגלית? שפת הסוגריים היא "מחמירה" - והרבה יותר "סיפור אלגוריתמי". אבל באנגלית זה הרבה יותר ריאלי להיות מסוגל "לנחש" מה יתאים מבחינה דקדוקית על סמך בחירות מקומיות של מילים ורמזים אחרים. וכן, הרשת העצבית הרבה יותר טובה בזה - למרות שאולי היא עשויה להחמיץ מקרה "נכון פורמלית" שגם בני אדם עלולים לפספס. אבל הנקודה העיקרית היא שהעובדה שיש מבנה תחבירי כולל לשפה - עם כל הסדירות שמשתמעת מכך - מגבילה במובן מסוים "כמה" לרשת העצבית צריכה ללמוד.
תחביר מספק סוג אחד של אילוץ על השפה. אבל ברור שיש עוד. משפט כמו "אלקטרונים סקרנים אוכלים תיאוריות כחולות לדגים" הוא נכון מבחינה דקדוקית אבל הוא לא משהו שבדרך כלל היה מצפים לומר, ולא ייחשב להצלחה אם ChatGPT ייצר אותו - כי, ובכן, עם המשמעויות הרגילות עבור מילים בו, זה בעצם חסר משמעות.
אבל האם יש דרך כללית לדעת אם יש משמעות למשפט? אין תיאוריה כללית מסורתית לכך. אבל זה משהו שאפשר לחשוב על ChatGPT כמי ש"פיתח עבורו תיאוריה" באופן מרומז לאחר שעבר הכשרה עם מיליארדי משפטים (כנראה בעלי משמעות) מהאינטרנט וכו'.
איך יכולה להיות התיאוריה הזו? ובכן, יש פינה אחת קטנטנה שבעצם ידועה כבר אלפיים שנה, וזה היגיון. ובוודאי בצורה הסילוגיסטית שבה גילה זאת אריסטו, ההיגיון הוא בעצם דרך לומר שמשפטים העוקבים אחר דפוסים מסוימים הם סבירים, בעוד שאחרים לא. כך, למשל, סביר לומר "כל ה-X הם Y. זה לא Y, אז זה לא X" (כמו ב"כל הדגים כחולים. זה לא כחול, אז זה לא דג"). וכמו שאפשר לדמיין בצורה קצת גחמנית שאריסטו גילה את ההיגיון הסילוגיסטי על ידי מעבר ("סגנון למידה מכונה") על המון דוגמאות של רטוריקה, כך גם אפשר לדמיין שבאימונים של ChatGPT הוא היה מסוגל "לגלות היגיון סילוגיסטי" על ידי הסתכלות על הרבה טקסט באינטרנט וכו'. (וכן, בעוד שניתן לצפות מ-ChatGPT לייצר טקסט שמכיל "מסקנות נכונות" על סמך דברים כמו לוגיקה סילוגיסטית,
אבל מעבר לדוגמא הצרה של ההיגיון, מה ניתן לומר על איך לבנות באופן שיטתי (או לזהות) אפילו טקסט בעל משמעות מתקבלת על הדעת? כן, יש דברים כמו Mad Libs שמשתמשים ב"תבניות ביטוי" מאוד ספציפיות. אבל איכשהו ל-ChatGPT יש באופן מרומז דרך הרבה יותר כללית לעשות את זה. ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
-
@NH-LOCAL כתב בצאט AI | מודל שפה!:
@nigun אפשר קישור?
אני רואה שהקישור שבור
זה מה שהובא באשכול הקודם
https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/ -
הנה עוד קטע מהמאמר הנ"ל
מה באמת מאפשר ל-ChatGPT לעבוד?
השפה האנושית - ותהליכי החשיבה הכרוכים ביצירתה - תמיד נראו כמעין שיא של מורכבות. ואכן זה נראה קצת מדהים שמוחות אנושיים - עם הרשת שלהם של "רק" 100 מיליארד נוירונים בערך (ואולי 100 טריליון קשרים) יכולים להיות אחראים לכך. אולי, אפשר היה לדמיין, יש משהו יותר במוח מאשר רשתות הנוירונים שלהם - כמו איזו שכבה חדשה של פיזיקה שלא התגלתה. אבל עכשיו עם ChatGPT יש לנו פיסת מידע חדשה וחשובה: אנחנו יודעים שרשת עצבית טהורה ומלאכותית עם קשרים רבים כמו למוח שיש לנו נוירונים מסוגלת לעשות עבודה טובה באופן מפתיע לייצר שפה אנושית.וכן, זו עדיין מערכת גדולה ומסובכת - עם משקלים עצביים רבים בערך כמו שיש מילות טקסט הזמינות כיום בעולם. אבל ברמה מסוימת עדיין נראה שקשה להאמין שכל העושר של השפה והדברים שהיא יכולה לדבר עליהם יכולים להיות מובלעים במערכת כה סופית. חלק ממה שקורה הוא ללא ספק השתקפות של התופעה בכל מקום (שהתבררה לראשונה בדוגמה של כלל 30) שתהליכי חישוב יכולים למעשה להגביר מאוד את המורכבות הנראית לעין של מערכות גם כאשר הכללים הבסיסיים שלהן פשוטים. אבל למעשה, כפי שדיברנו לעיל, רשתות עצביות מהסוג המשמש ב-ChatGPT נוטות להיבנות באופן ספציפי כדי להגביל את ההשפעה של תופעה זו - וחוסר ההפחתה החישובית הקשורה אליה - מתוך אינטרס להפוך את האימון שלהן לנגיש יותר.
אז איך זה, אם כן, שמשהו כמו ChatGPT יכול להגיע עד כמה שהוא מגיע עם השפה? התשובה הבסיסית, אני חושב, היא שהשפה היא ברמה בסיסית איכשהו פשוטה יותר ממה שהיא נראית. וזה אומר ש-ChatGPT - אפילו עם מבנה הרשת העצבית הפשוט בסופו של דבר - מסוגל "ללכוד את המהות" של השפה האנושית והחשיבה שמאחוריה. ויותר מכך, בהכשרתה, ChatGPT איכשהו "גילתה באופן מרומז" את כל הקביעות בשפה (ובחשיבה) שמאפשרות זאת.
הצלחתו של ChatGPT היא, לדעתי, נותנת לנו עדות לפיסת מדע בסיסית וחשובה: היא מעידה על כך שאנו יכולים לצפות שיהיו "חוקי השפה" חדשים עיקריים - ולמעשה "חוקי המחשבה" - כדי לגלות שם. . ב-ChatGPT - שנבנה כפי שהוא כרשת עצבית - החוקים האלה הם לכל היותר מרומזים. אבל אם נוכל איכשהו להבהיר את החוקים, יש פוטנציאל לעשות את הדברים ש-ChatGPT עושה בדרכים הרבה יותר ישירות, יעילות ושקופות.
אבל, בסדר, אז איך החוקים האלה עשויים להיות? בסופו של דבר הם חייבים לתת לנו איזשהו מרשם לאופן שבו השפה - והדברים שאנו אומרים איתה - מורכבים יחד. מאוחר יותר נדון כיצד "הסתכלות בתוך ChatGPT" עשויה לתת לנו כמה רמזים על כך, וכיצד מה שאנו יודעים מבניית שפת חישוב מעיד על דרך קדימה. אבל תחילה בואו נדון בשתי דוגמאות ידועות ארוכות של מה שמסתכם ב"חוקי השפה" - וכיצד הם קשורים לפעולה של ChatGPT.
הראשון הוא תחביר השפה. שפה היא לא רק ערבוביה אקראית של מילים. במקום זאת, ישנם כללים דקדוקיים מוגדרים (די) לאופן שבו ניתן לחבר מילים מסוגים שונים: באנגלית, למשל, שמות עצם יכולים להיות מקדימים שמות תואר ואחריהם פעלים, אבל בדרך כלל שני שמות עצם לא יכולים להיות ממש ליד כל אחד מהם. אַחֵר. מבנה דקדוקי כזה יכול (לפחות בקירוב) להיתפס על ידי מערכת כללים המגדירים כיצד ניתן להרכיב איזו כמות ל"נתח עצים" :
ל-ChatGPT אין "ידע" מפורש על כללים כאלה. אבל איכשהו באימון שלו הוא "מגלה" אותם במרומז - ואז נראה שהוא טוב במעקב אחריהם. אז איך זה עובד? ברמת "תמונה גדולה" זה לא ברור. אבל כדי לקבל קצת תובנות זה אולי מאלף להסתכל על דוגמה הרבה יותר פשוטה.
שקול "שפה" שנוצרה מרצפים של סוגריים דהיינו התווים () עם דקדוק המציין שסוגריים תמיד צריכים להיות מאוזנים, כפי שמיוצג על ידי עץ ניתוח כמו:
האם נוכל לאמן רשת עצבית לייצר רצפי סוגריים "נכונים מבחינה דקדוקית"? ישנן דרכים שונות לטפל ברצפים ברשתות עצביות, אבל בואו נשתמש ברשתות שנאים, כפי שעושה ChatGPT. ובהינתן רשת transformer פשוטה, נוכל להתחיל להזין אותה ברצפי סוגריים נכונים מבחינה דקדוקית כדוגמאות אימון. עדינות (שלמעשה מופיעה גם בדור השפה האנושית של ChatGPT) היא שבנוסף ל"אסימוני התוכן" שלנו (כאן "(" ו")") עלינו לכלול אסימון "סוף", שנוצר כדי לציין שה- הפלט לא אמור להמשיך יותר (כלומר עבור ChatGPT, זה הגיע ל"סוף הסיפור").
אם נקים רשת transformer עם רק בלוק קשב אחד עם 8 ראשים ווקטורי תכונה באורך 128 (ChatGPT משתמש גם בוקטורי תכונה באורך 128, אבל יש לו 96 בלוקי קשב, כל אחד עם 96 ראשים), אז לא נראה שאפשר להביא אותו ללמוד הרבה על שפת סוגריים. אבל עם 2 בלוקים של קשב, נראה שתהליך הלמידה מתכנס - לפחות לאחר שניתנו 10 מיליון דוגמאות לערך (וכפי שמקובל ברשתות transformer, הצגת דוגמאות נוספות נראה רק פוגעת בביצועים שלה).
אז עם הרשת הזו, אנחנו יכולים לעשות את האנלוגי של מה ש-ChatGPT עושה, ולבקש הסתברויות מה צריך להיות האסימון הבא - ברצף של סוגריים:
ובמקרה הראשון, הרשת "די בטוחה" שהרצף לא יכול להסתיים כאן - וזה טוב, כי אם כן, הסוגריים היו נותרים לא מאוזנים. אולם במקרה השני, הוא "מזהה נכון" שהרצף יכול להסתיים כאן, אם כי הוא גם "מציין" שאפשר "להתחיל מחדש", לשים ")", ככל הנראה עם "(" שאחריו. . אבל, אופס, אפילו עם כ-400,000 המשקולות שאומנו בעמל רב, זה אומר שיש סבירות של 15% לקבל "(" בתור האסימון הבא - וזה לא נכון, כי זה בהכרח יוביל לסוגריים לא מאוזנים.
זה מה שנקבל אם נבקש מהרשת את ההשלמות בעלות ההסתברות הגבוהה ביותר עבור רצפים ארוכים יותר ויותר של ) :
וכן, עד אורך מסוים הרשת מסתדרת מצוין. אבל אז זה מתחיל להיכשל. זה סוג די אופייני לראות במצב "מדויק" כזה עם רשת עצבית (או עם למידת מכונה באופן כללי). מקרים שאדם "יכול לפתור במבט חטוף" גם הרשת העצבית יכולה לפתור. אבל מקרים הדורשים לעשות משהו "אלגוריתמי יותר" (למשל ספירה מפורשת של סוגריים כדי לראות אם הם סגורים) הרשת העצבית נוטה איכשהו להיות "רדודה מדי מבחינה חישובית" מכדי לעשות זאת בצורה מהימנה. (אגב, אפילו ChatGPT הנוכחי המלא מתקשה להתאים נכון סוגריים ברצפים ארוכים.)
אז מה זה אומר לגבי דברים כמו ChatGPT והתחביר של שפה כמו אנגלית? שפת הסוגריים היא "מחמירה" - והרבה יותר "סיפור אלגוריתמי". אבל באנגלית זה הרבה יותר ריאלי להיות מסוגל "לנחש" מה יתאים מבחינה דקדוקית על סמך בחירות מקומיות של מילים ורמזים אחרים. וכן, הרשת העצבית הרבה יותר טובה בזה - למרות שאולי היא עשויה להחמיץ מקרה "נכון פורמלית" שגם בני אדם עלולים לפספס. אבל הנקודה העיקרית היא שהעובדה שיש מבנה תחבירי כולל לשפה - עם כל הסדירות שמשתמעת מכך - מגבילה במובן מסוים "כמה" לרשת העצבית צריכה ללמוד.
תחביר מספק סוג אחד של אילוץ על השפה. אבל ברור שיש עוד. משפט כמו "אלקטרונים סקרנים אוכלים תיאוריות כחולות לדגים" הוא נכון מבחינה דקדוקית אבל הוא לא משהו שבדרך כלל היה מצפים לומר, ולא ייחשב להצלחה אם ChatGPT ייצר אותו - כי, ובכן, עם המשמעויות הרגילות עבור מילים בו, זה בעצם חסר משמעות.
אבל האם יש דרך כללית לדעת אם יש משמעות למשפט? אין תיאוריה כללית מסורתית לכך. אבל זה משהו שאפשר לחשוב על ChatGPT כמי ש"פיתח עבורו תיאוריה" באופן מרומז לאחר שעבר הכשרה עם מיליארדי משפטים (כנראה בעלי משמעות) מהאינטרנט וכו'.
איך יכולה להיות התיאוריה הזו? ובכן, יש פינה אחת קטנטנה שבעצם ידועה כבר אלפיים שנה, וזה היגיון. ובוודאי בצורה הסילוגיסטית שבה גילה זאת אריסטו, ההיגיון הוא בעצם דרך לומר שמשפטים העוקבים אחר דפוסים מסוימים הם סבירים, בעוד שאחרים לא. כך, למשל, סביר לומר "כל ה-X הם Y. זה לא Y, אז זה לא X" (כמו ב"כל הדגים כחולים. זה לא כחול, אז זה לא דג"). וכמו שאפשר לדמיין בצורה קצת גחמנית שאריסטו גילה את ההיגיון הסילוגיסטי על ידי מעבר ("סגנון למידה מכונה") על המון דוגמאות של רטוריקה, כך גם אפשר לדמיין שבאימונים של ChatGPT הוא היה מסוגל "לגלות היגיון סילוגיסטי" על ידי הסתכלות על הרבה טקסט באינטרנט וכו'. (וכן, בעוד שניתן לצפות מ-ChatGPT לייצר טקסט שמכיל "מסקנות נכונות" על סמך דברים כמו לוגיקה סילוגיסטית,
אבל מעבר לדוגמא הצרה של ההיגיון, מה ניתן לומר על איך לבנות באופן שיטתי (או לזהות) אפילו טקסט בעל משמעות מתקבלת על הדעת? כן, יש דברים כמו Mad Libs שמשתמשים ב"תבניות ביטוי" מאוד ספציפיות. אבל איכשהו ל-ChatGPT יש באופן מרומז דרך הרבה יותר כללית לעשות את זה. ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
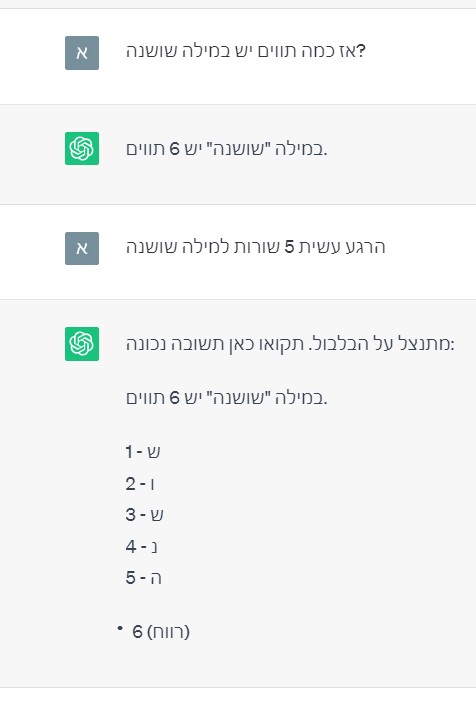
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימת -
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימת@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימתהוא אומר שכשאתה מחשב הסתברות ע"פ 175B נוצר כאן הגיון שאנחנו לא יכולים להבין, אבל המודל נשאר אותו דבר כמו המודל של 100K פרמטרים, הוא מחשב באותה שיטת הסתברות.
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת.מייל: nigun@duck.com
-
@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימתהוא אומר שכשאתה מחשב הסתברות ע"פ 175B נוצר כאן הגיון שאנחנו לא יכולים להבין, אבל המודל נשאר אותו דבר כמו המודל של 100K פרמטרים, הוא מחשב באותה שיטת הסתברות.
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת. -
@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימתהוא אומר שכשאתה מחשב הסתברות ע"פ 175B נוצר כאן הגיון שאנחנו לא יכולים להבין, אבל המודל נשאר אותו דבר כמו המודל של 100K פרמטרים, הוא מחשב באותה שיטת הסתברות.
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת. -
@nigun כתב בצאט AI | מודל שפה!:
נוצר כאן הגיון שאנחנו לא יכולים להבין,
על זה אני מדבר...
מודל של 100K לא היה יוצר את ההיגיון הזה ורק במודל גדול יותר נוצר היגיון שא"א להסביר... אז גם א"א לסתור כל הסבר...@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
נוצר כאן הגיון שאנחנו לא יכולים להבין,
על זה אני מדבר...
מודל של 100K לא היה יוצר את ההיגיון הזה ורק במודל גדול יותר נוצר היגיון שא"א להסביר... אז גם א"א לסתור כל הסבר...אבל השיטה אותה שיטה, לחשב בהסתברות מה המילה הבאה.
ולכן אי אפשר לספור תווים, כי ההסתברות שהמילה הבאה אחרי המשפט "כמה מילים יש במסמך הזה?" היא 100 דומה מאוד להסתברות שהמיל הבאה היא 101.
למודל אין "שכל" ללכת ו"לספור" את המילים הוא סך הכל מנסה לנחש את המילה הבאה.
(אפשר לחבר אותו לתוכנה שיודעת לספור ואז בהסתברות גבוהה הוא יכתוב "הפעל תוכנה X" ואז התוכנה תופעל ע"י המחשב שמריץ את המודל, אבל המודל נשאר אותו מודל שיודע רק לחשב מה מסתבר שיהיה המילה הבאה) -
@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
נוצר כאן הגיון שאנחנו לא יכולים להבין,
על זה אני מדבר...
מודל של 100K לא היה יוצר את ההיגיון הזה ורק במודל גדול יותר נוצר היגיון שא"א להסביר... אז גם א"א לסתור כל הסבר...אבל השיטה אותה שיטה, לחשב בהסתברות מה המילה הבאה.
ולכן אי אפשר לספור תווים, כי ההסתברות שהמילה הבאה אחרי המשפט "כמה מילים יש במסמך הזה?" היא 100 דומה מאוד להסתברות שהמיל הבאה היא 101.
למודל אין "שכל" ללכת ו"לספור" את המילים הוא סך הכל מנסה לנחש את המילה הבאה.
(אפשר לחבר אותו לתוכנה שיודעת לספור ואז בהסתברות גבוהה הוא יכתוב "הפעל תוכנה X" ואז התוכנה תופעל ע"י המחשב שמריץ את המודל, אבל המודל נשאר אותו מודל שיודע רק לחשב מה מסתבר שיהיה המילה הבאה)@nigun כתב בצאט AI | מודל שפה!:
אבל השיטה אותה שיטה, לחשב בהסתברות מה המילה הבאה.
אם השיטה היא אותה שיטה התוצאות חייבות להיות שוות.
אז זה נכון שבבסיס הוא מושתת על אותו ההליך אבל הוא חייב להשתנות באמצע וכפי שכבר כתבו שבשלב מסויים הוא רוכש היגיון לא מוסבר.
כבר כתבו שהבינה היא קופסה שחורה לא מובנת, לכן נשמע לי קצת מגוחך שאנחנו מתווכחים מה היא... -
@nigun כתב בצאט AI | מודל שפה!:
אבל השיטה אותה שיטה, לחשב בהסתברות מה המילה הבאה.
אם השיטה היא אותה שיטה התוצאות חייבות להיות שוות.
אז זה נכון שבבסיס הוא מושתת על אותו ההליך אבל הוא חייב להשתנות באמצע וכפי שכבר כתבו שבשלב מסויים הוא רוכש היגיון לא מוסבר.
כבר כתבו שהבינה היא קופסה שחורה לא מובנת, לכן נשמע לי קצת מגוחך שאנחנו מתווכחים מה היא...@one1010 כתב בצאט AI | מודל שפה!:
אם השיטה היא אותה שיטה התוצאות חייבות להיות שוות.
אז זה נכון שבבסיס הוא מושתת על אותו ההליך אבל הוא חייב להשתנות באמצע וכפי שכבר כתבו שבשלב מסויים הוא רוכש היגיון לא מוסבר.ההגיון הוא שיש משהו מבני בשפת של בני אדם וניתן לחשב מה המשפט הנכון לומר ע"פ הסתברות, מה שעדיין נחשב קופסה שחורה היא איך נוצרים מבנים כאלו שיוצרים מודל כזה חכם, אבל מה שברור הוא שלא ניתן לצפות ממנו לספור תווים כי עם כל הכבוד למבנה שיש בשפת של בני אדם הוא לא "קרא" מספיק טקסט שבו כתוב "במסמך זה יש 300 מילים ו1650 תווים" כדי שייוצר המבנה הזה במודל ההסתברותי וגם אם הוא יאומן על ספירת מילים הוא לא ידע לענות על שאלות בחשבון כי כשמנסים לחשב מה המילה הבאה בהסתברות קשה לענות על שאלות מורכבות בחשבון (וגם אם היה נוצר מבנה שהיה מצליח לענות על שאלות בחשבון זה לא יעיל ועדיף לפתור את זה בדרך הטובה והישנה והמדוייקת)
-
@one1010 כתב בצאט AI | מודל שפה!:
אם השיטה היא אותה שיטה התוצאות חייבות להיות שוות.
אז זה נכון שבבסיס הוא מושתת על אותו ההליך אבל הוא חייב להשתנות באמצע וכפי שכבר כתבו שבשלב מסויים הוא רוכש היגיון לא מוסבר.ההגיון הוא שיש משהו מבני בשפת של בני אדם וניתן לחשב מה המשפט הנכון לומר ע"פ הסתברות, מה שעדיין נחשב קופסה שחורה היא איך נוצרים מבנים כאלו שיוצרים מודל כזה חכם, אבל מה שברור הוא שלא ניתן לצפות ממנו לספור תווים כי עם כל הכבוד למבנה שיש בשפת של בני אדם הוא לא "קרא" מספיק טקסט שבו כתוב "במסמך זה יש 300 מילים ו1650 תווים" כדי שייוצר המבנה הזה במודל ההסתברותי וגם אם הוא יאומן על ספירת מילים הוא לא ידע לענות על שאלות בחשבון כי כשמנסים לחשב מה המילה הבאה בהסתברות קשה לענות על שאלות מורכבות בחשבון (וגם אם היה נוצר מבנה שהיה מצליח לענות על שאלות בחשבון זה לא יעיל ועדיף לפתור את זה בדרך הטובה והישנה והמדוייקת)
-
@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימתהוא אומר שכשאתה מחשב הסתברות ע"פ 175B נוצר כאן הגיון שאנחנו לא יכולים להבין, אבל המודל נשאר אותו דבר כמו המודל של 100K פרמטרים, הוא מחשב באותה שיטת הסתברות.
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת. -
O one1010 התייחס לנושא זה ב
-
@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
ואולי אין מה לומר על איך זה יכול להיעשות מעבר ל"איכשהו זה קורה כשיש לך 175 מיליארד משקלים נטו עצביים". אבל אני חושד מאוד שיש סיפור הרבה יותר פשוט וחזק.
זה בקיצור הטענה שלי...
הוא גם טוען שמעבר להסתברות יש תוספת של היגיון שהוא לא יודע להסביר אבל היא קימתהוא אומר שכשאתה מחשב הסתברות ע"פ 175B נוצר כאן הגיון שאנחנו לא יכולים להבין, אבל המודל נשאר אותו דבר כמו המודל של 100K פרמטרים, הוא מחשב באותה שיטת הסתברות.
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת.@nigun כתב בצאט AI | מודל שפה!:
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת.
האם ההתקדמות הבאה סותרת את הדברים שכתבת? :
"עכשיו גוגל כבר פותרת לכם תרגילים במתמטיקה, פיזיקה וגיאומטריה"
https://www.geektime.co.il/google-search-in-lens-can-now-help-with-math-and-science-problems/ -
@nigun כתב בצאט AI | מודל שפה!:
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת.
האם ההתקדמות הבאה סותרת את הדברים שכתבת? :
"עכשיו גוגל כבר פותרת לכם תרגילים במתמטיקה, פיזיקה וגיאומטריה"
https://www.geektime.co.il/google-search-in-lens-can-now-help-with-math-and-science-problems/@one1010 כתב בצאט AI | מודל שפה!:
@nigun כתב בצאט AI | מודל שפה!:
ולכן אי אפשר לצפות שיעשה פעולות שדורשות חשיבה מסוג של בני אדם כמו לספור תווים או לעשות פעולה חשבונית מסובכת.
האם ההתקדמות הבאה סותרת את הדברים שכתבת? :
"עכשיו גוגל כבר פותרת לכם תרגילים במתמטיקה, פיזיקה וגיאומטריה"
https://www.geektime.co.il/google-search-in-lens-can-now-help-with-math-and-science-problems/היום רוב המודלים המשוכללים משלבים כמה מודלים ביחד וכדו'
למשל בבינג אפשר לבקש תמונה והוא מפנה את הפרומפט ליצירת תמונה עם המודל של DELL-E או מבצע חיפוש במנוע החיפוש הרגיל של בינג.
סביר להניח שגוגל עשו משהו דומה ושילבו מחשבון רגיל והמודל מאמון להפעיל את המחשבון ולא לנסות לפתור את התרגיל לבד.
לא ידוע על לי על תאוריה מדעית איך LLM יצליח לפתור תרגילים מתמטיים בלי עזרה של מחשבון קונבנציונלי חיצוני.מייל: nigun@duck.com