
sql - תכנון יצירת טבלאות
-
אשמח להתייעץ בנוגע לתכנון טבלאות בSQL
מה מומלץ לבצע בטבלה שבטווח של עשר שנים לא אמורה להכיל יותר מ100,000 שורות
-
מבחינת קריאות
-
מיטוב ביצועים
-
(ופשטות יצירת שאילתות)
כידוע ה'כלל אצבע' במסדי נתונים
הינו להימנע מהזנת נתון כפול ולבצע שימוש ב'מפתח זר'שאלה:
- במידה ויש לי הרבה נתונים ייחודיים אבל אינם מוכרחים להיות בטבלה הנוכחית
האם יותר נכון להוסיף עמודות לפי הצורך (כולל עמודות עם שדה ntext / nvarchar(4000) )
או בכ"ז לפצל לטבלאות נפרדות
לדוגמא:

יש לי אפשרות לשמור את כל הנתונים הללו בטבלה אחת וזה תקין,
כי זה מידע ייחודי
מצד שני ניתן לפצל את העמודות של הכמות שסופקה והערות לטבלה נפרדת
(עמודה תאריך אספקה משמש גם לביצוע פילטור האם סופק)- במידה ויש נתון 'כפול' שניתן להשיגו באמצעות מפתח זר הקיים בטבלה נוכחית
אבל זה נתון 'רזה' מסוג nvarchar(30)
האם 'שווה' להוסיף את העמודה בכדי לחסוך את הjoin בשאילתות
עריכה: דוגמא
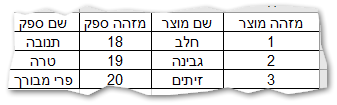
למעשה המזהה ספק ושם הספק הינו נתון כפול
כי ניתן לשלוף את שם הספק באמצעות JOIN לטבלת ספקים
מצד שני - שם הספק הינו שדה 'רזה' -
-
אשמח להתייעץ בנוגע לתכנון טבלאות בSQL
מה מומלץ לבצע בטבלה שבטווח של עשר שנים לא אמורה להכיל יותר מ100,000 שורות
-
מבחינת קריאות
-
מיטוב ביצועים
-
(ופשטות יצירת שאילתות)
כידוע ה'כלל אצבע' במסדי נתונים
הינו להימנע מהזנת נתון כפול ולבצע שימוש ב'מפתח זר'שאלה:
- במידה ויש לי הרבה נתונים ייחודיים אבל אינם מוכרחים להיות בטבלה הנוכחית
האם יותר נכון להוסיף עמודות לפי הצורך (כולל עמודות עם שדה ntext / nvarchar(4000) )
או בכ"ז לפצל לטבלאות נפרדות
לדוגמא:
יש לי אפשרות לשמור את כל הנתונים הללו בטבלה אחת וזה תקין,
כי זה מידע ייחודי
מצד שני ניתן לפצל את העמודות של הכמות שסופקה והערות לטבלה נפרדת
(עמודה תאריך אספקה משמש גם לביצוע פילטור האם סופק)- במידה ויש נתון 'כפול' שניתן להשיגו באמצעות מפתח זר הקיים בטבלה נוכחית
אבל זה נתון 'רזה' מסוג nvarchar(30)
האם 'שווה' להוסיף את העמודה בכדי לחסוך את הjoin בשאילתות
עריכה: דוגמא
למעשה המזהה ספק ושם הספק הינו נתון כפול
כי ניתן לשלוף את שם הספק באמצעות JOIN לטבלת ספקים
מצד שני - שם הספק הינו שדה 'רזה'@mekev איינשטין אמר פעם: "תעשה הכל הכי פשוט שאפשר, אבל לא יותר פשוט מזה".
מה זה אומר?
כפי הנראה מהנתונים שהבאת בדוגמא, טבלה אחת מספיקה במקרה הזה, והיא מקיימת את תנאי הנירמול שציינת.
כשהטבלה הופכת כבר לא פשוטה לתחזוק, למשל יש 10 שדות עבור הכתובת (ישוב, רחוב, מספר בית, 3 טלפונים, פקס, מייל וכו') אז הזמן לחשוב להפריד את הנתונים הללו אל טבלה נפרדת עם קשר חד-חד ערכי. -
-
@mekev איינשטין אמר פעם: "תעשה הכל הכי פשוט שאפשר, אבל לא יותר פשוט מזה".
מה זה אומר?
כפי הנראה מהנתונים שהבאת בדוגמא, טבלה אחת מספיקה במקרה הזה, והיא מקיימת את תנאי הנירמול שציינת.
כשהטבלה הופכת כבר לא פשוטה לתחזוק, למשל יש 10 שדות עבור הכתובת (ישוב, רחוב, מספר בית, 3 טלפונים, פקס, מייל וכו') אז הזמן לחשוב להפריד את הנתונים הללו אל טבלה נפרדת עם קשר חד-חד ערכי. -
אשמח להתייעץ בנוגע לתכנון טבלאות בSQL
מה מומלץ לבצע בטבלה שבטווח של עשר שנים לא אמורה להכיל יותר מ100,000 שורות
-
מבחינת קריאות
-
מיטוב ביצועים
-
(ופשטות יצירת שאילתות)
כידוע ה'כלל אצבע' במסדי נתונים
הינו להימנע מהזנת נתון כפול ולבצע שימוש ב'מפתח זר'שאלה:
- במידה ויש לי הרבה נתונים ייחודיים אבל אינם מוכרחים להיות בטבלה הנוכחית
האם יותר נכון להוסיף עמודות לפי הצורך (כולל עמודות עם שדה ntext / nvarchar(4000) )
או בכ"ז לפצל לטבלאות נפרדות
לדוגמא:
יש לי אפשרות לשמור את כל הנתונים הללו בטבלה אחת וזה תקין,
כי זה מידע ייחודי
מצד שני ניתן לפצל את העמודות של הכמות שסופקה והערות לטבלה נפרדת
(עמודה תאריך אספקה משמש גם לביצוע פילטור האם סופק)- במידה ויש נתון 'כפול' שניתן להשיגו באמצעות מפתח זר הקיים בטבלה נוכחית
אבל זה נתון 'רזה' מסוג nvarchar(30)
האם 'שווה' להוסיף את העמודה בכדי לחסוך את הjoin בשאילתות
עריכה: דוגמא
למעשה המזהה ספק ושם הספק הינו נתון כפול
כי ניתן לשלוף את שם הספק באמצעות JOIN לטבלת ספקים
מצד שני - שם הספק הינו שדה 'רזה'@mekev כתב בsql - תכנון יצירת טבלאות:
במידה ויש נתון 'כפול' שניתן להשיגו באמצעות מפתח זר הקיים בטבלה נוכחית
אבל זה נתון 'רזה' מסוג nvarchar(30)
האם 'שווה' להוסיף את העמודה בכדי לחסוך את הjoin בשאילתותעריכה: דוגמא
למעשה המזהה ספק ושם הספק הינו נתון כפול
כי ניתן לשלוף את שם הספק באמצעות JOIN לטבלת ספקים
מצד שני - שם הספק הינו שדה 'רזה'אני חושב שמקובל לעשות טבלה נפרדת של ספקים.
שים לב שבצורה הזאת, אם תרצה לשנות שם ספק, תצטרך לעדכן אותו בשני מקומות... זה תופעת לוואי שאומרת שהנתון לא אמור להיות כפול. -
-
אשמח להתייעץ בנוגע לתכנון טבלאות בSQL
מה מומלץ לבצע בטבלה שבטווח של עשר שנים לא אמורה להכיל יותר מ100,000 שורות
-
מבחינת קריאות
-
מיטוב ביצועים
-
(ופשטות יצירת שאילתות)
כידוע ה'כלל אצבע' במסדי נתונים
הינו להימנע מהזנת נתון כפול ולבצע שימוש ב'מפתח זר'שאלה:
- במידה ויש לי הרבה נתונים ייחודיים אבל אינם מוכרחים להיות בטבלה הנוכחית
האם יותר נכון להוסיף עמודות לפי הצורך (כולל עמודות עם שדה ntext / nvarchar(4000) )
או בכ"ז לפצל לטבלאות נפרדות
לדוגמא:
יש לי אפשרות לשמור את כל הנתונים הללו בטבלה אחת וזה תקין,
כי זה מידע ייחודי
מצד שני ניתן לפצל את העמודות של הכמות שסופקה והערות לטבלה נפרדת
(עמודה תאריך אספקה משמש גם לביצוע פילטור האם סופק)- במידה ויש נתון 'כפול' שניתן להשיגו באמצעות מפתח זר הקיים בטבלה נוכחית
אבל זה נתון 'רזה' מסוג nvarchar(30)
האם 'שווה' להוסיף את העמודה בכדי לחסוך את הjoin בשאילתות
עריכה: דוגמא
למעשה המזהה ספק ושם הספק הינו נתון כפול
כי ניתן לשלוף את שם הספק באמצעות JOIN לטבלת ספקים
מצד שני - שם הספק הינו שדה 'רזה'@mekev לא ברור מהו סוג המידע שהטבלה מייצגת.
אם הטבלה מייצגת משלוחים (כל רקורד מייצג משלוח בודד) סביר להניח שכמות שסופקה מייצג נתון שקשור באופן אינטרגרלי למשלוח.
ספקים - טבלה נפרדת.
מוצרים - טבלה נפרדת.אם הטבלה מייצגת משלוח של סוג מוצר מסויים (משלוח מכיל מספר מרובה של סוגי מוצרים) סביר למקם את כמות שסופקה באותה טבלה.
משלוחים - טבלה נפרדת.
-
-
@mekev לא ברור מהו סוג המידע שהטבלה מייצגת.
אם הטבלה מייצגת משלוחים (כל רקורד מייצג משלוח בודד) סביר להניח שכמות שסופקה מייצג נתון שקשור באופן אינטרגרלי למשלוח.
ספקים - טבלה נפרדת.
מוצרים - טבלה נפרדת.אם הטבלה מייצגת משלוח של סוג מוצר מסויים (משלוח מכיל מספר מרובה של סוגי מוצרים) סביר למקם את כמות שסופקה באותה טבלה.
משלוחים - טבלה נפרדת.
אביא דוגמא פרטנית המייצגת את נקודת השאלה
(מדגיש דוגמא, כי גם בדוגמא יש הרבה יותר רכיבים בשרת האמורים להיות בטבלה
וגם אצלי כך שהסברא זה סהכ 10 עמודות ולא נורא אינה אקטואלית)מעבדת מחשבים המוכרת 'שרתים' בהרכבה אישית (כל חלק מוזמן פרטנית ולא מהמלאי)
הטבלה הדומיננטית הינה טבלת השרתים שנמכרו
טבלת הבסיס הינה:

בצד לקוח יוצג:

כעת השאלה
מה לעשות אם הנתונים הנוספים היחודיים למוצר אבל אינם מוכרחים להיות בטבלה זו
דוגמא לנתונים נוספים (לכל רכיב בנפרד!!!!)

האם כדאי להוסיף אותם לטבלת שרתים
או לעשות לזה טבלת משנההנקודות שאשמח להתייחסות
בהנתן שבוודאות בטווח של עשר שנים לא אעבור את ה100,000 שורותמה עדיף עבורי (יותר נכון - מה אתה היית עושה)
-
מבחינת קריאות
-
מיטוב ביצועים
-
(ופשטות יצירת שאילתות)
-
-
אביא דוגמא פרטנית המייצגת את נקודת השאלה
(מדגיש דוגמא, כי גם בדוגמא יש הרבה יותר רכיבים בשרת האמורים להיות בטבלה
וגם אצלי כך שהסברא זה סהכ 10 עמודות ולא נורא אינה אקטואלית)מעבדת מחשבים המוכרת 'שרתים' בהרכבה אישית (כל חלק מוזמן פרטנית ולא מהמלאי)
הטבלה הדומיננטית הינה טבלת השרתים שנמכרו
טבלת הבסיס הינה:
בצד לקוח יוצג:
כעת השאלה
מה לעשות אם הנתונים הנוספים היחודיים למוצר אבל אינם מוכרחים להיות בטבלה זו
דוגמא לנתונים נוספים (לכל רכיב בנפרד!!!!)
האם כדאי להוסיף אותם לטבלת שרתים
או לעשות לזה טבלת משנההנקודות שאשמח להתייחסות
בהנתן שבוודאות בטווח של עשר שנים לא אעבור את ה100,000 שורותמה עדיף עבורי (יותר נכון - מה אתה היית עושה)
-
מבחינת קריאות
-
מיטוב ביצועים
-
(ופשטות יצירת שאילתות)
@mekev מה שמקובל לעשות בכזה מקרה זה EAV
זה לפעמים קצת מורכב, בעיקר הקושי של יצירת שאילתות כנראה.
ככל שמה שאתה צריך לתשאל (במשפט WHERE) ולא להביא את כל הנתונים בתצוגה שטוחה, אני חושב שכמעט אין הבדל.
אם הצורך הוא להציג הרבה עמודות וכו' ולשלוף אותם בתצוגה שטוחה, לא בטוח שזה יהיה קל.
אבל זה יהיה תלוי בעיקר באיזה פלטפורמה אתה משתמש, בORM אולי זה יהיה יותר קשה, אם אתה בונה את השאילתות SQL שלך לבד אז לפעמים אולי יהיה יותר קל.אפשרות נוספת זה לשים שדה טקסט לא מוגבל ולאכסן בו אובייקט JSON דינאמי.
היום בSQL אפשר לתשאל ולעדכן גם אובייקט JSON פנימי בתוך עמודה -
-
גם השאלה וגם התשובות לא מספיק הבחינו בין מקרים.
אתה דיברת בשאלה ובהבהרות ההמשך שלה על כמה מקרים:- שדות כפולים לחיסכון JOIN, כלומר האם לגיטימי לשמור עותק של נתון בטבלה א' כדי להימנע מJOIN על כל צעד ושעל לטבלה ב'.
- שדות רבים של אותה ישות (קשר יחיד ליחיד) שתמיד בשימוש, ומתעורר צורך בפיצול רק בגלל גודלה של הטבלה, או בגלל הבדל מהותי במהות הפרטים הללו.
- כנ"ל, אבל שלא קיימים עבור כל ישות. למשל פרטי חשבון בנק, שלכל המשלמים באשראי יש בכלל פרטי אשראי. אז ישנם פרטי בנק ואשראי בקשר יחיד ליחיד לטבלת האנשים (יש מצב נדיר שיש שני ח-ן לאדם ולהיפך, אבל אני מתעלם מכך כעת).
- שדות דינמיים, כלומר שגם אחרי שהמוצר יהיה מושלם, יהיה צורך בשינויים (עריכה/הוספה/מחיקה של שדות) כשגרת השימוש במערכת.
1. מידע כפול לחיסכון בJOIN
לא לגיטימי כלל במסד נתונים רלציוני, ובשביל ביצועים יש לשנות מהלגיטימציה רק במקרי קיצון.
2. פיצול טבלה מרובת שדות לשני טבלאות עם קשר יחיד ליחיד
יש לעיתים הגיון בפיצול טבלה לשניים למרות שהשדות תמיד בשימוש ותמיד קשר של יחיד ליחיד. למשל אם אתה נוהג להשתמש ב* בחלק מהשאילתות שלך, שדות רבים שלא בשימוש שגרתי הם מכבידים על תוצאות השאילתה. כמו כן זה מיקל קצת על הבנת השדות, כי אפשר לקרוא להם בשמות קצרים יותר ("סניף" בטבת חשבונות בנק, יותר קל מאשר "סניף חשבון" וכדומה בטבלת האנשים).
עצם העובדה שיש כבר 150 שדות בטבלה זה לא עילה לדעתי לפצל טבלה.3. פיצול קבוצות של מידע אופציונלי מהטבלה
בעצם זה אותו מקרה של 2, רק שיש פה שני ייתרונות נוספים אפשריים
- מקום. שדות רבים ריקים תיאורטית לוקחים מקום, ומעשית יש להם עלות ביצועית למסד הנתונים. במקרה כזה הטבלה החדשה היא מה 0..1-1 כלומר לא לכל שורה יש שורה תאומה.
- מהות - נח בפיתוח ובתחזוקה להבין שקבוצת שדות מסויימת היא נושא מסויים.
- בדרך כלל זה בעצם ישויות נפרדות. למשל פרטי חשבון בנק זה לא תכונות של אדם אלא ישות שקוראים לה חשבון בנק. המציאות היא שישויות נפרדות יכולות בהמשך להפוך לרבים ליחיד או יחיד לרבים.
4. פיצול טבלה כדי להפריד שדות דינמיים משדות קבועים
אם התוכנה בנויה באופן שהיא עצמה יכולה להוסיף שדות/תכונות לישות, בהחלט מתבקש להפריד את זה מהטבלה שמחזיקה את נתוני הליבה. כמו"כ בגלל הרבה בעיות וקשיים בתחזוקת כזה דבר, וגם בגלל שעריכת מסד נתונים בזמן ייצור זה לא אמור להיות שגרה ברוכה, לכן מתבקש הפתרון של @clickone שזה EAV.
-
M mekev התייחס לנושא זה ב